Cloudera Engineering Blog 翻译:Offset Management For Apache Kafka With Apache Spark Streaming
Spark Streaming 应用从Kafka中获取信息是一种常见的场景。从Kafka中读取持续不断的数据将有很多优势,例如性能好、速度快。然而,用户必须管理Kafka Offsets保证Spark Streaming应用挂掉之后仍然能够正确地读取数据。在这一篇文章,我们将来讨论如何管理offset。
目录
- Offset管理概述
- 将Offsests存储在外部系统
- Spark Streaming checkpoints
- 将offsets存储在HBase中
- 将offsets存储到 ZooKeeper中
- 将offsets存储到Kafka 本身
- 其他方式
- 总结
Offset管理概述
Spark Streaming集成了Kafka允许用户从Kafka中读取一个或者多个topic的数据。一个Kafka topic包含多个存储消息的分区(partition)。每个分区中的消息是顺序存储,并且用offset(可以认为是位置)来标记消息。开发者可以在他的Spark Streaming应用中通过offset来控制数据的读取位置,但是这需要好的offset的管理机制。
Offsets管理对于保证流式应用在整个生命周期中数据的连贯性是非常有益的。举个例子,如果在应用停止或者报错退出之前没有将offset保存在持久化数据库中,那么offset rangges就会丢失。更进一步说,如果没有保存每个分区已经读取的offset,那么Spark Streaming就没有办法从上次断开(停止或者报错导致)的位置继续读取消息。
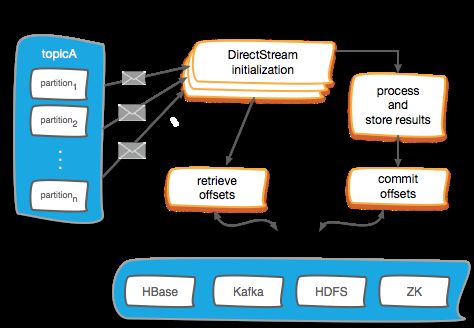
上面的图描述通常的Spark Streaming应用管理offset流程。Offsets可以通过多种方式来管理,但是一般来说遵循下面的步骤:
- 在 Direct DStream初始化的时候,需要指定一个包含每个topic的每个分区的offset用于让Direct DStream从指定位置读取数据。
- offsets就是步骤4中所保存的offsets位置
- 读取并处理消息
- 处理完之后存储结果数据
- 用虚线圈存储和提交offset只是简单强调用户可能会执行一系列操作来满足他们更加严格的语义要求。这包括幂等操作和通过原子操作的方式存储offset。
- 最后,将offsets保存在外部持久化数据库如 HBase, Kafka, HDFS, and ZooKeeper中
不同的方案可以根据不同的商业需求进行组合。Spark具有很好的编程范式允许用户很好的控制offsets的保存时机。认真考虑以下的情形:一个Spark Streaming 应用从Kafka中读取数据,处理或者转换数据,然后将数据发送到另一个topic或者其他系统中(例如其他消息系统、Hbase、Solr、DBMS等等)。在这个例子中,我们只考虑消息处理之后发送到其他系统中。
将Offsests存储在外部系统
在这一章节中,我们将来探讨一下不同的外部持久化存储选项。
为了更好地理解这一章节中提到的内容,我们先来做一些铺垫。如果是使用spark-streaming-kafka-0-10,那么我们建议将enable.auto.commit设为false。这个配置只是在这个版本生效,enable.auto.commit如果设为true的话,那么意味着offsets会按照auto.commit.interval.ms中所配置的间隔来周期性自动提交到Kafka中。在Spark Streaming中,将这个选项设置为true的话会使得Spark应用从kafka中读取数据之后就自动提交,而不是数据处理之后提交,这不是我们想要的。所以为了更好地控制offsets的提交,我们建议将enable.auto.commit设为false。
Spark Streaming checkpoints
使用Spark Streaming的checkpoint是最简单的存储方式,并且在Spark 框架中很容易实现。Spark Streaming checkpoints就是为保存应用状态而设计的,我们将路径这在HDFS上,所以能够从失败中恢复数据。
对Kafka Stream 执行checkpoint操作使得offset保存在checkpoint中,如果是应用挂掉的话,那么SparkStreamig应用功能可以从保存的offset中开始读取消息。但是,如果是对Spark Streaming应用进行升级的话,那么很抱歉,不能checkpoint的数据没法使用,所以这种机制并不可靠,特别是在严格的生产环境中,我们不推荐这种方式。
将offsets存储在HBase中
HBase可以作为一个可靠的外部数据库来持久化offsets。通过将offsets存储在外部系统中,Spark Streaming应用功能能够重读或者回放任何仍然存储在Kafka中的数据。
根据HBase的设计模式,允许应用能够以rowkey和column的结构将多个Spark Streaming应用和多个Kafka topic存放在一张表格中。在这个例子中,表格以topic名称、消费者group id和Spark Streaming 的batchTime.milliSeconds作为rowkey以做唯一标识。尽管batchTime.milliSeconds不是必须的,但是它能够更好地展示历史的每批次的offsets。表格将存储30天的累积数据,如果超出30天则会被移除。下面是创建表格的DDL和结构
DDL
create 'stream_kafka_offsets', {NAME=>'offsets', TTL=>2592000}
RowKey Layout:
row: ::
column family: offsets
qualifier:
value:
对每一个批次的消息,使用saveOffsets()将从指定topic中读取的offsets保存到HBase中
/*
Save offsets for each batch into HBase
*/
def saveOffsets(TOPIC_NAME:String,GROUP_ID:String,offsetRanges:Array[OffsetRange],
hbaseTableName:String,batchTime: org.apache.spark.streaming.Time) ={
val hbaseConf = HBaseConfiguration.create()
hbaseConf.addResource("src/main/resources/hbase-site.xml")
val conn = ConnectionFactory.createConnection(hbaseConf)
val table = conn.getTable(TableName.valueOf(hbaseTableName))
val rowKey = TOPIC_NAME + ":" + GROUP_ID + ":" +String.valueOf(batchTime.milliseconds)
val put = new Put(rowKey.getBytes)
for(offset <- offsetRanges){
put.addColumn(Bytes.toBytes("offsets"),Bytes.toBytes(offset.partition.toString),
Bytes.toBytes(offset.untilOffset.toString))
}
table.put(put)
conn.close()
}
在执行streaming任务之前,首先会使用getLastCommittedOffsets()来从HBase中读取上一次任务结束时所保存的offsets。该方法将采用常用方案来返回kafka topic分区offsets。
情形1:Streaming任务第一次启动,从zookeeper中获取给定topic的分区数,然后将每个分区的offset都设置为0,并返回。
情形2:一个运行了很长时间的streaming任务停止并且给定的topic增加了新的分区,处理方式是从zookeeper中获取给定topic的分区数,对于所有老的分区,offset依然使用HBase中所保存,对于新的分区则将offset设置为0。
情形3:Streaming任务长时间运行后停止并且topic分区没有任何变化,在这个情形下,直接使用HBase中所保存的offset即可。
在Spark Streaming应用启动之后如果topic增加了新的分区,那么应用只能读取到老的分区中的数据,新的是读取不到的。所以如果想读取新的分区中的数据,那么就得重新启动Spark Streaming应用。
/*
Returns last committed offsets for all the partitions of a given topic from HBase in following cases.
*/
def getLastCommittedOffsets(TOPIC_NAME:String,GROUP_ID:String,hbaseTableName:String,
zkQuorum:String,zkRootDir:String,sessionTimeout:Int,connectionTimeOut:Int):Map[TopicPartition,Long] ={
val hbaseConf = HBaseConfiguration.create()
val zkUrl = zkQuorum+"/"+zkRootDir
val zkClientAndConnection = ZkUtils.createZkClientAndConnection(zkUrl, sessionTimeout,connectionTimeOut)
val zkUtils = new ZkUtils(zkClientAndConnection._1, zkClientAndConnection._2,false)
val zKNumberOfPartitionsForTopic = zkUtils.getPartitionsForTopics(Seq(TOPIC_NAME)).get(TOPIC_NAME).toList.head.size
zkClientAndConnection._1.close()
zkClientAndConnection._2.close()
//Connect to HBase to retrieve last committed offsets
val conn = ConnectionFactory.createConnection(hbaseConf)
val table = conn.getTable(TableName.valueOf(hbaseTableName))
val startRow = TOPIC_NAME + ":" + GROUP_ID + ":" +
String.valueOf(System.currentTimeMillis())
val stopRow = TOPIC_NAME + ":" + GROUP_ID + ":" + 0
val scan = new Scan()
val scanner = table.getScanner(scan.setStartRow(startRow.getBytes).setStopRow(
stopRow.getBytes).setReversed(true))
val result = scanner.next()
var hbaseNumberOfPartitionsForTopic = 0 //Set the number of partitions discovered for a topic in HBase to 0
if (result != null){
//If the result from hbase scanner is not null, set number of partitions from hbase
to the number of cells
hbaseNumberOfPartitionsForTopic = result.listCells().size()
}
val fromOffsets = collection.mutable.Map[TopicPartition,Long]()
if(hbaseNumberOfPartitionsForTopic == 0){
// initialize fromOffsets to beginning
for (partition <- 0 to zKNumberOfPartitionsForTopic-1){
fromOffsets += (new TopicPartition(TOPIC_NAME,partition) -> 0)
}
} else if(zKNumberOfPartitionsForTopic > hbaseNumberOfPartitionsForTopic){
// handle scenario where new partitions have been added to existing kafka topic
for (partition <- 0 to hbaseNumberOfPartitionsForTopic-1){
val fromOffset = Bytes.toString(result.getValue(Bytes.toBytes("offsets"),
Bytes.toBytes(partition.toString)))
fromOffsets += (new TopicPartition(TOPIC_NAME,partition) -> fromOffset.toLong)
}
for (partition <- hbaseNumberOfPartitionsForTopic to zKNumberOfPartitionsForTopic-1){
fromOffsets += (new TopicPartition(TOPIC_NAME,partition) -> 0)
}
} else {
//initialize fromOffsets from last run
for (partition <- 0 to hbaseNumberOfPartitionsForTopic-1 ){
val fromOffset = Bytes.toString(result.getValue(Bytes.toBytes("offsets"),
Bytes.toBytes(partition.toString)))
fromOffsets += (new TopicPartition(TOPIC_NAME,partition) -> fromOffset.toLong)
}
}
scanner.close()
conn.close()
fromOffsets.toMap
}
当我们获取到offsets之后我们就可以创建一个Kafka Direct DStream
val fromOffsets= getLastCommittedOffsets(topic,consumerGroupID,hbaseTableName,zkQuorum,
zkKafkaRootDir,zkSessionTimeOut,zkConnectionTimeOut)
val inputDStream = KafkaUtils.createDirectStream[String,String](ssc,PreferConsistent,
Assign[String, String](fromOffsets.keys,kafkaParams,fromOffsets))
在完成本批次的数据处理之后调用saveOffsets()保存offsets.
/*
For each RDD in a DStream apply a map transformation that processes the message.
*/
inputDStream.foreachRDD((rdd,batchTime) => {
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetRanges.foreach(offset => println(offset.topic,offset.partition, offset.fromOffset,
offset.untilOffset))
val newRDD = rdd.map(message => processMessage(message))
newRDD.count()
saveOffsets(topic,consumerGroupID,offsetRanges,hbaseTableName,batchTime)
})
你可以到HBase中去查看不同topic和消费者组的offset数据
hbase(main):001:0> scan 'stream_kafka_offsets', {REVERSED => true}
ROW COLUMN+CELL
kafkablog2:groupid-1:1497628830000 column=offsets:0, timestamp=1497628832448, value=285
kafkablog2:groupid-1:1497628830000 column=offsets:1, timestamp=1497628832448, value=285
kafkablog2:groupid-1:1497628830000 column=offsets:2, timestamp=1497628832448, value=285
kafkablog2:groupid-1:1497628770000 column=offsets:0, timestamp=1497628773773, value=225
kafkablog2:groupid-1:1497628770000 column=offsets:1, timestamp=1497628773773, value=225
kafkablog2:groupid-1:1497628770000 column=offsets:2, timestamp=1497628773773, value=225
kafkablog1:groupid-2:1497628650000 column=offsets:0, timestamp=1497628653451, value=165
kafkablog1:groupid-2:1497628650000 column=offsets:1, timestamp=1497628653451, value=165
kafkablog1:groupid-2:1497628650000 column=offsets:2, timestamp=1497628653451, value=165
kafkablog1:groupid-1:1497628530000 column=offsets:0, timestamp=1497628533108, value=120
kafkablog1:groupid-1:1497628530000 column=offsets:1, timestamp=1497628533108, value=120
kafkablog1:groupid-1:1497628530000 column=offsets:2, timestamp=1497628533108, value=120
4 row(s) in 0.5030 seconds
hbase(main):002:0>
代码示例用的以下的版本
| GroupID | ArtifactID | Version |
|---|---|---|
| org.apache.spark | spark-streaming_2.11 | 2.1.0.cloudera1 |
| org.apache.spark | spark-streaming-kafka-0-10_2.11 | 2.1.0.cloudera1 |
示例代码的github
将offsets存储到 ZooKeeper中
在Spark Streaming连接Kafka应用中使用Zookeeper来存储offsets也是一种比较可靠的方式。
在这个方案中,Spark Streaming任务在启动时会去Zookeeper中读取每个分区的offsets。如果有新的分区出现,那么他的offset将会设置在最开始的位置。在每批数据处理完之后,用户需要可以选择存储已处理数据的一个offset或者最后一个offset。此外,新消费者将使用跟旧的Kafka 消费者API一样的格式将offset保存在ZooKeeper中。因此,任何追踪或监控Zookeeper中Kafka Offset的工具仍然生效的。
初始化Zookeeper connection来从Zookeeper中获取offsets
val zkClientAndConnection = ZkUtils.createZkClientAndConnection(zkUrl, sessionTimeout, connectionTimeout)
val zkUtils = new ZkUtils(zkClientAndConnection._1, zkClientAndConnection._2, false)
Method for retrieving the last offsets stored in ZooKeeper of the consumer group and topic list.
def readOffsets(topics: Seq[String], groupId:String):
Map[TopicPartition, Long] = {
val topicPartOffsetMap = collection.mutable.HashMap.empty[TopicPartition, Long]
val partitionMap = zkUtils.getPartitionsForTopics(topics)
// /consumers//offsets//
partitionMap.foreach(topicPartitions => {
val zkGroupTopicDirs = new ZKGroupTopicDirs(groupId, topicPartitions._1)
topicPartitions._2.foreach(partition => {
val offsetPath = zkGroupTopicDirs.consumerOffsetDir + "/" + partition
try {
val offsetStatTuple = zkUtils.readData(offsetPath)
if (offsetStatTuple != null) {
LOGGER.info("retrieving offset details - topic: {}, partition: {}, offset: {}, node path: {}", Seq[AnyRef](topicPartitions._1, partition.toString, offsetStatTuple._1, offsetPath): _*)
topicPartOffsetMap.put(new TopicPartition(topicPartitions._1, Integer.valueOf(partition)),
offsetStatTuple._1.toLong)
}
} catch {
case e: Exception =>
LOGGER.warn("retrieving offset details - no previous node exists:" + " {}, topic: {}, partition: {}, node path: {}", Seq[AnyRef](e.getMessage, topicPartitions._1, partition.toString, offsetPath): _*)
topicPartOffsetMap.put(new TopicPartition(topicPartitions._1, Integer.valueOf(partition)), 0L)
}
})
})
topicPartOffsetMap.toMap
}
使用获取到的offsets来初始化Kafka Direct DStream
val inputDStream = KafkaUtils.createDirectStream(ssc, PreferConsistent, ConsumerStrategies.Subscribe[String,String](topics, kafkaParams, fromOffsets))
下面是从ZooKeeper获取一组offsets的方法
注意: Kafka offset在ZooKeeper中的存储路径为/consumers/[groupId]/offsets/topic/[partitionId], 存储的值为offset
def persistOffsets(offsets: Seq[OffsetRange], groupId: String, storeEndOffset: Boolean): Unit = {
offsets.foreach(or => {
val zkGroupTopicDirs = new ZKGroupTopicDirs(groupId, or.topic);
val acls = new ListBuffer[ACL]()
val acl = new ACL
acl.setId(ANYONE_ID_UNSAFE)
acl.setPerms(PERMISSIONS_ALL)
acls += acl
val offsetPath = zkGroupTopicDirs.consumerOffsetDir + "/" + or.partition;
val offsetVal = if (storeEndOffset) or.untilOffset else or.fromOffset
zkUtils.updatePersistentPath(zkGroupTopicDirs.consumerOffsetDir + "/"
+ or.partition, offsetVal + "", JavaConversions.bufferAsJavaList(acls))
LOGGER.debug("persisting offset details - topic: {}, partition: {}, offset: {}, node path: {}", Seq[AnyRef](or.topic, or.partition.toString, offsetVal.toString, offsetPath): _*)
})
}
Kafka 本身
Apache Spark 2.1.x以及spark-streaming-kafka-0-10使用新的的消费者API即异步提交API。你可以在你确保你处理后的数据已经妥善保存之后使用commitAsync API(异步提交 API)来向Kafka提交offsets。新的消费者API会以消费者组id作为唯一标识来提交offsets
将offsets提交到Kafka中
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// some time later, after outputs have completed
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
可以到streaming-kafka-0-10-integration里学习到更多内容
注意: commitAsync()是Spark Streaming集成kafka-0-10版本中的,在Spark文档提醒到它仍然是个实验性质的API并且存在修改的可能性。
其他方式
值得注意的是你也可以将offsets存储到HDFS中。但是将offsets存储到HDFS中并不是一个受欢迎的方式,因为HDFS对已ZooKeeper和Hbase来说它的延迟有点高。此外,将每批次数据的offset存储到HDFS中还会带来小文件的问题
不管理offsets
管理offsets对于Spark Streaming应该用来说并不是必须的。举个例子,像应用存活监控它只需要当前的数据,并不需要通过管理offsets来保证数据的不丢失。这种情形下你完全不需要管理offsets,老的kafka消费者可以将auto.offset.reset设为largest或者smallest,而新的消费者则设置为earliest or latest。
如果你将auto.offset.reset设为smallest (earliest),那么任务会从最开始的offset读取数据,相当于重播所有数据。这样的设置会使得你的任务重启时将该topic中仍然存在的数据再读取一遍。这将由你的消息保存周期来决定你是否会重复消费。
相反地,如果你将auto.offset.reset 设置为largest (latest),那么你的应用启动时会从最新的offset开始读取,这将导致你丢失数据。这将依赖于你的应用对数据的严格性和语义需求,这或许是个可行的方案。
总结
上面我们所讨论的管理offsets的方式将帮助你在Spark Streaming应用中如何有效地控制offsets。这些方法能够帮助用户在持续不断地计算和存储数据应用中更好地面对应用失效和数据恢复的场景。
更多知识请看 Spark 2 Kafka Integration or Spark Streaming + Kafka Integration Guide.
Spark集成Kafka的参考文档