基于上节,
https://blog.csdn.net/xudailong_blog/article/details/80588950
这里我们接着说一下基于邻域的算法
基于邻域的算法类别
基于邻域的算法是推荐系统中最基本的算法,在业界中得到广泛应用
- 1 基于用户的协同过滤算法
- 2 基于物品的协同过滤算法
(一)基于用户的协同算法
(1)定义:
在一个个性化推荐系统中,当一个用户需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后再把那些用户喜欢的、而用户没有听说过的物品推荐给用户,这种方法叫基于用户的协同过滤算法。
(2)步骤:
- 1 找到和目标用户兴趣相似的用户集合
- 2 找到这个集合中的用户喜欢的,而且目标用户没有听说过的物品推荐给目标用户
步骤一计算两个用户的兴趣相似度,主要是利用行为的相似度来计算兴趣的相似度。
通过余弦相似度计算

余弦相似度的伪代码:
def UserSimilarity(train):
W = dict()
for u in train.keys():
for v in train.keys():
if u == v:
continue
W[u][v] = len(train[u] & train[v])
W[u][v] /= math.sqrt(len(train[u]) * len(train[v]) * 1.0)
return W
此时的时间复杂度是 O(|U|*|U|),很多时间都浪费计算在用户的相似度上了。
其实我们可以首先建立物品到用户的倒排表,对于每个物品都保存对该物品产生过行为的用户 列表。令稀疏矩阵C[u][v]= ( ) ( ) N u N v 。那么,假设用户u和用户v同时属于倒排表中K个物品对 应的用户列表,就有C[u][v]=K。从而,可以扫描倒排表中每个物品对应的用户列表,将用户列 表中的两两用户对应的C[u][v]加1,最终就可以得到所有用户之间不为0的C[u][v]。
伪代码实现:

得到用户之间的兴趣相似度后,UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品
UserCF算法中用户u对物品的感兴趣程度:

UserCF推荐算法伪代码实现:

参数K 是UserCF的一个重要参数,它的调整对推荐算法的各种指标都会产生一定的影响:

性能分析指标(摘自原文):
准确率和召回率 可以看到,推荐系统的精度指标(准确率和召回率)并不和参数K成线 性关系。在MovieLens数据集中,选择K=80左右会获得比较高的准确率和召回率。因此选 择合适的K对于获得高的推荐系统精度比较重要。当然,推荐结果的精度对K也不是特别 敏感,只要选在一定的区域内,就可以获得不错的精度。
流行度 可以看到,在3个数据集上K越大则UserCF推荐结果就越热门。这是因为K决定 了UserCF在给你做推荐时参考多少和你兴趣相似的其他用户的兴趣,那么如果K越大,参 考的人越多,结果就越来越趋近于全局热门的物品。
覆盖率 可以看到,在3个数据集上,K越大则UserCF推荐结果的覆盖率越低。覆盖率的 降低是因为流行度的增加,随着流行度增加,UserCF越来越倾向于推荐热门的物品,从 而对长尾物品的推荐越来越少,因此造成了覆盖率的降低。
但是对于一些热门的物品必须进行一些惩罚
比如同大家都需要买《新华字典》这一物品,所以需要对《新华字典》进行惩罚、惩罚公式:


伪代码的实现:

上述大概就是UserCF算法的最后实现方式,去掉了热门物品的推荐。
基于UserCF算法的案例效果:Digg
用户反馈增加:用户“顶”和“踩”的行为增加了40%。
平均每个用户将从34个具相似兴趣的好友那儿获得200条推荐结果。
用户和好友的交互活跃度增加了24%。
用户评论增加了11%。
基于用户算法的缺点:
(1)首先, 随着网站的用户数目越来越大,计算用户兴趣相似度矩阵将越来越困难,其运算时间复杂度和空 间复杂度的增长和用户数的增长近似于平方关系。
(2)其次,基于用户的协同过滤很难对推荐结果作 出解释
(二)基于物品的协同算法(ItemCF)
定义:
给用户推荐那些和他们之前喜欢的物品相似的物品。
ItemCF算法并 不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的 相似度。
(2)算法步骤:
- 1 计算物品之间的相似度
- 2 根据物品的相似度和用户的历史行为给用户生成推荐列表
为了避免推荐出热门的物品,可以挖掘出更多的长尾信息的推荐系统:
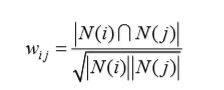
可以用上面的公式计算物品相似度,并惩罚了热门物品所占的权重。
(2)计算物品相似度
和UserCF算法类似,用ItemCF算法计算物品相似度时也可以首先建立用户—物品倒排表(即 对每个用户建立一个包含他喜欢的物品的列表),然后对于每个用户,将他物品列表中的物品两 两在共现矩阵C中加1
伪代码实现:

(2)计算用户u对一个物品j的兴趣

这里N(u)是用户喜欢的物品的集合,S(j,K)是和物品j最相似的K个物品的集合,wji是物品j和i 的相似度,rui是用户u对物品i的兴趣。
伪代码实现:

不同K值下的数据性能分析:

精度(准确率和召回率) 可以看到ItemCF推荐结果的精度也是不和K成正相关或者负相 关的,因此选择合适的K对获得最高精度是非常重要的。
流行度 和UserCF不同,参数K对ItemCF推荐结果流行度的影响也不是完全正相关的。 随着K的增加,结果流行度会逐渐提高,但当K增加到一定程度,流行度就不会再有明显 变化。
覆盖率 K增加会降低系统的覆盖率。
用户活跃度的惩罚:
比如有一个活跃用户买了当当上80%的图书,这时候把他计算进去,80%的书两两产生关系,针对这个情况,我们需要使用增加IUF参数来修正物品相似度的计算公式:

我们规定活跃用户对物品相似度的贡献应该不小于不活跃的用户,下面的伪代码是验证了上面的公式

最后:
(三)UserCF和ItemCF的综合比较
UserCF的推荐更社会化,反映了用户所在的 小型兴趣群体中物品的热门程度,而ItemCF的推荐更加个性化,反映了用户自己的兴趣传承
优缺点对比:

在新闻网站中,用户的兴趣不是特别细化,绝大多数用户都喜欢看热门的新闻。即使是个性 化,也是比较粗粒度的,比如有些用户喜欢体育新闻,有些喜欢社会新闻,而特别细粒度的个性 化一般是不存在的。比方说,很少有用户只看某个话题的新闻,主要是因为这个话题不可能保证 每天都有新的消息,而这个用户却是每天都要看新闻的。因此,个性化新闻推荐更加强调抓住 新闻热点,热门程度和时效性是个性化新闻推荐的重点,而个性化相对于这两点略显次要。因 此,UserCF可以给用户推荐和他有相似爱好的一群其他用户今天都在看的新闻,这样在抓住热 点和时效性的同时,保证了一定程度的个性化。这是Digg在新闻推荐中使用UserCF的最重要 原因。
UserCF适合用于新闻推荐的另一个原因是从技术角度考量的。因为作为一种物品,新闻的更 新非常快,每时每刻都有新内容出现,而ItemCF需要维护一张物品相关度的表,如果物品更新很 快,那么这张表也需要很快更新,这在技术上很难实现。绝大多数物品相关度表都只能做到一天 一次更新,这在新闻领域是不可以接受的。而UserCF只需要用户相似性表,虽然UserCF对于新 用户也需要更新相似度表,但在新闻网站中,物品的更新速度远远快于新用户的加入速度,而且 对于新用户,完全可以给他推荐最热门的新闻,因此UserCF显然是利大于弊。
但是,在图书、电子商务和电影网站,比如亚马逊、豆瓣、Netflix中,ItemCF则能极大地发 挥优势。首先,在这些网站中,用户的兴趣是比较固定和持久的。一个技术人员可能都是在购买 技术方面的书,而且他们对书的热门程度并不是那么敏感,事实上越是资深的技术人员,他们看 的书就越可能不热门。此外,这些系统中的用户大都不太需要流行度来辅助他们判断一个物品的 好坏,而是可以通过自己熟悉领域的知识自己判断物品的质量。因此,这些网站中个性化推荐的 任务是帮助用户发现和他研究领域相关的物品。因此,ItemCF算法成为了这些网站的首选算法。 此外,这些网站的物品更新速度不会特别快,一天一次更新物品相似度矩阵对它们来说不会造成 太大的损失,是可以接受的。
同时,从技术上考虑,UserCF需要维护一个用户相似度的矩阵,而ItemCF需要维护一个物品 相似度矩阵。从存储的角度说,如果用户很多,那么维护用户兴趣相似度矩阵需要很大的空间, 同理,如果物品很多,那么维护物品相似度矩阵代价较大。 在早期的研究中,大部分研究人员都是让少量的用户对大量的物品进行评价,然后研究用 户兴趣的模式。那么,对于他们来说,因为用户很少,计算用户兴趣相似度是最快也是最简单 的方法。但在实际的互联网中,用户数目往往非常庞大,而在图书、电子商务网站中,物品的 数目则是比较少的。此外,物品的相似度相对于用户的兴趣一般比较稳定,因此使用ItemCF是 比较好的选择。当然,新闻网站是个例外,在那儿,物品的相似度变化很快,物品数目庞大, 相反用户兴趣则相对固定(都是喜欢看热门的),所以新闻网站的个性化推荐使用UserCF算法的 更多。
结论:
新闻网站的个性化推荐使用UserCF算法的 更多
备注:因为推荐系统实践这本书讲的都是理论偏多,大部分的是需要了解,懂得原理。这里只是摘要出来一些重点,如若逻辑跳转不大能接受,可以自己看PDF版的书籍,需要的可以加群:
点击链接加入群聊【702689263 Python自学交流群】:https://jq.qq.com/?_wv=1027&k=5bcYh63