Hadoop--MapReduce序列化本地运行实例以及踩过的坑
目录
-
-
- 一、环境说明
- 二、实例需求格式说明
- 三、对象序列化复习
-
-
- 1.为什么要序列化
- 2.java自带的序列化
- 3.hadoop默认序列化
- 4.hadoop序列化步骤
-
- 四、MapReduce编程规范复习
-
-
- 1.map阶段
- 2.Reducer阶段
- 3.**Driver阶段:**
-
- 五、案例代码
-
-
- 1.序列化bean
- 2.Map阶段
- 3.Reducer阶段
- 4.Driver阶段
- 5.日志输出文件
-
- 六、一些容易错的地方以及解决办法
-
-
- 1.报找不到winutils.exe
- 2.NativeIO$Windows错误
- 3.报空指针异常错误
- 4.报文件已经存在错误
-
-
一、环境说明
- hadoop 3.2.1
- jdk1.8
- maven 3.6.3
- idea2020.1
二、实例需求格式说明
要求输入文件数据格式:
7 13560436666 120.196.100.99 1116 954 200
id 手机号码 网络ip 上行流量 下行流量 网络状态码
要求输出文件数据格式:
13560436666 1116 954 2070
手机号码 上行流量 下行流量 总流量
三、对象序列化复习
1.为什么要序列化
- 作为一种持久化格式:一个对象被序列化以后,它的编码可以被存储到磁盘上,供以后反序列化用。
- 作为一种通信数据格式:序列化结果可以从一个正在运行的虚拟机,通过网络被传递到另一个虚拟机上。
- 作为一种拷贝、克隆(clone)机制:将对象序列化到内存的缓存区中。然后通过反序列化,可以得到一个对已存对象进行深拷贝的新对象。
2.java自带的序列化
java自带的Serializable序列化框架是一个重量级的框架,因为这个对象的类、类签名、类的所有非暂态和非静态成员的值,以及它所有的父类都要被写入,正是由于这些附带的信息很多,不适合在网络上传输,但是hadoop集群确实依靠网络,所以java自带的序列化是不适合使用在hadoop上的
3.hadoop默认序列化
hadoop对一些常见的字面量以及对象进行默认的序列化,
| Java类型 | Hadoop Writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
4.hadoop序列化步骤
- 必须实现Writable接口
- 反序列化时,需要反射调用空参构造函数,所以必须有空参构造
- 重写序列化方法
- 重写反序列化方法
注意反序列化的顺序和序列化的顺序完全一致
- 重写toString()
四、MapReduce编程规范复习
1.map阶段
- 用户自定义的Mapper要继承Mapper父类
- MapPer的输入数据是KV对的形式(KV的类型可自定义)
- Mapper中的业务逻辑写在map()方法中
- Mapper的输出数据是KV对的形式(KV对的类型可自定义)
- map()方法(MapTask进程)对每个
2.Reducer阶段
- 用户自定义的Reducer要继承自己的Reducer类
- Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
- Reducer 的业务逻辑写在reduce()方法中
- ReduceTask进程对每一组相同K的
3.Driver阶段:
- 获取job对象
- 指定本程序的jar包所在的本地路径
- 指定 map reducer类所在位置
- 指定map reducer输出
- 指定文件输入输出
五、案例代码
1.序列化bean
com.hadoop.FlowBean
package com.hadoop;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @author 四五又十
* @version 1.0
* @date 2020/5/22 19:17
*/
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean() {
super();
}
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
public Long getUpFlow() {
return upFlow;
}
public void setUpFlow(Long upFlow) {
this.upFlow = upFlow;
}
public Long getDownFlow() {
return downFlow;
}
public void setDownFlow(Long downFlow) {
this.downFlow = downFlow;
}
public Long getSumFlow() {
return sumFlow;
}
public void setSumFlow(Long sumFlow) {
this.sumFlow = sumFlow;
}
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow= in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow ;
}
}
2.Map阶段
com.hadoop.FlowCountMapper
package com.hadoop;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author 四五又十
* @version 1.0
* @date 2020/5/22 20:35
*
* 输入数据:7 13560436666 120.196.100.99 1116 954 200
* id 手机号码 网络ip 上行流量 下行流量 网络状态码
* map阶段输出数据:
* 13560436666, 1116 954
*
*/
public class FlowCountMapper extends Mapper<LongWritable, Text,Text, FlowBean> {
private Text k = new Text();
private FlowBean v = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.将数据转为String
String line = value.toString();
//2.切割
String[] files = line.split("\t");
//3.取出数据
k.set(files[1]); //手机号码作为key
v.setUpFlow(Long.parseLong(files[files.length - 3]));
v.setDownFlow(Long.parseLong(files[files.length - 2]));
//4.输出数据
context.write(k, v);
}
}
3.Reducer阶段
com.hadoop.FlowCountReducer
package com.hadoop;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author 四五又十
* @version 1.0
* @date 2020/5/22 20:46
*
* 输入数据: 13560436666, 1116 954
* 输出数据: 13560436666 1116 954 2070
*
*
*/
public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
private Text k = new Text();
private FlowBean v = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long upFlow = 0;
long downFlow = 0;
long sumFlow = 0;
for (FlowBean value : values) {
upFlow += value.getUpFlow();
downFlow += value.getDownFlow();
}
v.setDownFlow(downFlow);
v.setUpFlow(upFlow);
v.setSumFlow(downFlow + upFlow);
k.set(key.toString());
context.write(k, v);
}
}
4.Driver阶段
com.hadoop.FlowCountDriver
package com.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author 四五又十
* @version 1.0
* @date 2020/5/22 20:54
*/
public class FlowCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[2];
args[0] = "f:/input";
args[1] = "f:/output";
//1.获取
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.指定本程序的jar包所在的本地路径
job.setJarByClass(FlowCountDriver.class);
//3.指定 map reducer
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
//4.指定map reducer输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//5.指定文件输入输出
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
5.日志输出文件
log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
六、一些容易错的地方以及解决办法
1.报找不到winutils.exe
2020-05-23 15:32:57,083 WARN [org.apache.hadoop.util.Shell] - Did not find winutils.exe: {
}
java.io.FileNotFoundException: Could not locate Hadoop executable: F:\hadoop\hadoop-3.2.1\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems
at org.apache.hadoop.util.Shell.getQualifiedBinInner(Shell.java:619)
at org.apache.hadoop.util.Shell.getQualifiedBin(Shell.java:592)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:689)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:78)
at org.apache.hadoop.conf.Configuration.getBoolean(Configuration.java:1665)
at org.apache.hadoop.security.SecurityUtil.setConfigurationInternal(SecurityUtil.java:104)
at org.apache.hadoop.security.SecurityUtil.<clinit>(SecurityUtil.java:88)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:316)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:304)
at org.apache.hadoop.security.UserGroupInformation.doSubjectLogin(UserGroupInformation.java:1828)
at org.apache.hadoop.security.UserGroupInformation.createLoginUser(UserGroupInformation.java:710)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:660)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:571)
at org.apache.hadoop.mapreduce.task.JobContextImpl.<init>(JobContextImpl.java:72)
at org.apache.hadoop.mapreduce.Job.<init>(Job.java:150)
at org.apache.hadoop.mapreduce.Job.getInstance(Job.java:193)
at com.hadoop.FlowCountDriver.main(FlowCountDriver.java:28)
2020-05-23 15:32:57,154 WARN [org.apache.hadoop.util.NativeCodeLoader] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2020-05-23 15:32:58,117 WARN [org.apache.hadoop.metrics2.impl.MetricsConfig] - Cannot locate configuration: tried hadoop-metrics2-jobtracker.properties,hadoop-metrics2.properties
2020-05-23 15:32:58,344 INFO [org.apache.hadoop.metrics2.impl.MetricsSystemImpl] - Scheduled Metric snapshot period at 10 second(s).
2020-05-23 15:32:58,344 INFO [org.apache.hadoop.metrics2.impl.MetricsSystemImpl] - JobTracker metrics system started
解决办法:拷贝一个winutils.exe文件过hadoop本地环境的bin目录下,这个文件百度一下就可以下载到
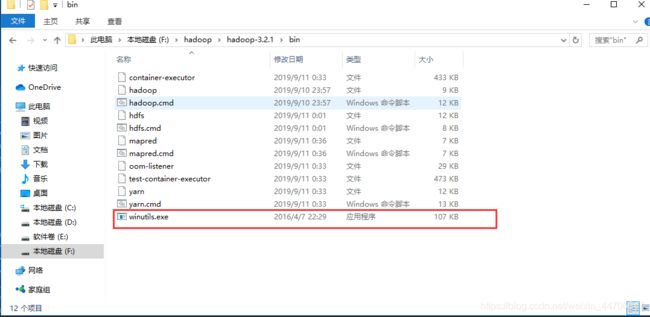
2.NativeIO$Windows错误
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:645)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:1230)
at org.apache.hadoop.fs.FileUtil.list(FileUtil.java:1435)
at org.apache.hadoop.fs.RawLocalFileSystem.listStatus(RawLocalFileSystem.java:493)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1868)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1910)
at org.apache.hadoop.fs.FileSystem$4.<init>(FileSystem.java:2072)
at org.apache.hadoop.fs.FileSystem.listLocatedStatus(FileSystem.java:2071)
at org.apache.hadoop.fs.ChecksumFileSystem.listLocatedStatus(ChecksumFileSystem.java:700)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:312)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:274)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:396)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:310)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:327)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:200)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1570)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1567)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1567)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1588)
at com.hadoop.FlowCountDriver.main(FlowCountDriver.java:48)
解决办法:
在idea上连按两次shift,弹出搜索NativeIO这个类
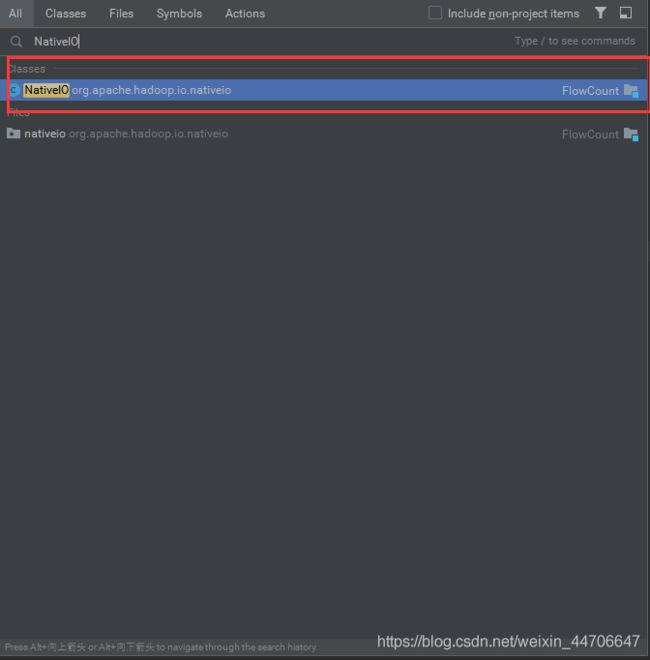
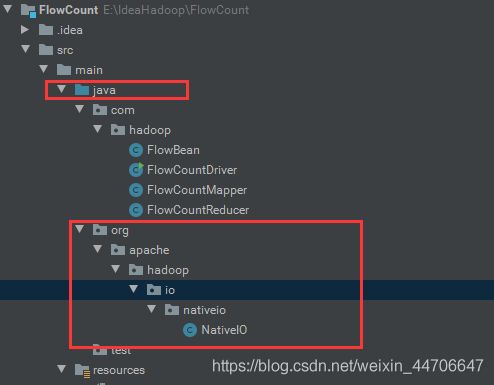
复制这个的代码,因为我们要更改里面的源代码,但是源文件是只读的,所以在java的根目录下创建和源代码中NativeIO相同路径相同的类,修改其中的代码片段:
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
return true; //修改的部分
}
3.报空指针异常错误
检查map或者reducer阶段的输入输出数据类型
4.报文件已经存在错误
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/f:/output already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:164)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:277)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:143)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1570)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1567)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1567)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1588)
at com.hadoop.FlowCountDriver.main(FlowCountDriver.java:48)
解决办法:删除指定路径的输出文件夹即可