0228
1.some refernce material
R Cookbook
R in Action
ggplot2
Advanced R
2.Installing and Loading Package
installing:install.packages('ggplot2')
loading:library(ggplot2)
updating:update.packages()
3.R language basics
create a vector: v=(1,4,4,3,2,2,3) or w=c("apple","banana","orange")
return certain elements: v【c(2,3,4)】 or v【2:4】 v【c(2,4,3)】
Delete certain element:v=【-2】 删除第二个元素 or v=【-2:-4】 删除2到4个元素
Extract element: v【v<3】 提取所有小于3的元素
Find elements: which(v==3) NOTE:the returns are the indices of elements,“=”是赋值,“==”是相等。
which.max(v)最大值
which.min(v)最小值
0229
4.Numbers随机数
Repeatable Random Numbers:set.seed(250)【12:00】使电脑重复产生的随机数相同
Random Number:a=runif(3,min=0,max=100)
Rounding of Numbers:floor(2)向下取整 ceiling(a)向上取整 round(a,4)括弧中的数字为保留的小数位数
Random Numbers from Other Distributions:rnorm()正态分布,rexp()指数分布,rbinom(),rgeom()几何分布,rnbinom()负二项分布
?round 查询命令
??round 产生与查询关键词相关内容
5.Data Input
loading local data:?read.csv;read.csv(file="……"); or read.table(file"……")
loading online data: read.csv("http://……")
attach:attach()
6.Graphs
plot:plot()
histograms:hist()直方图
density plot:plot(density())密度图
scatter plot:plot()散点图
box plot:boxplot(time~)箱线图
Q-Q plot:qqnorm(),qqline()and qqplot() quantiles & quanbles
par设定绘图环境
hist(x,breaks=20,col="blue")绘制直方图,竖条20根,填充为蓝色
plot(density(x))绘制曲线图
plot(x,type=“”)绘制散点图,形式为*
boxplot(x,y)箱线图 boxplot(time~***)区分性别
0330
a=c(1,2,3,4,5,6)
b=c("one","two","three")
c=c(TRUE,TRUE,FALSE)
x=matrix(1:20,nrow=5,ncol=4,byrow=TRUE)
y=matrix(1:20,nrow=5,ncol=4,byrow=FALSE)
x[2,]
x[,2]
x[2,c(2,4)]
x=[3:5,2]
rnames=c("apple","banana","orange","melon","corn")
cnanes=v("cat","dog","bird","pig")
rownames(x)=rnames
colnames(x)=cnames
0302
调成markdown编辑模式
一级标题
二级标题
三级标题
*斜体
我来自湖南
**加粗
黄鹤一去不复返
代码引用
大家好
图片引用
[图片上传失败...(image-cdfa6e-1587743770549)]
引用下文章叭
一片孤城万仞山
0303
1.putty安装
从官网下载putty,在putty中输入ip地址,再点open,再输入用户名和密码
2.在putty上操作Linux系统
思维导图:
 TIM图片20200303211602.png
TIM图片20200303211602.png
0304
下载miniconda
1.搜索conda官网,找到下载链接
2.ctrl+c复制链接
3.打开putty,cd biosoft
4.wget+右键粘贴链接
5.bash+刚下的文件
6.enter跳过加yes即可安装
7.最后激活:source ~/.bashrc
8.添加清华镜像:conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --set show_channel_urls yes
运行miniconda
1.用conda list来查看
2.用conda search fastqc来搜索fastqc软件
3.conda install fastqc -y来安装
4.conda remove fastqc -y来卸载
备注:
我在添加清华镜像的时候出现了错误,这时可尝试rm ~/.condarc来删除之前的配置,这样就可以继续添加了!!
0305
R语言的基础
1.安装R和Rstudio
1.百度搜索R和Rstudio,在相应的网站中下好安装
要确保自己的电脑用户名是英文的哦
2.用R语言进行一些画图
-50个正态分布随机数的圆点图:plot(rnorm(50))
箱型图: boxplot()
3.R语言的基本操作
1.dir(目录)到达路径
2.<-赋值
3.删除变量:rm(x)
4.列出历史命令:history()
5.清空控制台:ctrl+l
0306
R语言数据结构
赋值
1.一个值:v<-8
2.多个不连续:v<-c(3,5,7)
3.多个连续值(1到10):v<-[1:10]
4.数列:v<-seq(1:10,by=0.5)
5.重复:v<-rep(1:3,time=3)
取值
1.v[2]
2.v[1:3] 选第1到第3
3.v[c(1,3,4)] 选第1第3第4、
4.v[-4] 除了第四个数
5.v[v==10] v中等于10的数
6.v[v<4] v中小于4的数
7.v[v %in% c(1,3,4,5,5)] v中存在于向量中的数
读取本地数据和对数据的操作
1.读取数据:read.csv()文件应放置工作目录
2.导出数据:write.table()
3.设置行列名称
列名:colnames(v)[1]<-"xxxxx"改第一列的名称为xxxxx
行名:rownames(v)[1]<-"xxxxx"
4.数据保存:save.image(file="xxxx.Rdata")
单个变量保存:save.image(x,file="xxxx.Rdata")
5.提取数据框中元素:
x[x,y] 第x行第y列
x[x,] 第x行
x[,y] 第y列
6.将数据框名添加到搜索环境:attach(x)
问题
save(X,file="test.RData")这句代码如果报错X not found,是为什么,应该怎么解决?
答:是环境变量中没有X这个变量,解决的话应该找找是不是变量名弄错了,比如把小写x弄成大写
0307
0309
array
dim1=c("A1","A2")
dim2=c("B1","B2","B3")
dim3=c("C1","C2","C3","C4")
dim4=c("D1","D2","D3")
z=array(1:72, c(2,3,4,3),dimnames=list(dim1,dim2,dim3,dim4))
z[1,2,3,]
dataframe
attach(mtcars)
par(mfrow=c(1,4))#设置图的个数
plot(rnorm(50),pch=17)#pch点的形状
plot(rnorm(20),type = "l",lty=5)#lty线是形状
plot(rnorm(100),cex=3)#cex点的大小
plot(rnorm(200),lwd=2)#lwd线的大小
?pch
title(main = "normal list")
axis()
legend()
attach(mtcars)#加入R搜索途径
layout(matrix(c(1,1,2,3),2,2,byrow=TRUE))#矩阵
0311
对图形的设置
par(mfrow=c(1,4))#设置图的个数,partion
plot(rnorm(50),pch=17)#pch点的形状
plot(rnorm(20),type = "l",lty=5)#lty线是形状
plot(rnorm(100),cex=3)#cex点的大小
plot(rnorm(200),lwd=2)#lwd线的大小
?pch
title(main = "normal list")
axis()
legend()
attach(mtcars)#加入R搜索途径
layout(matrix(c(1,1,2,3),2,2,byrow=TRUE))#矩阵
hist(wt)#直方图
hist(mpg)
hist(disp)
hist(mtcars)
?pch
for和while的循环语句
for (i in 1:10) {#for loop循环,遍历
print(i)
i=i+1
}
i=1
while(i <= 10){#while loop循环
print(i)
i=i+1
}
0312
if条件和switch条件
i=1
if(i==1){
print("hello world")
}else{
print("goodbye eorld")
}
i=3
if(i==1){#if的条件语句
print("hello")
}else if (i==3) {#多个条件可一直else if
print("goodbye")
}else{
print("good game")
}
feelings=c("sad","afraid")
for(i in feelings){
print(
switch(i,#swich的作用相当于else if,转换
happy="i am glad",
afraid="something to fear",
sad="cheer up",
angry="calm dowm"
)
)
}
0313
R语言中的user-defined function
myfunction=function(x){#R语言中的user defined function
for(i in feelings){
print(
switch(i,
happy="i am glad",
afraid="something to fear",
sad="cheer up",
angry="calm dowm"
)
)
}
}
myfunction=function(x,a,b,c){
return(asin(x)^2-bx+c)
}
curve(myfunction(x,20,3,4),xlim=c(1,20))#画出刚刚定义的函数图像
myfeeling=function(x){
for(i in feelings){
print(
switch(i,
happy="i am glad",
afraid="something to fear",
sad="cheer up",
angry="calm dowm"
)
)
}
}
feelings=c("sad","afraid")
myfeeling(feelings)
0314
bar plot
library(vcd)
counts
counts <- table(Arthritis$Improved)
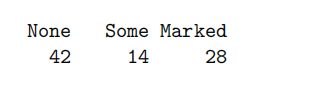 image.png
image.png
barplot(counts,
main="Simple Bar Plot",
xlab="Improvement", ylab="Frequency")
barplot(counts,
main="Horizontal Bar Plot",
xlab="Frequency", ylab="Improvement",
horiz=TRUE)
counts <- table(Arthritis Treatment)
barplot(counts,
main="Stacked Bar Plot",
xlab="Treatment", ylab="Frequency",
col=c("red", "yellow","green"),
legend=rownames(counts),
beside = TRUE)
pie plot
install.packages("plotrix")
library(plotrix)
slices <- c(10,12,4, 16, 8)
lbls <- c("US", "UK", "Australia", "Germany", "France")
pie(slices, labels = lbls,main="Simple Pie Chart",edges=300,radius=1)
0315
fan plot
slices <- c(10,12,4, 16, 8)
lbls <- c("US", "UK", "Australia", "Germany", "France")
fan.plot(slices,labels=lbls,main = "fan plot")
dot chart
dotchart(mtcars$mpg,
labels=row.names(mtcars),cex=0.7,
main="Gas Mileage for Car Models",
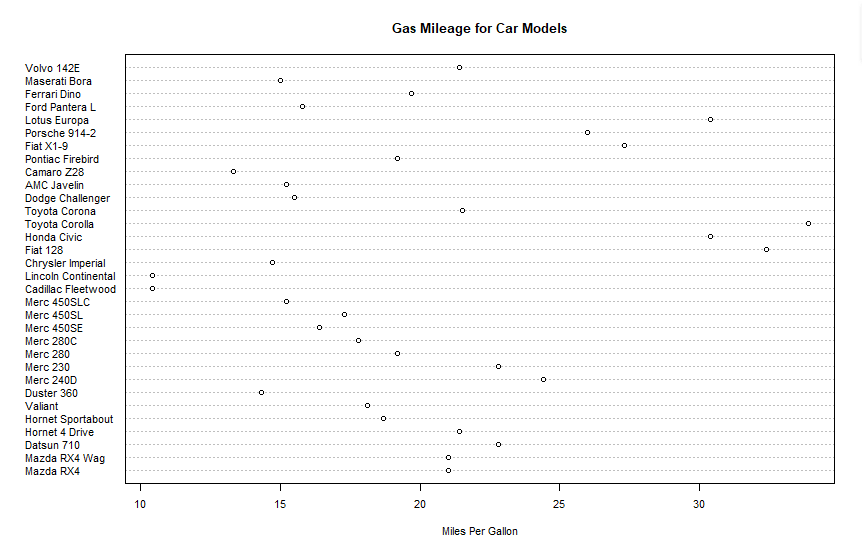
allon")
对数据的基本操作
head(mtcars)#展示前面六行
summary(mtcars)
attach(mtcars)
table(cyl)#统计该列数据的频数
table(cut(mpg,seq(10,34,by=2)))#统计该列数据特定区间的频数
0317
x = rnorm(100, mean = 10, sd = 1)
y = rnorm(100, mean = 30, sd = 10)
t.test(x, y, alt = "two.sided",paired=TRUE)#双边检验
set.seed(123)
A = matrix(sample(100,15), nrow=5, ncol=3)

t(A)#置换行列

A+2
A-2
A2
A/2
set.seed(234)
B = matrix(sample(100,15), nrow=5, ncol=3)
t(A)
t(A) %% B#共有区域矩阵相乘
colMeans(A)#列的平均数
colSums(A)#列的和
crossprod(A,B)#A的置换,乘以B
0318
FACTOR
factor=factor(rep(c(1:3),times=5))#对变量做标记
x=sample(100,15)
tapply(x,factor,mean)#用factor来对x标记
rbind(x,factor)
boo=rbind(x,factor)[2,]==2
which(boo)
rbind(x,factor)[1,which(boo)]
mean(rbind(x,factor)[1,which(boo)])
bilibili:AV5625356
柱状图:0319
单样品柱状图
file1="Anr.lib.stat.txt"
dat2=read.table(file=file1,check.names=F,header=T,sep="\t",comment.char = "")
对数据进行排序处理
dat2=dat2[order(dat2[,2],decreasing=T),]
head(dat2)
画图
bar1=ggplot(dat2,aes(x=Species_Name,y=Homologous_Number))+
geom_bar(stat = "identity",position = "dodge",width = 0.8)
bar1
ggsave(bar1,filename = "hello.png",width = 12,height = 9)
dat2
?read.table
修改排序
dat2[,1]=factor(dat2[,1],levels = dat2[,1],order=T)
Other最后
ending=c("Other")
level=as.character(dat2[!dat2[,1]==ending,1])
level=unique(c(level,ending))
dat2[,1]=factor(dat2[,1],levels=level,order=T)
bar1=ggplot(dat2,aes(x=Species_Name,y=Homologous_Number))+
geom_bar(stat = "identity",position = "dodge",width = 0.8)
0320
设定和映射的差别
p_bar=ggplot(dat2,aes(x=dat2[,1],y=dat2[,2],fill=dat2[,1]))+
geom_bar(stat="identity",position ="dodge",width = 0.8)+
scale_fill_brewer(palette="Paired",direction=-1)
p_bar
调用R中的颜色包
RColorBrewer::display.brewer.all()
文字标记
p_bar=p_bar+
geom_text(aes(label=paste(as.character(dat2[,3]*100),"%",sep="")),vjust = 1,size=3)
p_bar
标签文字的调整
p_bar=p_bar+labs(x="species",y="helo",title = "nothing")
p_bar
p_bar=p_bar+ggtitle(label="nothing",subtitle = "someshing")
p_bar
theme修改title,legend及背景
p_bar=p_bar+theme(
plot.title = element_text(size = 25,face = "bold", vjust = 0.5, hjust = 0.5),##title位置
axis.text.x=element_text(size = 10,face = "bold", vjust = 1, hjust = 1,angle = 45),##x轴文本位置
panel.background = element_rect(fill = "transparent",color = "black"),##表格内背景
plot.background = element_rect(fill = "lightblue",colour = "red"),##图样背景
axis.ticks.x=element_blank(),
panel.grid.minor = element_blank(), ##表格内格子
panel.grid.major = element_blank())
p_bar
321
多样品柱状图
file2="nr.lib.stat.txt"
读取数据
dat2=read.table(file2,sep="\t",check.names = F,header = T,comment.char = "")
head(dat2)
dat2=dat2[order(dat2[,3],decreasing = T),]
head(dat2)
相关标签设置
ending=c("other")
xlab="Species_Name"
ylab="Unigenes_num"
title="Nr"
subtitle="Homologous_Number"
固定顺序
level=as.character(dat2[!dat2[,1]==ending,1])
level=unique(c(level,ending))
dat2[,1]=factor(dat2[,1],levels=level,order=T)
dat2[,2]=factor(dat2[,2],order=T)
基础做图
library(ggplot2)
p_bar2=ggplot(dat2,aes(x=dat2[,1],y=dat2[,3],fill=dat2[,2]))+
geom_bar(stat="identity",width=0.7,position ="dodge",color="darkgrey")
p_bar2
p_bar2=ggplot(dat2,aes(x=dat2[,1],y=dat2[,3],fill=dat2[,2]))+
geom_bar(stat="identity",width=0.7,position =position_dodge(width=0.9),color="darkgrey")
p_bar2
标签修改,颜色修改#设置有aes(fill)生成的图例
p_bar2=p_bar2+labs(x=xlab,y=ylab)+
ggtitle(label=title,subtitle = subtitle)
p_bar2
fill="Cultivar"
p_bar2=p_bar2+labs(x=xlab,y=ylab,fill=fill)+
ggtitle(label=title,subtitle = subtitle)
p_bar2
322
多样品柱状图
file2="nr.lib.stat.txt"
读取数据
dat2=read.table(file2,sep="\t",check.names = F,header = T,comment.char = "")
head(dat2)
dat2=dat2[order(dat2[,3],decreasing = T),]
head(dat2)
相关标签设置
ending=c("other")
xlab="Species_Name"
ylab="Unigenes_num"
title="Nr"
subtitle="Homologous_Number"
固定顺序
level=as.character(dat2[!dat2[,1]==ending,1])
level=unique(c(level,ending))
dat2[,1]=factor(dat2[,1],levels=level,order=T)
dat2[,2]=factor(dat2[,2],order=T)
基础做图
library(ggplot2)
p_bar2=ggplot(dat2,aes(x=dat2[,1],y=dat2[,3],fill=dat2[,2]))+
geom_bar(stat="identity",width=0.7,position ="dodge",color="darkgrey")
p_bar2
p_bar2=ggplot(dat2,aes(x=dat2[,1],y=dat2[,3],fill=dat2[,2]))+
geom_bar(stat="identity",width=0.7,position =position_dodge(width=0.9),color="darkgrey")
p_bar2
标签修改,颜色修改#设置有aes(fill)生成的图例
p_bar2=p_bar2+labs(x=xlab,y=ylab)+
ggtitle(label=title,subtitle = subtitle)
p_bar2
fill="Cultivar"
p_bar2=p_bar2+labs(x=xlab,y=ylab,fill=fill)+
ggtitle(label=title,subtitle = subtitle)
p_bar2
控制顺序,基于建立的有序因子
p_bar2=p_bar2+scale_fill_brewer(palette="Set3",direction=1)
p_bar2
p_bar2=p_bar2+scale_fill_manual(values=c("red","turquoise"))
p_bar2
标记文字
p_bar2=p_bar2+
geom_text(aes(label=paste(as.character(dat2[,4]*100),"%",sep="")),position=position_dodge(width=0.9),vjust = -0.5,size=2)
p_bar2
细节调整
p_bar2=p_bar2+
theme(
plot.title = element_text(size = 25,face = "bold", vjust = 0.5, hjust = 0.5),
legend.title = element_text(size = 15,face = "bold", vjust = 0.5, hjust = 0.5),
legend.text = element_text(size = 10, face = "bold"),
legend.position = 'right',
legend.key.size=unit(0.5,'cm'),
axis.text.x=element_text(size = 10,face = "bold", vjust = 1, hjust = 1,angle = 45),
axis.text.y=element_text(size = 10,face = "bold", vjust = 0.5, hjust = 0.5),
axis.title.x = element_text(size = 15,face = "bold", vjust = 0.5, hjust = 0.5),
axis.title.y = element_text(size = 15,face = "bold", vjust = 0.5, hjust = 0.5),
panel.background = element_rect(fill = "transparent",colour = "black"),
panel.grid.minor = element_blank(),
panel.grid.major = element_blank(),
plot.background = element_rect(fill = "transparent",colour = "black"))
p_bar2
堆叠柱状图
p_barS=ggplot(dat2,aes(x=dat2[,1],y=dat2[,3],fill=dat2[,2]))+
geom_bar(stat="identity",width=0.8,position ="stack")
p_barS
反向填充
p_barS=ggplot(dat2,aes(x=dat2[,1],y=dat2[,3],fill=dat2[,2]))+
geom_bar(stat="identity",width=0.8,position =position_stack(reverse = T))
p_barS
文字标签,图例反向等
p_barS=ggplot(dat2,aes(x=dat2[,1],y=dat2[,3],fill=dat2[,2]))+
geom_bar(stat="identity",width=0.8,position =position_stack(reverse = T))+
labs(x=xlab,y=ylab,fill=fill)+
ggtitle(label=title,subtitle = subtitle)+
scale_fill_manual(values=c("red","turquoise"))+
guides(fill=guide_legend(reverse=F))
p_barS
p_barS=p_barS+
geom_text(aes(label=paste(as.character(dat2[,4]*100),"%",sep="")),position=position_stack(vjust = 0.5,reverse = T),size=3)
p_barS
323
基础饼状图
读取数据
file1="Anr.lib.stat.txt"
dat1=read.table(file=file1,check.names=F,header=T,sep="\t",comment.char = "")
head(dat1,3)
dat1=dat1[order(dat1[,2],decreasing = T),]
head(dat1)
排序处理
ending="Other"
fill="Species"
title="Nr"
subtitle="Homologous_Number"
level=as.character(dat1[!dat1[,1]==ending,1])
level=unique(c(level,ending))
dat1[,1]=factor(dat1[,1],levels=level,order=T)
柱状垛叠
p_pie=ggplot(dat1,aes(x="",y=dat1[,2],fill=dat1[,1]))+
geom_bar(stat="identity",width=1,position = position_stack(reverse = T))
p_pie
设置y轴极坐标,方向
p_pie=p_pie+
coord_polar(theta="y",direction=-1)
p_pie
颜色填充设置
p_pie=p_pie+
scale_fill_brewer(palette ="Set3",direction = 1)
p_pie
图例标题修改
p_pie=p_pie+
labs(x="",y="",fill=fill)+
ggtitle(label =title,subtitle=subtitle)
p_pie
文字标签
p_pie=p_pie+geom_text(aes(label=paste(as.character(dat1[,3]*100),"%",sep="")),position =position_stack(vjust=0.5,reverse = T),size=3)
p_pie
刻度背景调整
p_pie=p_pie+
theme(
plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5),
legend.title = element_text(hjust = 0.5),
axis.ticks = element_blank(),
axis.text.x = element_blank(),
panel.background = element_rect(fill = "transparent",colour = NA),
panel.grid.minor = element_blank(),
panel.grid.major = element_blank(),
plot.background = element_rect(fill = "transparent",colour = NA)
)
p_pie
数据分布——密度图,箱线图,直方图
325
读取数据
file="gene_fpkm.xls"
demo_fpkm=read.table(file,header = F,sep = "\t",check.names = F)
对数据进行处理
fpkm=melt(demo_fpkm,variable.name = "Sample",value.name = "FPKM")
head(fpkm,10)
画密度图
p_density=ggplot(fpkm,aes(x=log(fpkm[,3]),color=fpkm[,2],fill=fpkm[,2]))+
geom_density(alpha=0.25,size=0.5)
p_density
修改标度
p_density=p_density+xlim(-3,5)
p_density
标题主题修改
p_density=p_density+
ggtitle("Gene expression density")+
labs(x="log10FPKM",color="Samples",fill="Samples")+
theme_bw()
p_density
箱线图
p_box=ggplot(fpkm,aes(x=fpkm[,2],y=log10(fpkm[,3]),fill=fpkm[,2]))+
geom_boxplot(size=0.5,width=0.8,notch=T,outlier.shape = NA)
p_box
y轴范围限制
p_box=p_box+ylim(-3,5)
p_box
标题主题修改
p_box=p_box+
ggtitle("Gene expression distribution")+
labs(y="log10FPKM",x="",fill="Samples")+
theme_bw()
p_box
直方图
326
画点样品直方图
p_histogram=ggplot(fpkm,aes(x=log10(fpkm[,3]),fill=fpkm[,2]))+
geom_histogram(binwidth = 1,alpha=0.5,size=1,stat="bin")+
xlim(-3,5)
p_histogram
多样品直方图
默认stack模式
p_histogram=ggplot(fpkm,aes(x=log10(fpkm[,3]),fill=fpkm[,2]))+
geom_histogram(binwidth = 1,alpha=0.5,size=1,stat="bin")+
xlim(-3,5)
p_histogram
分区
p_histogram=p_histogram+
facet_grid(.~fpkm[,2],scales = "free")
p_histogram
频率型直方图
p_histogram=ggplot(fpkm,aes(x=log10(fpkm[,3]),y=..density..))+
geom_histogram(aes(fill=fpkm[,2]),binwidth = 1,alpha=0.5,size=1,stat="bin")+
xlim(-3,5)
p_histogram=p_histogram+
facet_grid(.~fpkm[,2],scales = "free")
p_histogram
加上密度曲线
p_freqpoly=ggplot(fpkm,aes(x=log10(fpkm[,3]),color=fpkm[,2]))+
geom_freqpoly(binwidth = 1,alpha=0.5,size=1,stat="bin")+
xlim(-3,5)
p_freqpoly
频数折线图
p_h_f=p_histogram+
geom_freqpoly(aes(color=fpkm[,2]),binwidth = 1,alpha=0.5,size=1,stat="bin")
p_h_f
327
读取数据
file="CK-WT_vs_T-WT.xls"
demo_DEG=read.table(file,check.names = F,header = T,sep = "\t")
head(demo_DEG)
设置阈值信息
line_FC=2
line_FDR=0.01
col=c("red","blue","grey")
AFPKM=c(2:4)
BFPKM=c(5:7)
通过阈值上下调信息
demo_DEG[demo_DEG[,"FDR"]
demo_DEG[demo_DEG[,"FDR"]
demo_DEG[demo_DEG[,"FDR"] >=line_FDR | log2(line_FC) > abs(demo_DEG[,"log2FC"]),ncol(demo_DEG)]="Normal"
colnames(demo_DEG)[ncol(demo_DEG)]="Regulate"
head(demo_DEG)
火山图
volcano=demo_DEG
有序因子的创建以便于颜色修改
volcanoRegulate,levels = c("Up","Down","Normal"),order=T)
初步画火山图
p_volcano=ggplot(volcano,aes(x=log2FC,y=-log10(FDR)))+
geom_point(aes(color=Regulate),alpha=0.5)
p_volcano
颜色的改变
p_volcano=p_volcano + scale_color_manual(values =col)
p_volcano
在基础图上加上阈值线
p_volcano=p_volcano +
geom_hline(yintercept=c(-log10(line_FDR)),linetype=4)+
geom_vline(xintercept=c(-log2(line_FC),log2(line_FC)),linetype=4)
p_volcano
主题修改
p_volcano=p_volcano+theme_bw()
p_volcano
保存
ggsave(p_volcano,filename = "six.png")
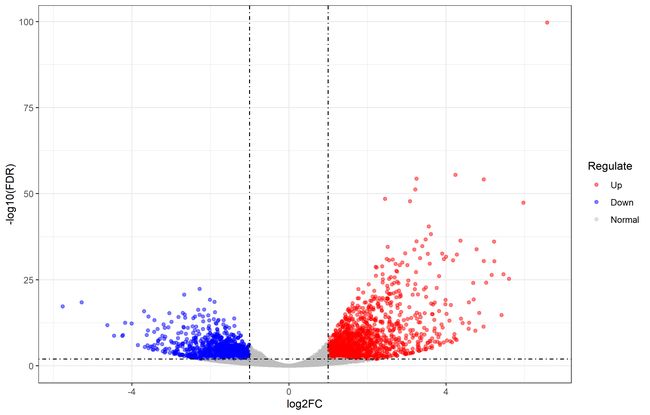
MA图
328
读取数据
head(demo_DEG,10)
设置xy轴名称
MA=demo_DEG[,c("ID","log2FC","Regulate")]
head(MA,2)
MA[,4]=1/2log2(rowMeans(demo_DEG[,AFPKM])rowMeans(demo_DEG[,BFPKM]))
colnames(MA)[4]="1/2log2FPKM"
head(MA,3)
有序因子设置
MARegulate,levels = c("Up","Down","Normal"),order=T)
MA图绘制
p_MA=ggplot(MA,aes(x=1/2log2FPKM,y=log2FC))+
geom_point(aes(color=Regulate),alpha=0.5)
p_MA
设置x轴范围
p_MA=p_MA+scale_x_continuous(limits = c(-5,15))
p_MA
颜色,阈值
加主题
p_MA=p_MA+
scale_color_manual(values =c("red","darkgreen", "darkgrey"))+
geom_hline(yintercept=c(-log2(line_FC),log2(line_FC)),linetype=4)+
theme_bw()
p_MA
保存
ggsave(p_MA,filename = "six(2).png")
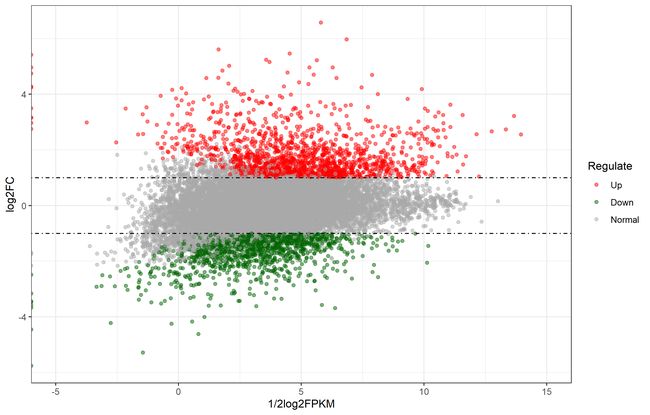
329
柱状图(富集分析结果可视化)
library(ggplot2)
读取数据
enrich="GO.enrich.txt"
demo_go=read.table(enrich,check.names = F,sep = "\t",header = T,comment.char = "")
head(demo_go)
对p值进行排序,并取P值前20小的数据
go=demo_go[order(demo_go[demo_go$Pvalue
if(nrow(go)>=20){
go=go[1:20,]
}
head(go)
对二级范围进行分别排序
go=go[order(go$Term_type,decreasing = F),]
head(go)
显著性高的排在前面
goDescription,levels = rev(go$Description),ordered = T)
筛选出P值为0的数,并转换为对数
go[go$Pvalue==0,"Pvalue"]=1e-15
画图,对x轴和y轴进行反转
go_bar=ggplot(go,aes(x=Description,y=-log10(Pvalue),fill=Term_type))+
geom_bar(stat="identity",width = 0.8)
go_bar
go_bar=go_bar+
coord_flip()
go_bar
对文字标签的修改,主题修改
go_bar=go_bar+
geom_text(aes(label=as.character(DEGs)),position = "stack",vjust=0,hjust=0,size=3)+
theme_bw()
go_bar
保存
ggsave(go_bar,filename = "seven(1).png")
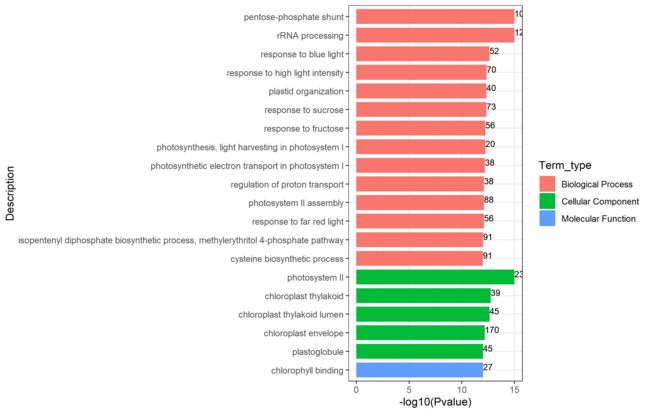
330
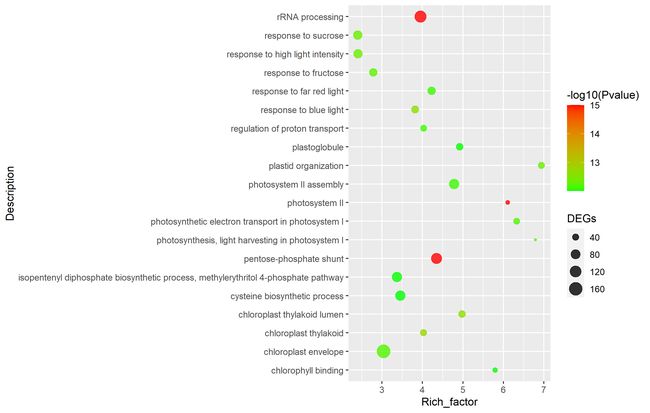
气泡图
设置阈值
enrich=0.01
minPvalue=1e-15
读取数据
demo_go=read.table(file,header = T,check.names = F,comment.char = "",sep = "\t")
head(demo_go)
对p值进行排序,并取P值前20小的数据
go=demo_go[order(demo_go[demo_go$Pvalue
if(nrow(go)>=20){
go=go[1:20,]
}
head(go)
筛选出P值为0的数,并转换为对数
go[go$Pvalue==0,"Pvalue"]=1e-15
画气泡图
go_point=ggplot(go,aes(x=Description,y=Rich_factor))+
geom_point(aes(color=-log10(Pvalue),size=DEGs),alpha=0.8)+coord_flip()
go_point
对颜色进行修改(渐变)
go_point=go_point+
scale_color_gradient(low = "green",high = "red")
go_point
保存
ggsave(go_point,filename = "seven(2).png")
331
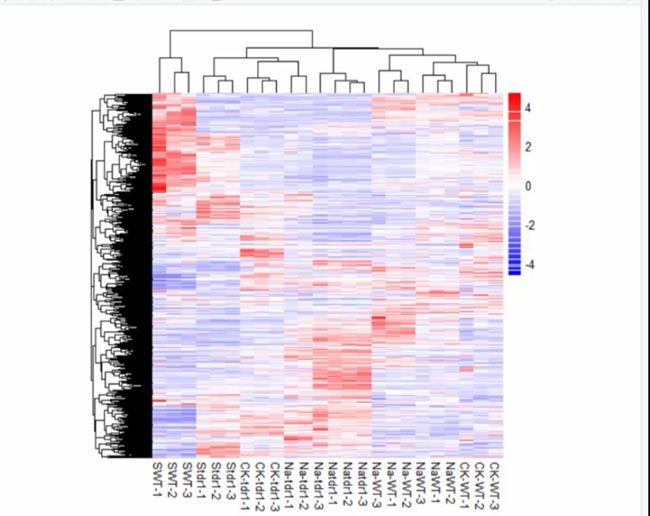
用pheatmap来绘制
install.packages("pheatmap")
library(pheatmap)
读取数据
file="All.DEG_final_3000.xls"
mat=read.table(file,check.names = F,header = T,sep = "\t",comment.char = "")
head(mat,3)
dim(mat)
pheatmap简单画图
pheatmap(mat)
options(stringsAsFactors = TRUE)
对基因结果标准化(行)
pheatmap(mat,scale = "row")
隐藏行名
pheatmap(mat,scale="row",show_rownames=F)
改变颜色
library(RColorBrewer)
RColorBrewer::display.brewer.all()
col=c("blue","white","red")
color=colorRampPalette(col)(100)
pheatmap(mat2,scale="row",show_rownames=F,color=color)
单元格大小cell
cellheight=300/nrow(mat)
cellwidth=300/ncol(mat)
cellwidth=10
cellheight=10
pheatmap(mat,scale="row",show_rownames=F,color=color,cellwidth = cellwidth,cellheight = cellheight,border_color="black")
424
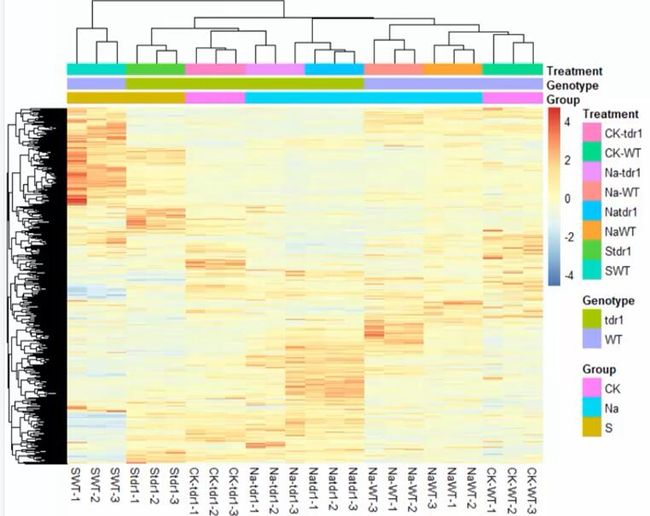
给热图添加注释
col_file="annotation_col1.xls"
annotation_col=read.table(col_file,header = T,row.names=1,sep="\t",check.names = F,comment.char = "")
annotation_col
pheatmap(mat,scale="row",show_rownames=F,annotation_col = annotation_col)
pheatmap(mat,scale="row",show_rownames=F,annotation_col = annotation_col,annotation_colors = ann_colors)
离散分类取色
brewer.pal.info
qual=rownames(brewer.pal.info[brewer.pal.info[,"category"]=="qual",])
qualColor=c()
for(i in qual){
qualColor=c(qualColor,brewer.pal(brewer.pal.info[i,"maxcolors"], i))
}
length(qualColor)
length(unique(qualColor))
qualColor=unique(qualColor)
qualColor
seq为数值分类
seqColor=list(Blues=c("#F7FBFF","#08306B"),Reds=c("#FFF5F0","#67000D"),
Greys=c("#FFFFFF","#000000"))
seqColor
设置注释颜色
annotation_color=list()
类型
char=1
num=1
for(i in colnames(annotation_col)){
if(is.numeric(annotation_col[,i])){
annotation_color[[i]]=seqColor[[num]]
num=num+1
}else{
n=length(table(annotation_col[,i]))
annotation_color[[i]]=qualColor[char:(char+n-1)]
names(annotation_color[[i]])=names(table(annotation_col[,i]))
char=char+n
}
}
查看
annotation_color
画图
pdf(file=paste(workdir,"/gene_heatmap.pdf",sep=""),width = 9,height = 9)
heatmap=pheatmap(mat,color=color,cellwidth = cellwidth,cellheight = cellheight,scale="row",
annotation_col = annotation_col,annotation_colors = annotation_color,
show_rownames=F,fontsize_col=8,fontsize=7)
dev.off()
行重排顺序
newOrder=mat[heatmaporder,]
添加cluster
cluster=10
row_cluster=cutree(heatmap$tree_row,k=cluster)
newOrder[,ncol(newOrder)+1]=row_cluster[match(rownames(newOrder),names(row_cluster))]
colnames(newOrder)[ncol(newOrder)]="Cluster"
head(newOrder,2)
write.table(newOrder,file = paste(workdir,"/gene_newOrder_withCluster.xls",sep = ""),sep="\t",row.names = T,col.names = T,quote = F)