使用colab训练GitHub中的模型——以tensorflow/models为例
使用colab训练GitHub中的模型——以tensorflow/models为例
没有显卡如何训练GitHub中的模型。
1. colab简介
colab全名colaboratory,是google推出的在线代码编辑器,其实就是个在线jupyter笔记本环境,可以免费提供强劲的GPU算力。
colab的使用和google drive是分不开的。可以这样理解,google drive就是硬盘,可以存代码和数据,colab是jupyter笔记本,通过Python或者命令行代码块可以调用硬盘中的代码文件或者直接编写代码段,代码文件可以从硬盘中调用数据。colab文件本身也是一个.ipynb文件,存在google drive之中。
使用colab的前提如下:
- 有一个google账号
- 连接到google drive
这两个前提需要科学上网。
2. 新建colab笔记本
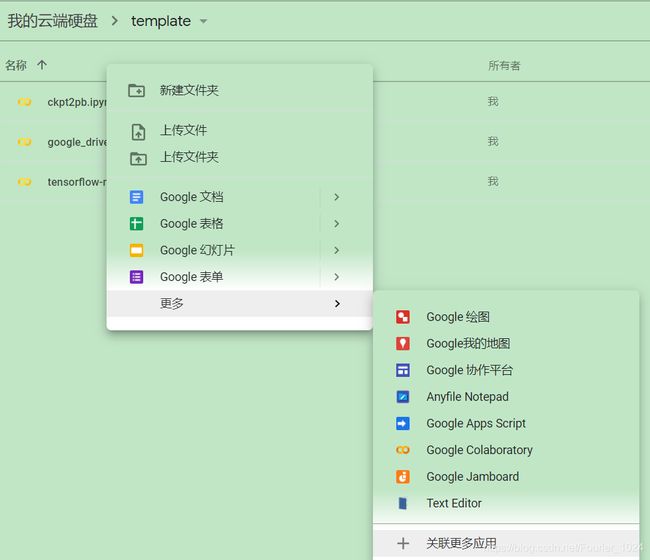
在google drive中右键->更多->关联更多应用,搜索colaboratory添加即可(下图是我已经添加过的,第一次使用需要关联)。关联之后google drive中右键->更多->google colaboratory即可创建colab笔记本。
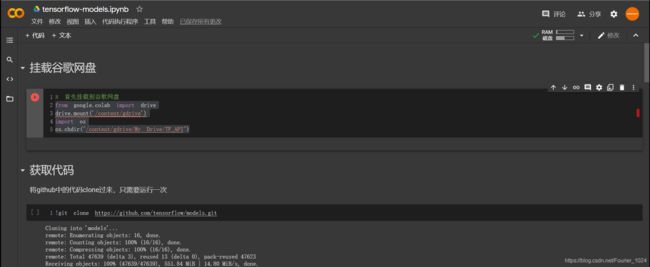
下图为colab笔记本界面。笔记本分为代码块和文本块。单击代码块可以编辑代码,左侧会有一个运行代码按钮。
3. 模型训练
这里我使用的模型为目标检测模型,GitHub地址。
3.1 挂载谷歌网盘
需要将colab和google drive关联起来,后续会将从GitHub下载的模型以及其它数据下载到google drive中。
from google.colab import drive
drive.mount('/content/gdrive')
import os
# test是我网盘下的一个文件夹
os.chdir("/content/gdrive/MyDrive/test")
运行代码,会出现一个连接,点击进去进行google drive授权。将授权后的链接拷贝到下图所示方框中,回车,便连接到google drive了。

这里我是使用的比较小的模型,对网盘容量没太大需求。google drive会免费提供15GB容量,如果有更多的需求,可以求助某宝获取教育账号,教育账号的容量是无限大。
3.2 确定当前工作路径
在挂载google drive之后,需要将想要运行的GitHub代码、模型需要的数据等下载到google drive之中,这需要明确代码、数据在google drive中的存放位置。
确定存放文件的位置,可以使用cd命令,该命令会指定当前工作路径。
cd /content/gdrive/MyDrive/test
在运行代码时,如果需要确定当前工作路径,可以使用!pwd命令.这里test是google drive中的一个文件夹。

colab的命令前一般有个"!“或者”%",很多命令行命令加上一个“!”或者"%"就可以在colab中使用了。(对linux命令不熟,以后一定恶补)
3.3 clone GitHub中的代码
选好位置后使用!git clone命令下载代码。
!git clone https://github.com/tensorflow/models.git
3.4 tensorflow/models模型训练准备
数据下载
使用自己的数据进行训练,对于目标检测,可以将数据标记为VOC的格式。制作VOC格式的数据集有很多文章记录,例如[这篇]。(https://blog.csdn.net/weixin_39750664/article/details/82502302)这里直接使用VOC数据集进行训练。
使用VOC数据集,使用!wget命令下载。(这里下载速度和节点有关系)
%cd VOC/
!wget http://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
!wget http://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
数据解压
我尝试过直接在google drive中解压,发现平时在自己电脑中运行没有差错的解压命令经常会在google drive中出错。当数据集很大时,数量很大的图片、标签文件会发生丢失情况,并且解压速度巨慢。我认为这是colab和google drive的连接不稳定的关系,不能够长时间的大量读取或者写入。
这里将图片和标签数据直接解压到colab中,colab在CPU运行时(后面训练时会换为GPU运行时)下给的磁盘空间还是很大的。
首先新建几个文件夹用于存储解压后的文件。
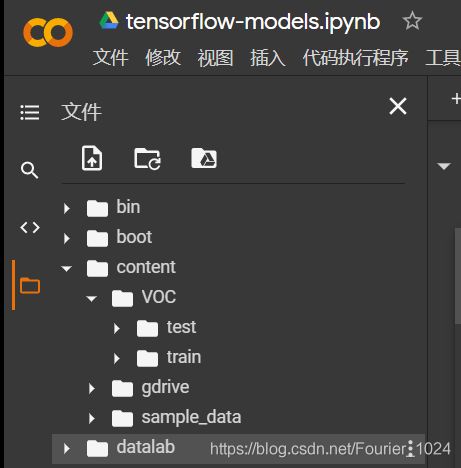
进行解压。
!tar -xvf VOCtrainval_11-May-2012.tar -C /content/VOC/train/
!tar -xvf VOCtest_06-Nov-2007.tar -C /content/VOC/test/
格式转换
tensorflow有着自己的数据输入格式,需要将带标签的图片转换为.record格式。使用刚刚clone的代码中的./models/research/object_detection/dataset_tools/create_pascal_tf_record.py文件将VOC数据集格式的数据转换为.record格式。
调用已有的py文件最重要的便是添加环境变量。
%set_env PYTHONPATH=/content/gdrive/My Drive/TF_API/models/research
调用文件,传入的参数分别是,data_dir:符合VOC数据格式的输入;‘set’:指明是训练集还是测试集,这里加了引号是因为set为关键词,不加会报编译错误;output_path :输出文件路径以及文件名,以.record结尾;year :数据集对应的年份;label_map_path :数据对应的标签,tensorflow models自带VOC标签文件。
%cd /content/gdrive/MyDrive/test
!python ./models/research/object_detection/dataset_tools/create_pascal_tf_record.py \
--data_dir /content/VOC/train//VOCdevkit \
--'set' train \
--output_path ./VOC/pascal_train.record \
--year VOC2012 \
--label_map_path ./models/research/object_detection/data/pascal_label_map.pbtxt
!python ./models/research/object_detection/dataset_tools/create_pascal_tf_record.py \
--data_dir /content/VOC/test//VOCdevkit \
--'set' test \
--output_path ./VOC/pascal_test.record \
--year VOC2007 \
--label_map_path ./models/research/object_detection/data/pascal_label_map.pbtxt
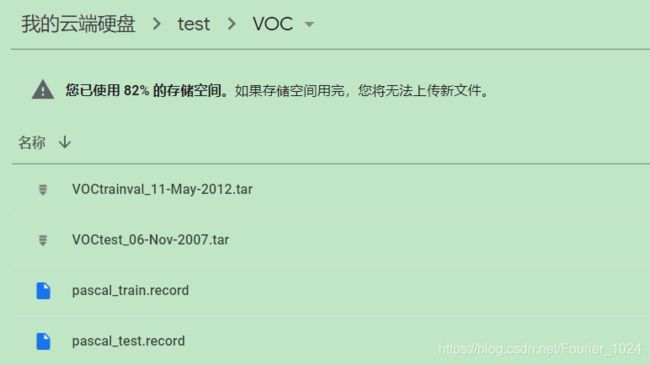
到这里,已经获得了模型需要的输入数据。如下图所示。
下载预训练权重
tensorflow/models为我们提供多种可选模型的同时,还提供了多种模型对应的预训练权重。在此下载
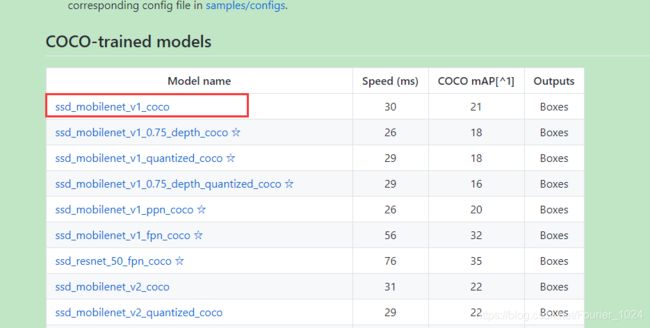
3.5 tensorflow/models模型训练
训练使用的文件为./models/research/object_detection/legacy/train.py。这一文件的输入参数有两个,一个是模型输出的存储路径,这个可以自己指定。另一个是配置文件的路径。
配置文件
./models/research/object_detection/samples/configs路径下给了很多供参考的配置文件。这里基于ssd_mobilenet_v1_coco.config进行修改,修改成适合自己模型的配置文件。(模型的结构也可以通过配置文件进行修改,之后会详解tensorflow/models源码以及其配置文件的使用)我直接在google drive中使用Text edit打开这一文件进行修改,修改后的文件见我的GitHub我直接fork了一份本经验贴总结时的代码版本,方便之后使用。
更改运行时
使用colab的初衷是colab可以提供免费的GPU算力,然而colab默认是使用CPU运行时的,需要手动更改为GPU运行时。选择菜单栏中的修改->笔记本设置,将硬件加速器改为GPU。重新选择运行时会导致google drive断连,需要重新挂载google drive。

安装必要环境
在GitHub中一般会声明模型所需环境,使用!pip命令安装即可。
!pip install tf_slim
!pip install tensorflow-gpu==1.15
编译protobuf库
!apt-get install protobuf-compiler python-lxml python-pil
%cd /content/gdrive/MyDrive/test/models/research
!protoc object_detection/protos/*.proto --python_out=.
进行训练
添加环境变量
import os
import sys
os.environ['PYTHONPATH']+=":/content/gdrive/MyDrive/test/models"
os.environ['PYTHONPATH']+=":/content/gdrive/MyDrive/test/models/research"
os.environ['PYTHONPATH']+=":/content/gdrive/MyDrive/test/models/research/slim"
运行主训练函数
%cd /content/gdrive/MyDrive/test
!python ./models/research/object_detection/legacy/train.py \
--train_dir /content/gdrive/MyDrive/test/train \
--pipeline_config_path /content/gdrive/MyDrive/test/models/research/object_detection/samples/configs/ssd_mobilenet_v1_coco.config
训练后的输出如下图所示:
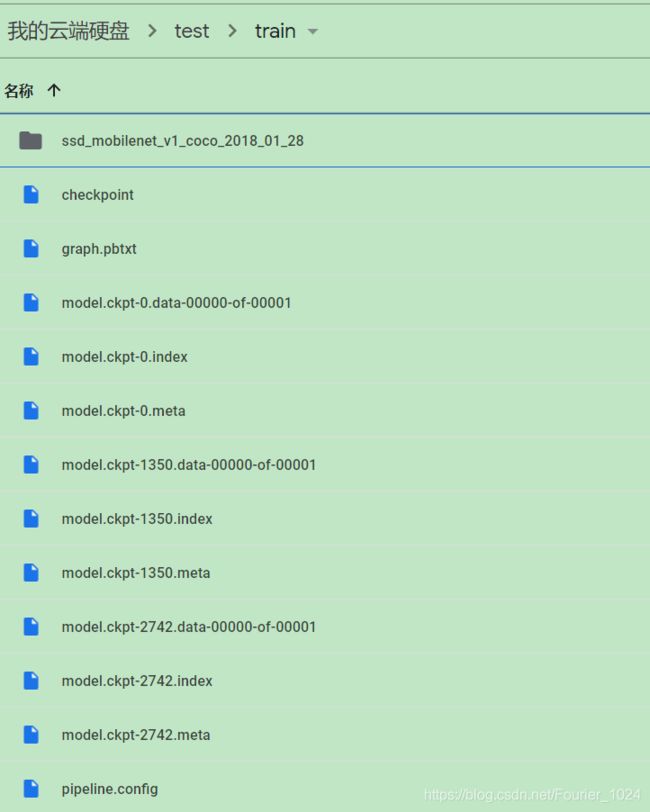
生成的文件存储了模型可训练的所有参数,如何将其固化成前向网络进行使用将在之后进行总结。
3.6 ckpt固化为pb文件
ckpt文件可以理解为模型中所有的可训练参数。pb文件可以理解为带参数的计算图,具有原来模型的所有功能。
很多大牛都已经总结过这一方法。例如pan_jinquan。tensorflow/models也有自带的文件将ckpt转pb,…/models/research/object_detection/export_inference_graph.py。
只需配置pipeline_config_path(.config文件),trained_checkpoint_prefix(model.ckpt-num,num填ckpt文件中最大的数,例如3.5节中,最大的为2742),output_directory(输出路径),运行该文件即可生成固化后的模型。
%cd /content/gdrive/MyDrive/test
!python ./models/research/object_detection/legacy/export_inference_graph.py \
--trained_checkpoint_prefix model.ckpt-2742 \
--pipeline_config_path /content/gdrive/MyDrive/test/models/research/object_detection/samples/configs/ssd_mobilenet_v1_coco.config \
--output_directory /content/gdrive/MyDrive/test/train
后续文章会介绍pb文件的使用。