Hbase是什么?
其源于 Google 三大论文之一的 bigtable ,
是一个具有高可靠性、高性能、面向列、可伸缩的分布式存储系统,
简单来说就是一个数据库。
Hbase的应用场景
这个问题比较不好回答,我们不如换个角度问:为什么要用 hbase:
- 数据量大,传统关系型数据库无法满足我们的需求
- 需要处理高并发请求
- 对实时性要求比较高
- 使用了HDFS 作为底层数据储存
- 非结构或者半结构化数据
以上四点基本就是为什么我要用hbase
基础概念
基本概念
- Row key
- Column 和 Column Family
- Timestamp
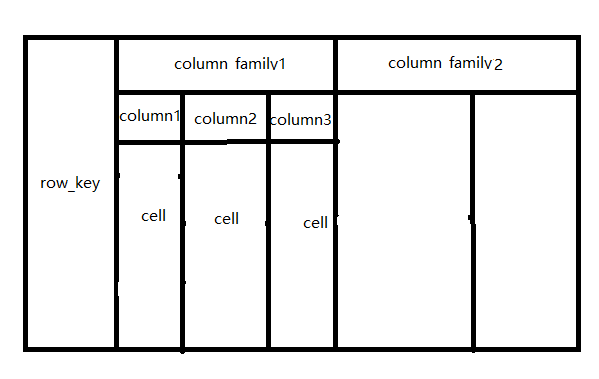
以上三个概念结合下面这张表结构图来理解下即可。
我们可以看到,一个rowkey 对应有多个 column family ,
其中 每个 column family 下又有多个 column,
一个rowkey 和一个 column 会确定一个 cell。
其中 timestamp 图中没有体现,
其实在每个cell里面保存了多个版本的数据,
而这个版本就是用 timestamp来做版本号的。
架构
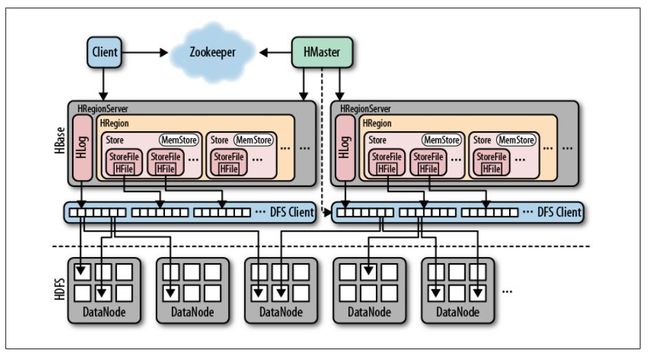
官方架构图如下:
 timg.jpg
timg.jpg
- HMaster节点:
- 管理HRegionServer,实现其负载均衡。
- 管理和分配HRegion,比如在HRegion split时分配新的HRegion;
在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上。 - 实现DDL操作(Data Definition Language,namespace和table的增删改,column familiy的增删改等)。
- 管理namespace和table的元数据(实际存储在HDFS上)。
- 权限控制(ACL)。
- HRegionServer节点:
- 存放和管理本地HRegion。
- 读写HDFS,管理Table中的数据。
- Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)。
- 负责过大 region 的切分
- Region
HBase自动把表水平划分成多个区域(region),
每个region会保存一个表里面某段连续的数据每个表一开始只有一个region,
随着数据不断插入表,region不断增大,
当增大到一个阀值的时候,
region就会等分会两个新的region(裂变)当table中的行不断增多,
就会有越来越多的region。
这样一张完整的表被保存在多个Regionserver 上。当然,生产环境一般都会有一步预分区的操作,
能够有效避免一些无谓的Region拆分发生。详细的自动Region拆分请看: HBase Region 自动拆分策略
- Memstore 与 storefile
Region是水平方向切分的结果,
而Store则是竖直方向切分,
一个store对应一个CF(列族)
所以一个region可以有多个store组成,Store 包括位于 内存中的memstore 和 位于HDFS的storefile,
写操作 先写入memstore,
当memstore中的数据达到某个阈值,
hregionserver会启动 flushcache进程写入storefile,
每次写入形成单独的一个storefile当storefile文件的数量增长到一定阈值后,
系统会进行合并(minor、major compaction),
在合并过程中会进行版本合并和删除工作(majar),
形成更大的storefile当一个region的某个 storefile的大小超过一定阈值后,
会把当前的region的所有StoreFile 均分为两个,
并由 hmaster 分配到相应的regionserver服务器,
实现负载均衡客户端检索数据,先在memstore找,
找不到再找storefile。(读过程最先扫描的blockcache,图中未体现)
- ZooKeeper集群是协调系统:
存放整个 HBase 集群的元数据以及集群的状态信息
(这里强调一下,是元数据状态信息,不是元数据信息)。实现 HMaster 主从节点的 failover(容错)。
- 底层储存系统
图中是 hdfs 为储存系统,
其实也可以是其他的文件系统,
比如 Linux 本地文件系统。
Hbase 和底层储存系统是解耦的,但目前来说,基本都是使用的 hdfs。
Hbas读写数据简析
- 读数据
- client 去 zookeeper 集群寻找到 hbass:meta 表所在的 regionserver
- 根据查找的 rowkey 去 元数据 所在的 regionserverA ,寻找 数据 所在的 regionserverB
- 根据查找的 rowkey去数据所在的 regionserverB 找到该数据进行读取
具体的流程可以参考https://blog.csdn.net/gingerredjade/article/details/63697830
- 写数据
Client 先访问 zookeeper,获取到元数据储存的 regionserver A
通过储存元数据的 regionserver A ,根据 rowkey 找到相对应的region,以及管理该 region 的 regionserver B
向 regionserver B 发起写入请求
regionserver B 接受到数据后,将数据保存到 MemStore ,
并根据相应的配置决定是否写入 HLog文件( 一个标准的Hadoop SequenceFile,文件中存储了HLogKey,这些Keys包含了和实际数据对应的序列号,主要用于崩溃恢复)同时检测 MemStore是否达到阈值,
如果达到了,则flush到磁盘形成 StoreFile 文件这里值得一提的是,
Hbase支持更新,删除 等操作,
但其实质都是追加操作。
比如:删除了 A,只是把A标记为删除,
更新则是追加一个更新的值,
旧值依然存在,但是只能读到新值。
只有在发生 major compact 的时候,才会对数据进行整理。不是每次写操作都会走这个完整的过程,
因为这对zookeeper 和 Hbase的元数据节点 会产生很大的压力,
所以客户端是会对元数据进行缓存,
只有 无元数据或者失效的 情况下会走这个完整的过程,
否则直接去请求对应的RegionServer就是了。
关于MemoryStore的详细工作流程可以参照https://www.jianshu.com/p/7dbaf45e0d0b
注意:
由于不同的列族会共享region,所以有可能出现,
一个列族已经有100万行,而另外一个才100行。
当一个要求region分割的时候,
会导致100行的列会同样分布到多个region中。
所以,一般建议不要设置多个列族。
不过该问题在2.x版本中有修正,请参见HBASE-10201/HBASE-3149
- HLogFile的容错和恢复
可以参考:https://blog.csdn.net/nigeaoaojiao/article/details/54909921
https://www.cnblogs.com/andy6/p/8978917.html
HLog文件:
就是一个普通的Hadoop Sequence File,
Sequence File 的Key是HLogKey对象,
HLogKey中记录了写入数据的归属信息,
除了table和region名字外,
同时还包括 sequence number和timestamp,timestamp是“写入时间”,
sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
HLog Sequece File的Value是HBase的KeyValue对象,
即对应HFile中的KeyValue.容错和恢复:
每个HRegionServer中都有一个HLog对象,
HLog是一个实现Write Ahead Log的类,
在每次用户操作写入MemStore的同时,
也会写一份数据到HLog文件中,
HLog文件定期会滚动出新的Hlog文件,
所以Hlog文件会有很多个,
当一些老旧的Hlog文件失效后(已持久化到StoreFile中的数据)
就会被RS删除。
当HRegionServer意外终止后,
HMaster会通过Zookeeper感知到,
HMaster首先会处理遗留的 HLog文件,
将其中不同Region的Log数据进行拆分,
分别放到相应region的目录下,
然后再将失效的region重新分配,
领取 到这些region的HRegionServer在Load Region的过程中,
会发现有历史HLog需要处理,
因此会Replay HLog中的数据到MemStore中,
然后flush到StoreFiles,完成数据恢复。
PS:
本段内容准确性有待深入研究
如果我们开启了异步写入Hlog,
Hbase的数据写入 MemoryStore 可能会先于 写入Hlog,
这很可能会造成一个问题,
写入 MemoryStore 成功,
客户端可以读取到数据,
但是写入Hlog失败了,
这个时候如果在数据还没flush到磁盘就宕机了,
那么这个数据就丢失了,客户端就读取不到了,
这也就发生了数据不一致的情况,
但是其实这是不需要担心的,
因为如果还没成功写入Hlog,这条数据客户端是看不到的,
并且如果最后失败了,那么MemoryStore也会回滚。
HBase表的设计(RowKey的设计)
rowkey的设计一般都是根据具体业务需求来的,
总的来说,我们需要根据rowkey的 字典序排列,
唯一性 特性设计出 高效读取 和 负载均衡的 rowkey,
以下是几个大概的设计原则:
- 长度原则:
越小越好,最长不能超过64kb,一般 10-100个字节就差不多了 - 个数原则:
这里是指列簇的个数,前面已经给出原因,尽量控制在2个以内 - 散列原则:
我们知道region是根据rowkey划分的,
那么rowkey的散列就可以使得数据的负载变得均衡,
一般来说我们可以通过 :- 加随机前缀
- 加hash值
- rowkey反转
- rowkey唯一原则:必须在设计上保证其唯一性
- rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。 比如:
- 我们需要某个时间端的数据进行分析,那么以 timestamp-key 的形式,我们很容易就可以查询到连续的时间段 的数据。
- 避免热点问题:上面那个列子,虽然我们的设计查询起来很方便,但是事实上,会有严重的热点问题,所有产生的数据都会集中在一个节点上进行处理,其余的节点将不会被分配到任何数据,这会导致严重的数据倾斜。所以我们也参照 3.散列原则。
- rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。 比如:
- 索引表
鉴于上面 3 和 4原则的冲突,
我们就很有必要引入索引表的概念了。
还是以我们需要某个连续时间端的数据进行分析为例:- 满足 3.散列原则 我们的rowkey可以这么设计: hash-key_timestamp
- 为了同时满足 4.唯一原则,
我们可以设计一个索引表 index_table,
该表的 rowkey 我们可以这么设计成这样timestamp_hash-key,
其 对应的列的值可以是 hash-key_timestamp,
因为索引表的数据很小,
我们完 全是可以不去考虑热点这个问题,
这样我们需要 某个时间段的数据,
可以通过索引表很快查出相应的数据 对应的 rowkey。
但是这里有个问题是,我们怎么去建立这个索引表,
要是hbase的原始数据有变动,
我们怎么实时更新索引表呢?以下大概提供几种思路,
有兴趣的请自行了解,或者关注我后续的博客:
- 手动处理:通过代码,每次对hbase的更新,我们都同时更新一下索引表
- hbase 的协处理器
当然一般我们都是使用协处理器来帮助我们处理这个问题,
并且索引表的建立也可以借助第三方,比如:ES
split 和 预分区
(参考https://www.cnblogs.com/niurougan/p/3976519.html)
什么是 split?
当一个reion达到一定的大小,为了负载均衡,
我们需要分裂成两个region,这个过程就是 split。hbase是如何处理 split 的?
- 在0.94版本之前 ConstantSizeRegionSplitPolicy 是默认和唯一的split策略。
当某个store(对应一个column family)的大小大于配置值hbase.hregion.max.filesize的时候(默认10G)region就会自动分裂。 - 而0.94版本中,IncreasingToUpperBoundRegionSplitPolicy 是默认的split策略。
这个策略中,最小的分裂大小和region server的region 个数有关,
当storefile的 size 大于如下公式得出的值的时候就会split,公式如下:
/**
*R为同一个table中在同一个region server中region的个数。
*hbase.hregion.memstore.flush.size 默认值 128MB。
*hbase.hregion.max.filesize默认值为10GB 。
*/
Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”)
当 R=1 ,那么Min(128MB,10GB)=128MB,也就是说在第一个flush的时候就会触发分裂操作。
当 R=2 ,的时候Min(22128MB,10GB)=512MB ,当某个store file大小达到512MB的时候,就会触发分裂。
如此类推,当 R=9 的时候,store file 达到 10GB 的时候就会分裂,
当R>=9的时候,store file 达到10GB的时候就会分裂。
- split 点都位于 region 中 rowkey 的中间点,也就是说会尽量将大 region 等分成两个 小 region。
KeyPrefixRegionSplitPolicy 策略可以保证相同的前缀的row保存在同一个region中。
指定rowkey前缀位数划分region,通过读取 KeyPrefixRegionSplitPolicy.prefix_length 属性,该属性为数字类型,表示前缀长度,在进行split时,按此长度对splitPoint进行截取。此种策略比较适合固定前缀的rowkey。当table中没有设置该属性,指定此策略效果等同与使用IncreasingToUpperBoundRegionSplitPolicy。我们可以通过配置 hbase.regionserver.region.split.policy 来指定split策略,我们也可以写我们自己的split策略。
什么是预分区?
也可以叫 pre-split,其实就是预先划分好 region,
我们知道每个 region 都有一个 startkey 和一个 endkey,
这样也就确定了这个 region 所管理的数据的范围,
那么预分区也就是我们预先将一个个 region 划分好 startkey 和 endkey,
确定好各自管理的数据。为什么需要预分区?
默认的 hbase 会有一个region,
当数据越来越大,那么这个 region 管理的数据越来越多,
当超过阈值,就会发生 split 操作,
而 split 操作会导致我们的hbase有一段不可用的时间,
那么为了尽量规避这个问题,所以我们需要预分区。如何预分区?
- 首先我们需要对数据的分布 和 数据量的增长有一个预测
- 根据数据量确定分区数,
然后再对数据进行合理的rowkey设计,
我们以一个简单的例子来说明:
假设我们预测数据会有 50G,
那么我们划分 5 个分区,
分别是:[-∞ - 1),[1 - 2),[2 - 3),[3 - 4),[4 - +∞),
rowkey的我们可以设计成[0-5)的随机数 + key - 这样数据就会均匀的分布在我们预先设计好的分区上,
也就达到了我们的需求,
但是需要注意的是,
随着数据越来越大,
超出我们预估的 50G 那么这个时候,
我们也需要重新对分区进行调整了
Hbase 数据查询方式
HBase的查询实现只提供两种方式:
按指定RowKey 获取唯一一条记录,
get方法(org.apache.hadoop.hbase.client.Get)
Get 的方法处理分两种 :
设置了ClosestRowBefore 和没有设置的rowlock .
主要是用来保证行的事务性,
即每个get 是以一个row 来标记的.
一个row中可以有很多 column family 和column.按指定的条件获取一批记录,
scan方法(org.apache.Hadoop.hbase.client.Scan)
实现条件查询功能使用的就是scan 方式.
scan 可以通过setCaching 与setBatch 方法提高速度(以空间换时间);
scan 可以通过setStartRow 与setEndRow 来限定范围[start,end)
start 是闭区间,end 是开区间。
范围越小,性能越高。scan 可以通过setFilter 方法添加过滤器,
这也是分页、多条件查询的基础。
compact
在hbase中每当有memstore数据flush到磁盘之后,就形成一个storefile,
当storeFile的数量达到一定程度后,
就需要将 storefile 文件来进行 compaction 操作。
Compact 的作用:
- 合并文件
- 清除过期,多余版本的数据
- 提高读写数据的效率
HBase 中实现了两种 compaction 的方式:minor and major. 这两种 compaction 方式的区别是:
- Minor 操作只用来做部分文件的合并操作以及包括 minVersion=0 并且设置 ttl 的过
期版本清理,不做任何删除数据、多版本数据的清理工作。 - Major 操作是对 Region 下的HStore下的所有StoreFile执行合并操作,最终的结果是整理合并出一个文件。
宕机处理
宕机分为HMaster宕机和HRegisoner宕机,
- HRegisoner宕机,HMaster会将其所管理的region重新分布到其他活动的RegionServer上,由于数据和日志都持久在HDFS中,该操作不会导致数据丢失。所以数据的一致性和安全性是有保障的。
- HMaster宕机,HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行。即ZooKeeper会保证总会有一个HMaster在对外提供服务。
过滤器
可以参考https://www.jianshu.com/p/18ef91fbb090
https://www.cnblogs.com/similarface/p/5805973.html
优化 (未完)
并发读写
kv 解决key过长的问题:增加value的大小,序列化之后储存
bulkload
压缩