本次将从stack overflow网站上爬取一些信息。
先来看一下网站的python页面(https://stackoverflow.com/questions/tagged/python)

待爬数据.png
这个页面中包含了今天要爬取的所有信息,主要有:
让我们开始吧。
在shell中使用Selectors
为了方便起见,我将网页的html代码放到一个本地文件里,取名为tagged-python.html。可以先在scrappy shell中练习下XPath的用法。
使用如下命令进入大shell界面:
scrapy shell './tagged-python.html'
进入shell后我们可以使用response进行相关操作。利用response.text查看下是否载入正确。核实好后就可以开始我们的信息选取工作了。
先分析下页面html,利用浏览器自带的检查功能(右键,检查),我们可以看到如下界面:
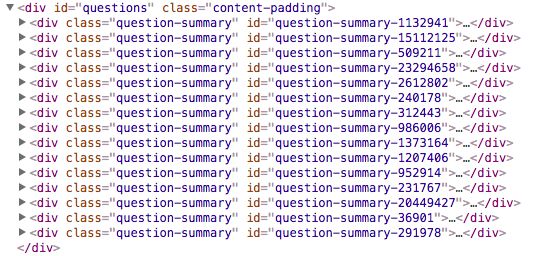
子模块.png
这里面包含了所有需要的数据。让我们对照这个列表逐一提取吧。
获取拥有本页所有问题的子模块,在此基础上逐步获取我们所需的信息。
xpath可以为: //*[@id="questions"]
questions = response.xpath("//*[@id='questions']")
为了加快查找速度,我们其实可以借助于浏览器自带的xpath功能。

copy_xpath.png
点击Copy XPath,显示如下:
//*[@id="questions"]
获取问题title
使用命令行
titles = questions.xpath("//*[@class='question-summary']/div[2]/h3/a/text()").extract()
我们得到一个list,如下:
In [15]: titles
Out[15]:
[u'\u201cLeast Astonishment\u201d and the Mutable Default Argument',
u'How do I test multiple variables against a value?',
u"Understanding Python's slice notation",
u'Asking the user for input until they give a valid response',
u'How to clone or copy a list?',
u'List of lists changes reflected across sublists unexpectedly',
u'How do you split a list into evenly sized chunks?',
u'How do I pass a variable by reference?',
u'How do I create a variable number of variables?',
u'Remove items from a list while iterating',
u'Making a flat list out of list of lists in Python',
u'What does the \u201cyield\u201d keyword do?',
u'How can I read inputs as integers?',
u'What does ** (double star/asterisk) and * (star/asterisk) do for parameters?',
u'Short Description of the Scoping Rules?']
包含了所有的titles信息。
获取其它信息
其它的与此类似,在此就不一一展开了。直接给出代码:
titles = questions.xpath("//*[@class='question-summary']/div[2]/h3/a/text()").extract()
askers = questions.xpath("//*[@class='question-summary']/div[2]/div[3]/div/div[3]/a/text()").extract()
answers_nums = questions.xpath("//*[@class='question-summary']/div[1]/div[2]/div[2]/strong/text()").extract()
votes = questions.xpath("//*[@class='question-summary']/div[1]/div[2]/div[1]/div/span/strong/text()").extract()
views = questions.xpath("//*[@class='question-summary']/div[1]/div[3]/text()").extract()
tags = questions.xpath("//*[@class='question-summary']/div[2]/div[2]/a[@class='post-tag']/text()").extract()
post_dates = questions.xpath("//*[@class='question-summary']/div[2]/div[3]/div/div[1]/span/text()").extract()
briefs = questions.xpath("//*[@class='question-summary']/div[2]/div[1]/text()").extract()
其中需要注意的是tags项,由于一个问题存在多个tag,如果用上面的代码实现对tag进行抓取,就没办法区分tag与问题的联系。可以改为:
questions = response.xpath("//*[@class='question-summary']")
tags = []
for question in questions:
tag = question.xpath("./div[2]/div[2]/a/text()").extract()
tags.append(tag)
views = [v.strip() for v in views]
post_dates = [p.strip() for p in post_dates]
创建project,保存数据到json文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from scrapy import Spider
class stackoverflow(Spider):
name = 'stackoverflow'
start_urls = [
'https://stackoverflow.com/questions/tagged/python'
]
def parse(self, response):
questions = response.xpath("//*[@class='question-summary']")
for question in questions:
yield {
'titles': question.xpath("./div[2]/h3/a/text()").extract(),
'askers': question.xpath("./div[2]/div[3]/div/div[3]/a/text()").extract(),
'answers_nums': question.xpath("./div[1]/div[2]/div[2]/strong/text()").extract(),
'votes': question.xpath("./div[1]/div[2]/div[1]/div/span/strong/text()").extract(),
'views': question.xpath("./div[1]/div[3]/text()").extract(),
'tags': question.xpath("./div[2]/div[2]/a[@class='post-tag']/text()").extract(),
'post_dates': question.xpath("./div[2]/div[3]/div/div[1]/span/text()").extract(),
'briefs': question.xpath("./div[2]/div[1]/text()").extract(),
}