pytorch-线性回归模型
线性回归模型
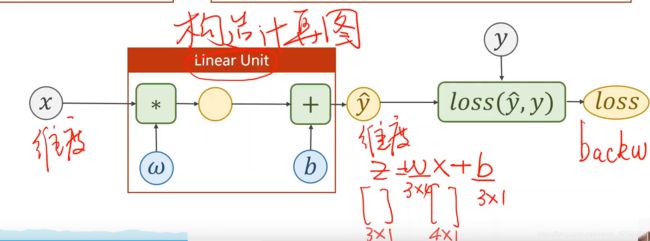
构造损失函数
构造计算图
深度神经网络并没有太多的局部极小值,但是会有鞍点,鞍点就会导致没有梯度停止更新
梯度下降的三种方式:
- SGD(随机梯度下降):每次更新只用一个样本,数据中会有噪声,会另训练离开鞍点,如果GD更新的话,进入鞍点就出不来了
用SGD的话,loss function输出要进行平滑(否则看到的数据会跳动) - GD(梯度下降):用所有样本的误差进行梯度更新。设定epoch次数。SGD有两个循环(每个样本都要遍历)而GD有一个循环
- mini-batch(常用方法)将数据分成一小块一小块的(折中方式)
效率问题
GD在更新计算损失的时候可以并行运算,因为每个样本可以直接加,上一个样本和下一个样本没有关联。运算快
SGD在更新计算损失的时候 不 可以并行运算,因为上一个样本更新和下一个样本更新有关联。运算慢
问题
为什么跑深度学习模型的时候,batch大了显存不够?
GPU进行并行计算,batch大了 显存就不够了,GPU进行并行计算,一个batch的数据一起计算
import torch
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
构造模型的时候使用的都是【类的形式】
ython中的函数是一级对象。这意味着Python中的函数的引用可以作为输入传递到其他的函数/方法中,并在其中被执行。
而Python中类的实例(对象)可以被当做函数对待。也就是说,我们可以将它们作为输入传递到其他的函数/方法中并调用他们,正如我们调用一个正常的函数那样。而类中__call__()函数的意义正在于此。为了将一个类实例当做函数调用,我们需要在类中实现__call__()方法。也就是我们要在类中实现如下方法:def call(self, *args)。这个方法接受一定数量的变量作为输入。
假设x是X类的一个实例。那么调用x.call(1,2)等同于调用x(1,2)。这个实例本身在这里相当于一个函数
call函数能使实例能够直接调用 ,当你把实例当成函数来调用的时候,会自动找到call函数,并执行。(继承类也可以)
args 和 ** kwargs的用法的
def func(*arg,**kwargs):
print(arg)
print(kwargs)
func(1,2,4,3,x=4,x=5)
运行结果:
(1,2,4,3)
{
'x':3,'y'=5}
*args 会将直接输入的变量定义为一个数组
kwargs会将直接有变量的定义为一个词典
class LinearModel(torch.nn.Module):
def __init__(self): #构造函数不传参数
super(LinearModel,self).__init__()#将子类和父类联系在一起
self.linear = torch.nn.Linear(1,1) #构造一个linear对象
def forward(self,x):
y_pred = self.linear(x) #直接用实例进行调用,计算 call函数的作用
return y_pred
在这里插入图片描述
构造损失函数
一般只考虑size_average 而不考虑reduce 降维

随机梯度下降
model.parameters():我们模型中的参数没有定义相应的权重,只有linear的成员有两个权重,parameters就会检查model里面的所有成员,如果成员里面有响应的权重,那么就加到训练集合中
lr:学习率
线性回归步骤:
1.求出预测值 2.计算损失 3.反向传播(求梯度,之前要梯度清零,固定的) 4.更新
model = LinearModel()
y = model(torch.Tensor(1))#不能直接输入数字 得输入张量数据
criterion = torch.nn.MSELoss(reduction='sum') #样本是否要求均值 一般不求 每一批样本都不求 那么贡献相同
#这里和老版的有不一样的地方 老版是size_average = False
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(1000):
y_pred = model(x_data) #进行预测 (model中的前馈函数)
loss = criterion(y_pred,y_data) #计算损失
print(epoch,loss) # loss是一个对象 但是在打印的时候自动调用__str__()函数 ,所以打印的时候
#不会出错
optimizer.zero_grad() #把所有训练的权重归零
loss.backward() # 反向传播 ? 这一步是求导数么?对就是求导数
optimizer.step() # 根据 所有的梯度和学习率进行更新
# Output weight and bias
print('w = ',model.linear.weight.item()) #item的目的是让输出权重是一个数值而不是张量矩阵结构
print('b = ',model.linear.bias.item())
# Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ',y_test.data)
-
问题1:forward 计算的时候权重是默认的么?
对的,我们调用了linear 类 里面有权重 ,我认为 也可以自定义初始权重 -
问题2:backward()是求导函数?
对 -
问题3:为什么每次更新都要optimizer.zero_grad() 来清除梯度?
因为在每一个batch时毫无疑问并不需要将两个batch的梯度混合起来累积 -
构建模型的步骤:
1.准备数据
2.设计模型类,从cnn.Model继承
3.构造损失和优化器
4.循环训练 forward backward update