一、前言
图像拼接技术就是将数张有重叠部分的图像(可能是不同时间、不同视角或者不同传感器获得的)拼成一幅无缝的全景图或高分辨率图像的技术。
二、特征点匹配
特征点具有局部差异性
动机:特征点具有局部差异性
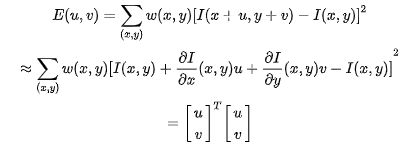
图像梯度
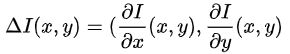
Harris矩阵
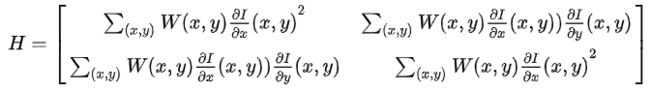

以每个点为中心取一个窗口,窗口大小为55或者77,如果这个点具有差异性,往周围任意方向移动,周围的环境变化都是会比较大的,如果满足这个特性,我们就认为这个特征点具有明显的局部差异性。在工事中,I表示像素,如果是 彩色图像就是RGB,灰色图像就是灰度。(u,v)表示方向。然后对上式进行一阶泰勒展开。
Harris矩阵H的特征值分析:
![]()
矩阵特征值反应了两个垂直方向的变化情况,一个事变化最快的方向,一个事变化最慢的方向

![]()
兴趣点位于光滑区域,不是特征点
![]()
兴趣点位于边缘区域
![]()
兴趣点位于角点区域
所以检测特征的任务转化为计算Harris矩阵,判断特征值大小。
在实际操作中,很少通过计算特征值来判断,因为计算特征值计算量比较大,取而代之的是Harris角点准则。
三、匹配错误的特征点干扰
在进行图像匹配过程中,如果图像的噪声太大,就会使得特征点的匹配发生了偏差,匹配到了错误的点,这种不好的匹配效果,会对后面的图像拼接产生很大的影响,如下图

四、消除干扰
为了进一步提升匹配精度,可以采用随机样本一致性(RANSAC)方法。
因为我们是使用一幅图像(一个平面物体),我们可以将它定义为刚性的,可以在pattern image和query image的特征点之间找到单应性变换(homography transformation )。使用cv::findHomography找到这个单应性变换,使用RANSAC找到最佳单应性矩阵。(由于这个函数使用的特征点同时包含正确和错误匹配点,因此计算的单应性矩阵依赖于二次投影的准确性)
五、RANSAC进行图像匹配
RANSAC是“RANdom SAmple Consensus(随机抽样一致)”的缩写。它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。
RANSAC的基本假设是:
(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;
(2)“局外点”是不能适应该模型的数据;
(3)除此之外的数据属于噪声。
局外点产生的原因有:噪声的极值;错误的测量方法;对数据的错误假设。
RANSAC也做了以下假设:给定一组(通常很小的)局内点,存在一个可以估计模型参数的过程;而该模型能够解释或者适用于局内点。
RANSAC原理
OpenCV中滤除误匹配对采用RANSAC算法寻找一个最佳单应性矩阵H,矩阵大小为3×3。RANSAC目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多,通常令h3=1来归一化矩阵。由于单应性矩阵有8个未知参数,至少需要8个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含4组匹配点对。
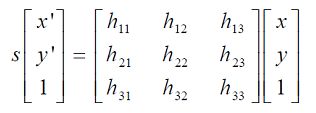
其中(x,y)表示目标图像角点位置,(x',y')为场景图像角点位置,s为尺度参数。
RANSAC算法从匹配数据集中随机抽出4个样本并保证这4个样本之间不共线,计算出单应性矩阵,然后利用这个模型测试所有数据,并计算满足这个模型数据点的个数与投影误差(即代价函数),若此模型为最优模型,则对应的代价函数最小。
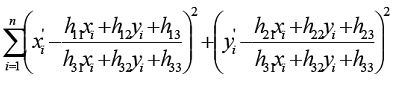
RANSAC算法步骤:
1.随机从数据集中随机抽出4个样本数据 (此4个样本之间不能共线),计算出单应矩阵H,记为模型M;
2.计算数据集中所有数据与模型M的投影误差,若误差小于阈值,加入内点集 I ;
3.如果当前内点集 I 元素个数大于最优内点集 I_best , 则更新 I_best = I,同时更新迭代次数k ;
4.如果迭代次数大于k,则退出 ; 否则迭代次数加1,并重复上述步骤;
注:迭代次数k在不大于最大迭代次数的情况下,是在不断更新而不是固定的;
其中,p为置信度,一般取0.995;w为"内点"的比例 ; m为计算模型所需要的最少样本数=4;


使用RANSAC图片匹配
from numpy import *
from matplotlib.pyplot import *
from PIL import Image
import warp
import homography
from PCV.localdescriptors import sift
featname = ['img/' + str(i + 1) + '.sift' for i in range(5)]
imname = ['img/' + str(i + 1) + '.jpg' for i in range(5)]
l = {}
d = {}
for i in range(5):
sift.process_image(imname[i], featname[i])
l[i], d[i] = sift.read_features_from_file(featname[i])
matches = {}
for i in range(4):
matches[i] = sift.match(d[i + 1], d[i])
# visualize the matches (Figure 3-11 in the book)
for i in range(4):
im1 = array(Image.open(imname[i]))
im2 = array(Image.open(imname[i + 1]))
figure()
sift.plot_matches(im2, im1, l[i + 1], l[i], matches[i], show_below=True)
# 将匹配转换成齐次坐标点的函数
def convert_points(j):
ndx = matches[j].nonzero()[0]
fp = homography.make_homog(l[j + 1][ndx, :2].T)
ndx2 = [int(matches[j][i]) for i in ndx]
tp = homography.make_homog(l[j][ndx2, :2].T)
# switch x and y - TODO this should move elsewhere
fp = vstack([fp[1], fp[0], fp[2]])
tp = vstack([tp[1], tp[0], tp[2]])
return fp, tp
# 估计单应性矩阵
model = homography.RanSacModel()
fp, tp = convert_points(1)
H_12 = homography.H_from_ransac(fp, tp, model)[0] # im 1 to 2
fp, tp = convert_points(0)
H_01 = homography.H_from_ransac(fp, tp, model)[0] # im 0 to 1
tp, fp = convert_points(2) # NB: reverse order
H_32 = homography.H_from_ransac(fp, tp, model)[0] # im 3 to 2
tp, fp = convert_points(3) # NB: reverse order
H_43 = homography.H_from_ransac(fp, tp, model)[0] # im 4 to 3
# 扭曲图像
delta = 100 # 用于填充和平移 for padding and translation
im1 = array(Image.open(imname[1]), "uint8")
im2 = array(Image.open(imname[2]), "uint8")
im_12 = warp.panorama(H_12, im1, im2, delta, delta)
im1 = array(Image.open(imname[0]), "f")
im_02 = warp.panorama(dot(H_12, H_01), im1, im_12, delta, delta)
im1 = array(Image.open(imname[3]), "f")
im_32 = warp.panorama(H_32, im1, im_02, delta, delta)
im1 = array(Image.open(imname[4]), "f")
im_42 = warp.panorama(dot(H_32, H_43), im1, im_32, delta, 2 * delta)
figure()
imshow(array(im_42, "uint8"))
axis('off')
show()
进行匹配的图片
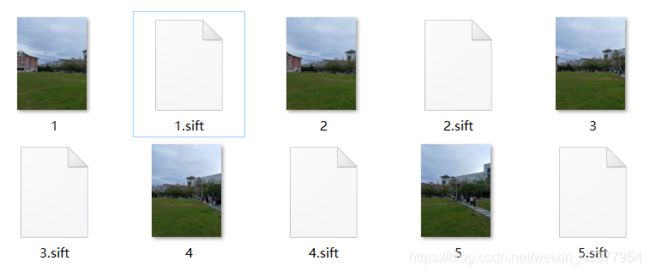
匹配后的图片



分析:
本次的拼接效果比较好,原因是因为我在同一时刻差不多角度拍摄的照片,噪声比较小,之前一组图片拍摄的噪声太大,导致最后出现不了结果。
由图片这部分可得,在不同时刻下拍摄照片导致天空颜色不同,在拼接的时候也会有明显的分割线。

在实验过程中,刚开始使用了一组照片,但运行不出结果,后来经过查询找到原因是因为图片匹配度太低,没办法进行匹配,后来重新拍摄了一组图片最终才完成。

到此这篇关于Python图像处理之图像拼接的文章就介绍到这了,更多相关Python图像拼接内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!