第二篇数据分析项目的实战,为更好的复习巩固已学知识,话不多说,进入正题。
分析思路

1.数据的清理
导入常用包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示中文
导入数据并读取前5行
df = pd.read_csv("链家二手房.csv", engine = 'python')
df.head()

因为数据列名为中文字符,所有转换为英文字符便于后续处理。
df.rename(columns = {'小区名称': 'village', '户型': 'house_type',
'面积': 'area', '区域': 'district', '朝向': 'orientations', '价格(W)': 'total_price',
'单价(平方米)': 'unit_price', '建筑时间': 'construction_time', '楼层': 'floor'}, inplace = True)
df.head()

查看数据类型和缺失值
df.dtypes
df.isnull().sum()

- orientations字段缺失行数1355,construction_time字段缺失行数6216,
- 这些缺失值在下面对其进行分析时再加以处理
通过以上数据预览发现,floor列的数据含有两层含义,故而将其分成两列便于后续的使用
df1 = pd.concat([df,df['floor'].str.split('/', expand = True)], axis = 1)
df1.head()

- split是分隔符,concat两表的联结,axis = 1 按列维度合并
删除floor列,重新命名新的列名
# 重命名得到的两列
del df1['floor']
df1.rename(columns = {0: 'floor_level', 1: 'floor'}, inplace = True)
df1.tail()

提取construction_time和floor列下字段的数字部分
df1['construction_time'] = df1['construction_time'].str.extract('(\d+)年建') #删除字段文字部分,保留数字
df1['floor'] = df1['floor'].str.extract('(\d+)层')
df1.head()

再查看数据类型
df1.info()

- construction_time和floor是字符串格式,需转化为浮点数格式
df1['construction_time'] = df1['construction_time'].astype(float)
df1['floor'] = df1['floor'].astype(float)
df1.dtypes

查看描述性统计
df1.describe() #查看描述性统计
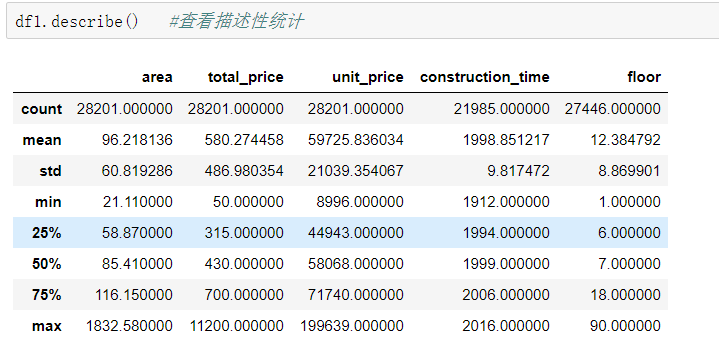
- 由以上描述性统计结果可以得到如下信息:
·1.面积平均值为96㎡,面积中位数为85㎡,说明少数大面积房源拉高了总体平均水平
·2.总价平均值为580万,总价中位数为430万,情况同上,少数总价高的房源拉高了总体平均水平
·3.单价平均值为59725元,单价中位数为58068元,平均值与中位数基本相等,说明房价升高趋势比较线性
2.数据分析:各区域房源数量分布
上海市区共分为三个等级:
1.黄浦区、长宁区;
2.静安区、徐汇区;
3.杨浦区、虹口区、普陀区。
上海郊区共分为三个等级:
1.宝山区、闵行区;
2.松江区、嘉定区、青浦区;
3.奉贤区、崇明区、金山区。
district_number = df1.district.value_counts().reset_index().sort_values(by = 'district', ascending = False)
district_number

plt.figure(figsize=(9, 4))
plt.bar(district_number['index'],district_number.district)
plt.title('各城区房源数量')

- 由以上柱状图可知,除了静安区、崇明区和金山区房源数量不足50套外,其他14个
城区二手房数量均在1300套以上,数量最多的是浦东区,共有2599套
3.各城区总面积与平均面积的分布
3.1各城区总面积分布
由上图可知静安、崇明和金山区房源数量很少,无法代表整体,因此删除三个区数据
dis_list = list(df1.district.drop_duplicates()) #drop_duplicates()去除确定下列的重复列
dis_list.remove('崇明')
dis_list.remove('金山')
dis_list.remove('静安')
dis_list

查看清理后数据前五行
df2 = df1[df1.district.isin(dis_list)]
df2.head()

接下来计算各城区二手房源总面积:
grouped_total_area = df2.groupby('district').sum().sort_values('area', ascending = False).reset_index()
grouped_total_area #这里运用groupby进行分组聚合

通过折线图展示各城区总面积分布趋势
plt.figure(figsize = (12, 5))
grouped_total_area.plot(x = 'district', y = 'area', kind = 'line')
plt.title('各城区总面积分布')

- 如图所示,总面积排名前三的是:青浦、松江和浦东,这得益于它们较大的面积
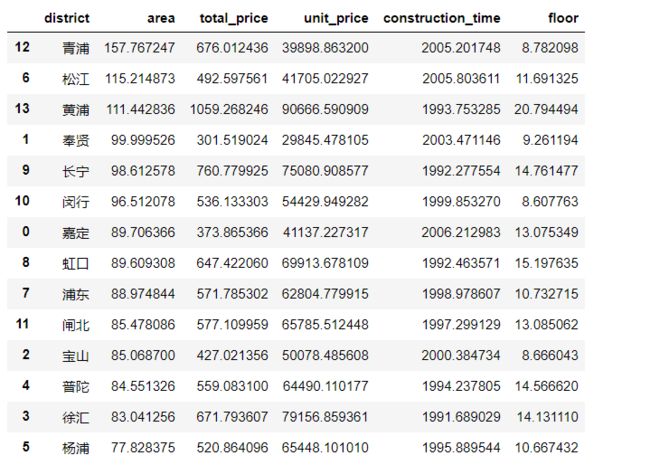
3.2各城区平均面积分布
grouped_area = df2.groupby('district').mean().reset_index().sort_values('area', ascending = False)
grouped_area
同上进行可视化
plt.figure(figsize = (9, 5))
grouped_area.plot(x = 'district', y = 'area', kind = 'line')
#plt.plot(grouped_area.district,grouped_area.area)
plt.title('各城区平均面积分布')

- 以上折线图所示,青浦区总面积和平均面积远远大于其他城区面积,青浦区共有1769套房源,数量较大,不太可能出现异常,故分析可能原因:不在市中心位置,建设成本较低,房屋设计面积较大。
- 各城区总面积和平均面积趋势大致一样,各城区平均面积在[77,116]之间,其中面积在[100,116]之间的为松江、黄埔和金山,面积在[90,100)之间的为奉贤、长宁、闵行和静安,面积在[80,90)之间的为嘉定、虹口、崇明、浦东、闸北、宝山、普陀和徐汇,杨浦区平均面积在77.8㎡
3.3全市平均面积分布
以区间[0,50),[50,100),[100,150),[150,200),[200,+∞)为划分标准,将面积划分为tinysmall、
small、medium、big、huge五个等级,分别对应极小户型、小户型、中等户型、大户型和局大户型。
df2.loc[(df2['area'] >= 0) & (df2['area'] < 50), 'area_level'] = 'tinysmall'
df2.loc[(df2['area'] >= 50) & (df2['area'] < 100), 'area_level'] = 'small'
df2.loc[(df2['area'] >= 100) & (df2['area'] <150), 'area_level'] = 'medium'
df2.loc[(df2['area'] >= 150) & (df2['area'] <200), 'area_level'] = 'big'
df2.loc[(df2['area'] >= 200), 'area_level'] = 'huge'
df2.head()

求出各户型的数量:
grouped_area_level = df2.groupby('area_level').total_price.count().reset_index()
grouped_area_level #求各户型的数量

为了体现各户型分布情况,这里用柱状图
plt.bar(grouped_area_level.area_level, grouped_area_level.total_price)
plt.title('各户型数量分布')

- 由图上可知:
1.平均面积为small的房源数量占据总数的50%,即一半房源的面积在区间[50,100)㎡
2.平均面积为medium的房源数量占据总数的25%,即四分之一的房源面积在区间[100,150)㎡
3.平局面积为tinysmall的房源数量占据总数的17%,即17%的房源面积在区间[0,50)㎡
4.数据分析:各城区总价和单价分布
4.1总价分布
# 把分区后的总价组成一个字典,以便下面将它转化为dataframe
good = dict(list(df2.groupby('district')['total_price']))
# 转化为dataframe
gooddf = pd.DataFrame(good)
# 作出总价箱线图
plt.figure(figsize = (12,5))
gooddf.boxplot()
plt.ylim(0,3000)
plt.title('各城区总价箱线图')

各城区总价平均值排名:
total_price_mean = df2.groupby('district')['total_price'].mean().reset_index().sort_values('total_price')
total_price_mean # 各城区总价平均值排名

- 由以上结果可知:
1.总价No.1的为黄浦区,平均值为1059.3万,总价区间跨越大,总体价格区间为[500,1300]万,中位数小于平均值,故少数价格高的拉高总体平均值的现象比较严重
2.总价No.2的为长宁区,平均值为760.8万,总体价格区间在为[400,1000]万,中位数接近平均值,总价上升比较线性
3.总价No.3的为徐汇区,平均值为671.8万,总体价格区间在为[400, 800]万,中位数小于平均值,故少数价格高的拉高了总体平均值
4.总价No.4的为青浦区,平均值为676.0万,总体价格区间在为[300,750]万,中位数远小于平均值,故少数价格高的拉高了总体平均值的现象比较严重
4.2平均总价分布
df2.total_price.hist(bins = 20)
plt.title('平均总价分布图')

- 房屋总价是一个左凸的直方图,90%的数据集中在[500,1000]的区间,即90%的房源总价在500万到1000万之间,只有约10%的房源属于极高的价格,这个结果符合现实房价分布
4.3 各城区单价分布
good1 = dict(list(df2.groupby('district')['unit_price']))
good1df = pd.DataFrame(good1)
plt.figure(figsize = (12, 5))
good1df.boxplot()
plt.ylim(0,150000)
plt.title('各城区单价分布箱线图')

各城区单价排名:
unit_price_mean = df2.groupby('district')['district', 'unit_price'].mean().reset_index().sort_values('unit_price',ascending = False)
unit_price_mean

- 由以上结果可知:
①单价No.1的是黄浦,平均值为90666元,大体价格区间在[78000,100000]元
②单价No.2的是徐汇,平均值为79156元,大体价格区间在[69111,90000]元
③单价No.3的是长宁,平均值为75081元,大体价格区间在[66000,84000]元
全市单价分布:
df2.unit_price.hist(bins = 20)
plt.title('全市单价分布直方图')

- 单价直方图接近正态分布,该图所示70%的单价集中在区间[30000,90000]元,符合房价的现实分布规律
4.4总价和单价排名前十的小区
对小区进行分组,计算出各小区房源数量,并按照房源数量降序的顺序排序
df3 = df2.groupby('village').total_price.count().reset_index().sort_values('total_price', ascending = False)
df3.head()

- 因为很多小区房源数量太少,其统计值不具有代表性,所以过滤掉房源数量小于20的小区
df4 = df3[df3.total_price > 20]
df4.head(10)

然后再把房源数量大于20的数据提取出来
df5 = df2[df2.village.isin(df4.village)]
df5.head()

4.5计算总价排名前15的小区
对小区进行分组,计算出各小区房源数量,并按照房源数量降序的顺序排序
totalp_village = df5.groupby('village').total_price.mean().sort_values(ascending = False).reset_index().head(15)
totalp_village

展示排名前15小区的平局总价柱状图:
plt.figure(figsize=(20,4))
plt.bar(totalp_village.village,totalp_village.total_price)
plt.title('平均总价排名前15的小区')

- 总价排名前15的小区如图所示,第一名是翠湖天地御苑,平均总价超过了4000万,是第二名尚海湾豪庭的两倍,经查询了解到,该小区位于上海市心脏地带,真是朱甍碧瓦
4.6计算单价排名前十五的小区
totalp_village1 = df5.groupby('village').unit_price.mean().sort_values(ascending = False).head(15).reset_index()
totalp_village1

展示排名前15小区单价柱状图
plt.figure(figsize = (20,5))
plt.bar(totalp_village1.village,totalp_village1.unit_price)
plt.title('平均单价排名前15的小区')

- 由上图可知,排名前三位的小区分别是翠湖天地御苑、东方曼哈顿和融创滨江壹号院,
翠湖天地御苑的平均单价最高,超过了150000元,高于排名第二的东方曼哈顿近40000元
5.房价与户型、楼层、朝向、建筑年代的关系
5.1房价与户型的关系
按户型进行分组,计算出每个户型的房源数量,过滤掉房源数量小于100的户型
grouped_house_type = df2.groupby('house_type').total_price.count().sort_values(ascending = False).reset_index()
grouped_house_type2 = grouped_house_type.loc[grouped_house_type.total_price>100]
grouped_house_type2

plt.figure(figsize = (10, 5))
plt.bar(grouped_house_type2.house_type,grouped_house_type2.total_price)
plt.title('各户型数量柱状图')

户型与房屋均价的柱状图
df6 = df2[df2.house_type.isin(grouped_house_type2.house_type)]
df6.head()

grouped_house_type3 = df6.groupby('house_type').unit_price.mean().sort_values(ascending = False).reset_index()
grouped_house_type3

plt.figure(figsize=(15,5))
plt.bar(grouped_house_type3.house_type,grouped_house_type3.unit_price)
plt.title('户型-房屋均价图')

- 如图所示,单价排名前三的户型分别是1室2厅、2室0厅、1室0厅;可以看出,小户型的房屋比较受欢迎,因为其总价比较低,经济压力较小,故而成为热门户型,这也导致了这些户型的价格上涨,使得小户型的房屋单价高于大户型的房屋。
5.2 房价与楼层的关系
计算各个楼层等级的房源数量,注意这里是按照地区高中低区划分的,并不是按照floor划分的
a_list = ['高区','中区', '低区']
df7 = df2[df2.floor_level.isin(a_list)]
grouped_floor_level = df7.groupby('floor_level').unit_price.count().reset_index()
grouped_floor_level.head()

plt.title('楼层等级-数量')
plt.bar(grouped_floor_level.floor_level, grouped_floor_level.unit_price)

- 由上图可知,低、中、高区的房源数量基本相等,都在8000套以上,其中高区最多,数量超过了10000套
计算各楼层等级的平均单价和平均总价平均单价
grouped_floor_level1 = df7.groupby('floor_level').unit_price.mean().reset_index()
grouped_floor_level1

plt.title('楼层等级-平均单价')
plt.bar(grouped_floor_level1.floor_level, grouped_floor_level1.unit_price)

如图所示,低、中、高区的楼层平均单价在6万元附近
平均总价
grouped_floor_level2 = df7.groupby('floor_level').total_price.mean().reset_index()
grouped_floor_level2

plt.title('楼层等级-平均总价')
plt.bar(grouped_floor_level2.floor_level, grouped_floor_level2.total_price)

- 如图所示,低、中、高区楼层平均总价均超过500万,其中低区总价最高,达到590万
查看缺失值
df2.isnull().sum()

对缺失值进行处理
# 填充floor列中的空值为999
df2.floor = df2.floor.fillna('999')
# 找出floor列中值为999的行号
c_list = df2[df2.floor == '999'].index.tolist()
# 删除上面查找到的行
df8 = df2.drop(c_list)
df8.isnull().sum()

计算楼层平均单价排名前15的
df2.groupby('floor').unit_price.mean().sort_values(ascending = False).reset_index().head(15)

展示平均单价的波动趋势:
plt.figure(figsize = (15,5))
df2.groupby('floor').unit_price.mean().plot()
plt.title('楼层数-单价')

- 由上图分析可知,随着楼层数的增加,房价也随之升高;在37层之前,房价随楼层数增加而增加的趋势比较线性,但是之后房价随楼层数递增的趋势波动很大,可能的原因是楼层超过40的住宅数量较少,而数据量也相对较少,容易产生误差。
5.3房价与朝向的关系
# 查看房屋朝向
df2.orientations.drop_duplicates().values.tolist()

根据朝向构建新的列表
# 根据朝向重新构成一个列表
b_list = list(['朝东','朝东北', '朝东南', '朝东西', '朝北','朝南', '朝南北', '朝西', '朝西北', '朝西南'])
df8 = df2[df2.orientations.isin(b_list)]
grouped_orientations = df8.groupby('orientations').unit_price.mean().sort_values(ascending = False).reset_index()
grouped_orientations

plt.figure(figsize=(12,5))
plt.bar(grouped_orientations.orientations,grouped_orientations.unit_price)
plt.title('朝向-单价')

- 由上图可知,朝向对房价有一定的影响,朝向南面(南、东南、西南)的房子总价会高一些,因为南面的房屋采光会比较好,而南北通透的房子单价会比其他朝向的要高一些。
5.4房价与建筑年代的关系
df2.isnull().sum()

# 缺失值处理
df2.construction_time = df2.construction_time.fillna('000')
d_list = df2[df2.construction_time == '000'].index.tolist()
df9 = df2.drop(d_list)

由折线图展示各年份建筑房屋数量
plt.figure(figsize=(15,5))
df9.groupby('construction_time').unit_price.count().plot()
plt.title('建筑时间-数量')

- 以上折线图呈现右侧双峰形态,即分别在1995年和2005年左右出现了两次房屋修建高峰期,这期间房屋数量激增。
计算各个年份平均总价,作出其折线图
plt.figure(figsize = (15,5))
df9.groupby('construction_time').total_price.mean().plot()
plt.title('建筑时间-平均总价图')

计算各个年份平均单价
plt.figure(figsize=(15,5))
df9.groupby('construction_time').unit_price.mean().plot()
plt.title('建筑时间-平均单价图')

- 由以上分析可知:
- 以上平均总价与建筑时间的趋势和平均单价与建筑时间的趋势大致一样,都呈现左侧单峰形态。从1920年到1950年间建造的房屋,其总价和单价均高于之后建造的房屋,分析其原因:从1920年到1950年间建造的房屋,因为建造时间早,其建筑的位置处于现在上海市中心地区,因为其土地、经济、政治等因素,导致现在的高房价。
- 从2015年以来修建的房屋呈现突然上升趋势,这也和目前房价不断升高的趋势相契合,这表明房价在短时间内不会出现大的下跌现象,是否会出现下一个房价高峰,还需要考量其他因素进行观测分析。