感知器
为了理解神经网络,我们应该先理解神经网络的组成单元——神经元。神经元也叫做感知器。感知器算法在上个世纪50-70年代很流行,也成功解决了很多问题。并且,感知器算法也是非常简单的。
感知器的定义
下图是一个感知器:

一个感知器有如下组成部分:
输入权值 一个感知器可以接收多个输入,每个输入上都有一个权值w,此外还有一个偏置项b
-
激活函数 感知器的激活函数可以有很多选择,比如我们可以选择下面这个阶跃函数f来作为激活函数:
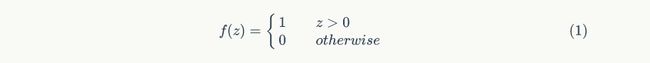
输出 感知器的输出由下面这个公式来计算
我们用一个简单的例子来帮助理解
例子:用感知器实现and函数
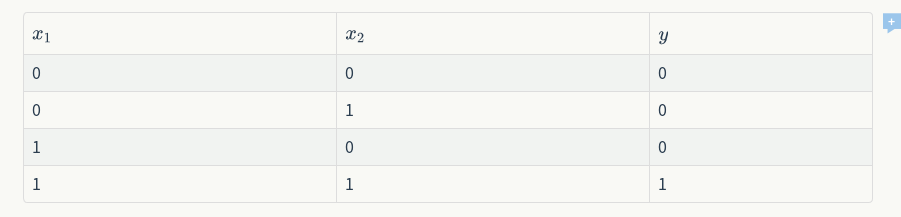
我们设计一个感知器,让它来实现and运算。程序员都知道,and是一个二元函数(带有两个参数X1和X2),下面是它的真值表:
我们令,而激活函数就是前面写出来的阶跃函数,这时,感知器就相当于and函数。不明白?我们验算一下:
输入上面真值表的第一行,即,那么根据公式(1),计算输出:
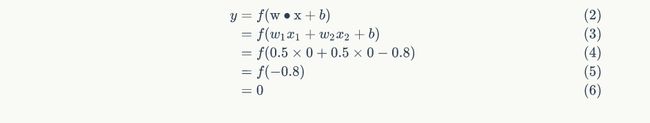
例子:用感知器实现or函数
同样,我们可以用感知器来实现or运算。仅仅需要把偏置项b的值设置为-0.3就可以了。我们验算一下,下面是or运算的真值表:


感知器还能做什么
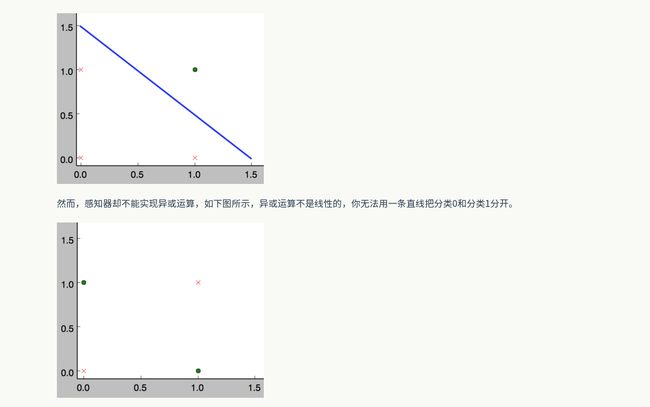
事实上,感知器不仅仅能实现简单的布尔运算。它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。前面的布尔运算可以看作是二分类问题,即给定一个输入,输出0(属于分类0)或1(属于分类1)。如下面所示,and运算是一个线性分类问题,即可以用一条直线把分类0(false,红叉表示)和分类1(true,绿点表示)分开。
感知器的训练
现在,你可能困惑前面的权重项和偏置项的值是如何获得的呢?这就要用到感知器训练算法:将权重项和偏置项初始化为0,然后,利用下面的感知器规则迭代的修改和,直到训练完成。

编程实战:实现感知器
完整代码
对于程序员来说,没有什么比亲自动手实现学得更快了,而且,很多时候一行代码抵得上千言万语。接下来我们就将实现一个感知器。
下面是一些说明:
- 使用python语言。python在机器学习领域用的很广泛,而且,写python程序真的很轻松。
- 面向对象编程。面向对象是特别好的管理复杂度的工具,应对复杂问题时,用面向对象设计方法很容易将复杂问题拆解为多个简单问题,从而解救我们的大脑。
- 没有使用numpy。numpy实现了很多基础算法,对于实现机器学习算法来说是个必备的工具。但为了降低读者理解的难度,下面的代码只用到了基本的python(省去您去学习numpy的时间)。
下面是感知器类的实现,非常简单。去掉注释只有27行,而且还包括为了美观(每行不超过60个字符)而增加的很多换行。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 19-2-14 下午4:13
# @Author : Gavin
# @Site :
# @File : perceptron.py
# @Software: PyCharm
from functools import reduce
import tqdm
class Perception(object):
def __init__(self,input_num,activator):
"""
:param input_num:输入参数的个数
:param activator:激活函数
"""
self.activator = activator
##权重向量初始化为0
self.weight = [0.0 for _ in range(input_num)]
##偏置项初始化为0
self.bias = 0.0
def __str__(self):
"""
打印学习到的权重、偏置项
:return:
"""
return 'weights :{} bias :{}'.format(self.weight,self.bias)
def prdict(self,input_vec):
"""
把input_vec[x1,x2,x3...]和weights[w1,w2,w3,....]打包在一起
变为[(x1,w1),(x2,w2),....],然后利用map函数计算[x1*w1,x2*w2,.....],
最后利用reduce求和
:param input_vec:
:return:
"""
xw = zip(input_vec,self.weight)
xw_map = map(lambda x:x[0]*x[1],xw)
xw_map_sum = reduce(lambda x,y:x+y,xw_map,0.0)
return self.activator(xw_map_sum +self.bias)
def train(self,input_vecs,labels,iteration,rate):
"""
输入训练数据:一组向量、与每个向量对应的label;以及训练轮数、学习率
:param input_vecs: 一组向量
:param labels: 每个向量对应的label
:param iteration: 训练轮数
:param rate: 学习率
:return:
"""
for i in (range(iteration)):
self._one_interation(input_vecs,labels,rate)
def _one_interation(self,input_vecs,labels,rate):
"""
一次迭代,把所有的训练数据过一遍
:param input_vecs:
:param labels:
:param rate:
:return:
"""
# 把输入和输出打包在一起,成为样本的列表[(input_vec,label),...]
# 而每个训练样本是(input_vec,label)
samples = zip(input_vecs, labels)
for (input_vec,label) in samples:
#计算感知器在当前权重下的输出
output = self.prdict(input_vec)
#更新权重
self._update_weights(input_vec,output,label,rate)
def _update_weights(self,input_vec,output,label,rate):
"""
按照感知器规则更新权重
:param input_vec:
:param output:
:param label:
:param rate:
:return:
"""
#把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,....]打包在一起,变为[(x1,w1),(x2,w2),(x3,w3),....]
xw = zip(input_vec, self.weight)
#利用感知器规则更新权重
delta = label - output
self.weight=list(map(lambda x:x[1] + rate * delta * x[0],xw))
#更新bias
self.bias += rate * delta
def fun(x):
if x >0:
a = 1
else:
a = 0
return a
# per = Perception(input_num=3,activator=fun)
# print(per.prdict(input_vec=[0,0]))
#
# print(per)
###################and函数实现
def get_training_dataset():
input_vecs = [[1,1], [0,0], [1,0], [0,1]]
# 期望的输出列表,注意要与输入一一对应
# [1,1] -> 1, [0,0] -> 0, [1,0] -> 0, [0,1] -> 0
labels = [1,0,0,0]
return input_vecs,labels
def train_and_perception():
p = Perception(2,fun)
input_vecs,labels = get_training_dataset()
p.train(input_vecs,labels,10,0.1)
return p
##################or函数实现
def get_training_or_dataset():
input_vecs = [[1, 1], [0, 0], [1, 0], [0, 1]]
# 期望的输出列表,注意要与输入一一对应
# [1,1] -> 1, [0,0] -> 0, [1,0] -> 1, [0,1] -> 1
labels = [1, 0, 1, 1]
return input_vecs,labels
def train_or_perception():
p = Perception(2,fun)
input_vecs,labels = get_training_or_dataset()
p.train(input_vecs,labels,10,0.1)
return p
if __name__ == '__main__':
###################训练、测试and函数
and_perception = train_and_perception()
##打印训练获得的权重
print(and_perception)
##测试
print('1 and 1 ={}'.format(and_perception.prdict([1,1])))
print('1 and 0 ={}'.format(and_perception.prdict([1,0])))
print('0 and 1 ={}'.format(and_perception.prdict([0,1])))
####################训练、测试or函数
or_perception = train_or_perception()
##打印训练获得的权重
print(or_perception)
##测试
print('1 and 1 ={}'.format(or_perception.prdict([1, 1])))
print('1 and 0 ={}'.format(or_perception.prdict([1, 0])))
print('0 and 0 ={}'.format(or_perception.prdict([0, 0])))