Apache Hudi 从入门到放弃(1) —— Hudi的初步尝试
写在开始
- 本篇内容主要是分享一下如何通过Flink Sql 流式的读写Hudi表,也会说说我对Hudi的理解
- IDE选择的是Zeppelin,环境配置可以参考一下我这篇博客
环境准备
-
代码编译
这里我们使用的是Master分支的Hudi进行编译git clone https://github.com/apache/hudi.git # 我使用的是scala版本为2.11的Flink,如果是2.12的scala,请在下面语句的最后加上 -Pscala-2.12 -Dscala-2.12 mvn clean install -s $MAVEN_HOME/conf/settings.xml -DskipTests # 编译完成之后,packaging/hudi-flink-bundle/target/hudi-flink-bundle_2.11-0.9.0-SNAPSHOT.jar 就是要放到我们环境里面的Jar包 -
Jar包配置
在使用Zeppelin进行Flink X Hudi的开发时,如果你使用flink.execution.jars的方式加载Hudi的包,那么会有一些问题,不推荐这样使用。如图所示

这里我是建完Hudi表,然后向表中插入数据的时候抛出的异常
Caused by: java.lang.ClassNotFoundException: org.apache.hudi.common.metrics.LocalRegistry按理说这根本不可能,但是如果加载这个类的加载器,和执行这段代码的类加载器不一样,那么就会有这样的问题,所以我建议还是简单粗暴的将hudi-flink-bundle_2.11-0.9.0-SNAPSHOT.jar这个包放在${FLINK_HOME}/lib下面 -
继续踩坑
在环境配置完成之后,我们自然需要去简单的验证一下功能,于是我们建了个表
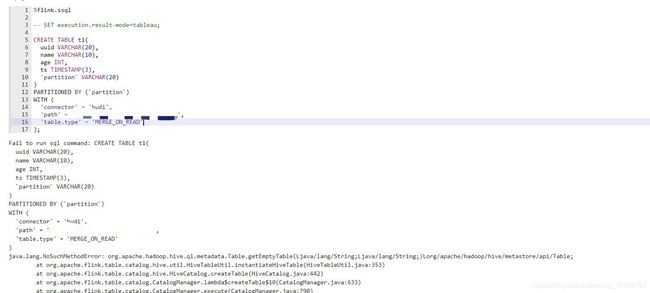
又出问题了,不过这次这个问题很好解决,在
packaging/hudi-flink-bundle/pom.xml的第164行插入
org.apache.hadoop.hive.ql. ${flink.bundle.hive.shade.prefix}org.apache.hadoop.hive.ql.
然后重新打包就行,这个BUG我已经提PR了,当我这篇文章发出去的时候,应该已经合并到Master分支了,到时候大家就不会有这个问题了
这里简单的和大家说一下如何处理这种包冲突的问题- 在
${FLINK_HOME}/lib下执行grep -w 'com.example.class' *看看是否有Jar有重复的类,如果有多个结果直接Vim每个Jar包,然后再重新搜索你的类,看看类名是否完全一致。如果确实存在多个Jar中有多个同名类,那么有两种解决方式- 自己手动进行排包,利用
mvn dependency:tree或者Idea中的插件Maven Helper进行排包 - 通过打shade包,来对同名类进行重命名处理,也就是我上面的处理方案,至于什么是shade包,可以看这里
- 自己手动进行排包,利用
- 在
解决完了环境问题之后,我们接下来开始正式的学习之旅
Flink X Hudi
建表
create database if not exists hudi_db;
use hudi_db;
drop table if exists hudi_test_dijie;
CREATE TABLE hudi_test_dijie(
a varchar,
dt string
)
PARTITIONED BY (`dt`)
WITH (
'connector'= 'hudi',
'path'= 'hdfs:///hudi/hudi_test_dijie',
'table.type'= 'MERGE_ON_READ',
'read.streaming.enabled'= 'true',
-- 'read.streaming.start-commit'= '20210401134557',
'read.streaming.check-interval'= '4'
);
我们来看一下这个语句,有几个特殊的地方来和大家说一下
首先我们先说一下Hudi的一些基本概念
Apache Hudi (pronounced Hoodie) stands for Hadoop Upserts Deletes and Incrementals.
Hudi的4个字母分别代表的是Hadoop Upserts Delete Incrementals
那既然有更新和删除,那么主键就是必不可少的,不然也没法知道更新哪条数据
在Hudi中,每条数据都有HoodieKey唯一标识,HoodieKey由数据的key和数据所属的分区组成
在Flink中我们可以通过指定hoodie.datasource.write.recordkey.field来指定我们的Key是数据中的哪个字段,也可以通过PRIMARY KEY(a) NOT ENFORCED来指定,前者会被后者覆盖
表数据的更新和删除过程在不同类型的Hudi表中有不同的体现,Hudi中目前有两种表类型,分别是
- Copy On Write
- 在数据写入的时候,通过复制旧文件数据并且与新写入的数据进行合并
- Merge On Read
- 在数据写入的时候通过记录Log文件,来标记某条数据到底是Insert还是Update;在进行数据读取的时候,将本批次读取到的数据进行Merge
这里为了方便理解,我概括的比较简单,更多的内容可以参考官方文档
read.streaming.start-commit指的是从哪一个提交位点进行消费
Hudi维护了一个timeline的概念,它记录了在不同时刻对于表提交的操作,这有助于提供表在不同时刻的状态,同时还可以高效的按照时间进行数据查询
read.streaming.check-interval比较简单,代表我们每个多久去检验一次有没有新的操作在timeline上产生
写表
简单的灌几条重复数据进去,顺带验证能否Upsert
INSERT INTO hudi_test_dijie VALUES ('id','2020-04-25',TIMESTAMP '1970-01-01 00:00:01'), ('id','2020-04-25',TIMESTAMP '1970-01-01 00:00:01'), ('id','2020-04-25',TIMESTAMP '1970-01-01 00:00:01'), ('id','2020-04-25',TIMESTAMP '1970-01-01 00:00:01'), ('id','2020-04-25',TIMESTAMP '1970-01-01 00:00:01'), ('id','2020-04-25',TIMESTAMP '1970-01-01 00:00:01'), ('id','2020-04-25',TIMESTAMP '1970-01-01 00:00:01')
然后我们在Flink的Web Ui上观察一下任务
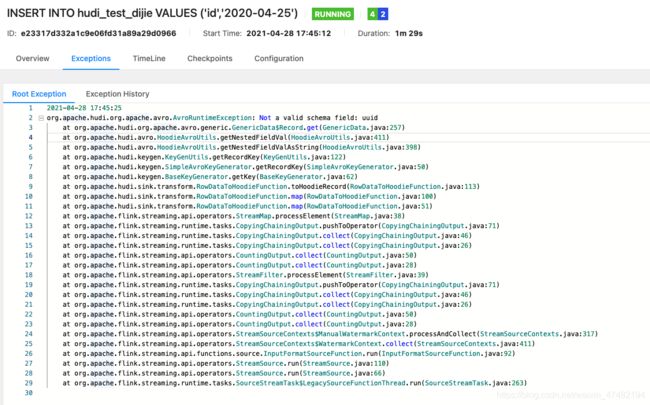
报错了,可这次报错看不懂了,哪来的uuid这个字段?我们并没有在DDL中指定这个,莫慌,我们用IDE打开Hudi的源码一探究竟
先看看异常的堆栈信息,从这条日志信息at org.apache.flink.streaming.api.operators.StreamMap.processElement(StreamMap.java:38)可以看出来,是Flink在处理每条数据的时候抛出的异常,于是我们到源码中的Hudi-Flink模块,搜索uuid

从描述中能看出来,是为了组装我们前面说的HoodieKey,从数据中取uuid这个字段,而我们在进行表定义的时候,并没有这个字段,难怪会抛出异常。
再看一下这个字段在哪被引用过
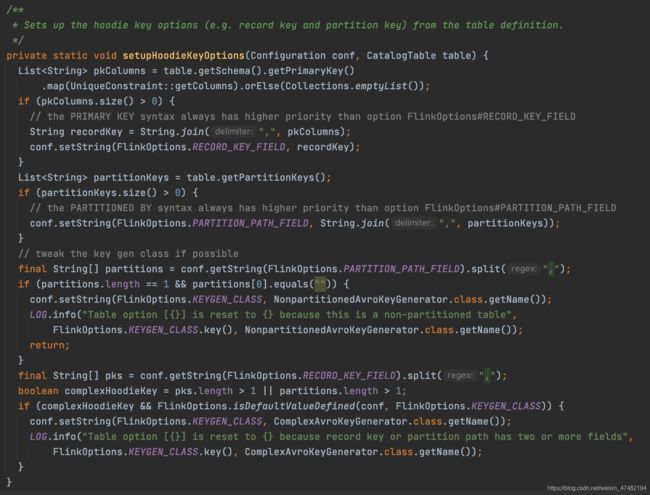
可以看出来,会先取出表定义的主键,如果主键不为空,则用主键组成的联合字段去替换uuid,如果为空就还是uuid
所以接下来,我们重新建一下有主键的表
create database if not exists hudi_db;
use hudi_db;
drop table if exists hudi_test_dijie;
CREATE TABLE hudi_test_dijie(
a varchar,
dt string,
PRIMARY KEY(a) NOT ENFORCED
)
PARTITIONED BY (`dt`)
WITH (
'connector'= 'hudi',
'path'= 'hdfs:///hudi/hudi_test_dijie',
'table.type'= 'MERGE_ON_READ',
'read.streaming.enabled'= 'true',
-- 'read.streaming.start-commit'= '20210401134557',
'read.streaming.check-interval'= '4',
'write.insert.drop.duplicates' = 'true'
);
然后再执行一下插入语句,依旧报错
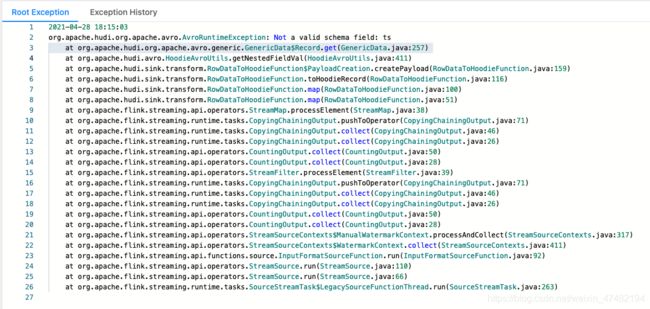
有了上一次的经验,我们很容易定位到问题

当多条数据Key相同需要做预合并时,我们需要根据一个字段来确定哪条数据是新数据哪条是旧数据,
再重新建一次表,这次加上ts字段
create database if not exists hudi_db;
use hudi_db;
drop table if exists hudi_test_dijie;
CREATE TABLE hudi_test_dijie(
a varchar,
dt string,
ts TIMESTAMP(3),
PRIMARY KEY(a) NOT ENFORCED
)
PARTITIONED BY (`dt`)
WITH (
'connector'= 'hudi',
'path'= 'hdfs:///hudi/hudi_test_dijie',
'table.type'= 'MERGE_ON_READ',
'read.streaming.enabled'= 'true',
-- 'read.streaming.start-commit'= '20210401134557',
'read.streaming.check-interval'= '4',
'write.insert.drop.duplicates' = 'true'
);
这次终于不报错了,那么我们进行下一步
查表
查表的语句很简单
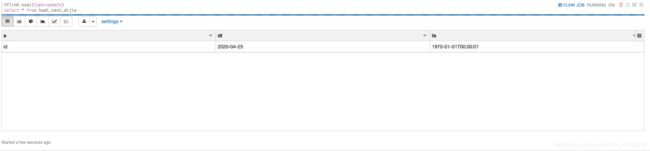
可以看到数据能够正常的查出来,而且数据不存在重复的情况
那,如果我这个时候,将上面的插入语句再执行一次,查出的数据会多吗?
执行一下插入语句,同时再观察一下查询语句的输出结果
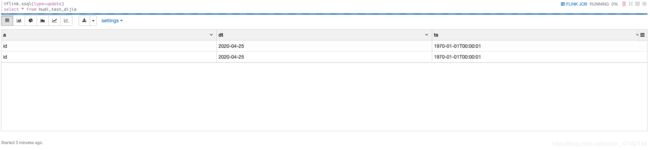
既然Hudi支持Upsert,那为何还是会有重复数据呢?
因为MOR表会在读取最新数据的时候,只会将这一次提交的数据给去重,以前的已经下发的数据,没有办法再去处理;如果是从历史提交位点进行读取数据,那么会将这个位点到最新位点中所有的数据做一次去重
那么COW表呢?很遗憾,目前Hudi Streaming Read只支持MOR表,COW表暂未支持
好了,写到这里,本文的内容已经全部讲完,更多的内容可以多多看看官网,或者等我更新~
写在最后
- 目前Hudi也是支持了Streaming Read&Write,但是美中不足的地方是,Streaming Read只支持对一个批次的数据进行Merge,涉及历史数据无法改变,等待社区更新吧,看看有没有什么新的方案,我个人感觉有两种做法
- 引入类似于
canal-json的Foramt,将数据以canal-json的格式存入Hudi表中,读取的时候再以同样的格式读取,可以利用Flink的能力来进行数据回撤,这种方式比较推荐 - 在HudiSource中引入一个MapState,Key为HoodieKey,Value为该Key最新的一条数据,利用Flink的状态来进行数据回撤;这种的话对Source端压力比较大,毕竟需要引入新的State,同时,何时清理State也比较难定义
- 引入类似于
- 下一篇会写一下Iceberg和Hudi的深度对比,敬请期待!
- 记得点赞!
引用
[1] 官方文档