scrapy框架
一、简介
- 高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式
- 依赖:pip install scrapy
二、基本使用
- 创建工程:scrapy startproject ProjectName
- 进入到工程目录中:cd ProjectName
- 创建爬虫文件:scrapy genspider SpiderName SpiderUrl
- 执行工程:scrapy crawl spiderName
三、五大核心组件
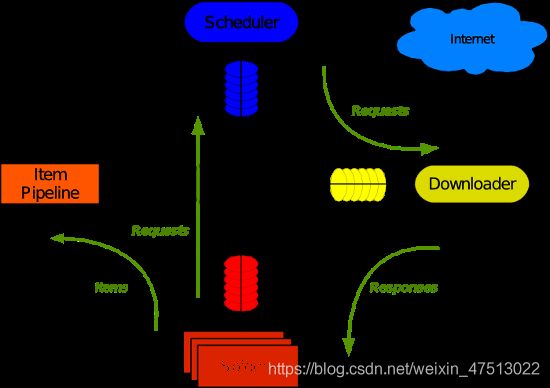
- 引擎(Scrapy)
- 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)
- 用来接受引擎发过来的请求, 压入队列中, 并且返回一个数据流个引擎, 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
- 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
- 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
- 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
四、定义数据模型iterms
import scrapy
class QiubaiproItem(scrapy.Item):
# define the fields for your item here like:
author = scrapy.Field()
content = scrapy.Field()
# pass
五、定义爬虫文件
- scrapy.Request(url, callback=None,meta=None)
- url:传入的新url
- callback:访问url成功后进行回调的函数
- meta:请求传参,最终会作为回调函数中response的属性
import scrapy
from qiubaiPro.items import QiubaiproItem
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response, **kwargs):
# 六、基于管道类持久化存储数据
1.一般文本管道类
class QiubaiproPipeline(object):
# 开始爬虫时调用,只会被调用一次
def open_spider(self, spider):
print('开始爬虫!')
# 专门用来处理item类型对象
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
...
# 这个返回值传递给下一个即将被执行的管道类
return item
def close_spider(self, spider):
print('结束爬虫!')
2.图片管道类
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class imgsPileLine(ImagesPipeline):
# 就是可以根据图片地址进行图片数据的请求
def get_media_requests(self, item, info):
yield scrapy.Request(url=item['src'])
# 指定图片存储的名称
def file_path(self, request, response=None, info=None, **kwargs):
# request的类型是:七、下载中间件
- 设置UA伪装
- 设置代理ip
- 篡改响应数据
import random
class MiddleproDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
....
]
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
# 拦截请求
# spider:爬虫对象。下同。
def process_request(self, request, spider):
# UA伪装
request.headers['User-Agent'] = random.choice(self.user_agent_list)
# 为了验证代理的操作是否生效
request.meta['proxy'] = 'http://183.146.213.198:80'
return None
# 拦截所有的响应
def process_response(self, request, response, spider):
...
new_response = HtmlResponse(
url=request.url, # 请求的url
body=page_text, # 页面的源码数据
encoding='utf-8',
request=request # 请求对象
)
return new_response
# 拦截发生异常的请求
def process_exception(self, request, exception, spider):
if request.url.split(':')[0] == 'http':
# 代理
request.meta['proxy'] = 'http://' + random.choice(self.PROXY_http)
else:
request.meta['proxy'] = 'https://' + random.choice(self.PROXY_https)
return request # 将修正之后的请求对象进行重新的请求发送
八、使用CrawlSpider进行全站数据爬取
- 1.CrawlSpider的使用:
- 创建一个工程:scrapy startproject ProjectName
- 进入到工程目录中:cd ProjectName
- 创建爬虫文件(CrawlSpider):scrapy genspider -t crawl SpiderName www.xxxx.com
- 执行工程:scrapy crawl SpiderName
- 2.链接提取器( LinkExtractor):
- 作用:根据指定的规则(allow)进行指定链接的提取
- 3.规则解析器(rules):
- 作用:对接提取器提取到的链接进行请求,返回给指定规则(callback)的解析
- 规则解析器中有多个Rule时,Rule之间是相互影响的
注:如果指定多个链接提取器和规则解析器,在回调函数中是无法实现请求传参,因为没有调用scrapy.Request方法。
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sunPro.items import SunproItem, DetailItem
# 需求:爬取sun网站中的编号,新闻标题以及详情页的新闻内容,编号
class SunSpider(CrawlSpider):
name = 'sun'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4&page=']
# 链接提取器:根据指定规则(allow="正则")进行指定链接的提取
# 链接提取器具有去重的功能:将重复的链接自动过滤
link = LinkExtractor(allow=正则)
link_detail = LinkExtractor(allow=正则)
# 规则解析器:将链接提取器提取到的链接进行指定规则(callback)的解析操作
rules = (
# follow=True:可以将链接提取器 继续作用到 连接提取器提取到的链接 所对应的页面中
Rule(link, callback='parse_item', follow=True),
Rule(link_detail, callback='parse_detail')
)
# 解析新闻编号和新闻的标题
# 如下两个解析方法中是不可以实现请求传参!(没有调用scrapy.Request方法)
# 无法将两个解析方法解析的数据存储到同一个item中,要存储到两个item
def parse_item(self, response):
# 注意:xpath表达式中不可以出现tbody标签
tr_list = response.xpath('//*[@id="morelist"]/div/table[2]//tr/td/table//tr')
for tr in tr_list:
new_num = tr.xpath('./td[1]/text()').extract_first()
new_title = tr.xpath('./td[2]/a[2]/@title').extract_first()
item = SunproItem()
item['title'] = new_title
item['new_num'] = new_num
yield item
# 解析新闻内容和新闻编号
def parse_detail(self, response):
new_id = response.xpath('/html/body/div[9]/table[1]//tr/td[2]/span[2]/text()').extract_first()
new_content = response.xpath('/html/body/div[9]/table[2]//tr[1]//text()').extract()
new_content = ''.join(new_content)
# print(new_id,new_content)
item = DetailItem()
item['content'] = new_content
item['new_id'] = new_id
yield item