python性能测试器:profile、hotshot、cProfile
profile较早,模块是Python写成的,同来测试函数的执行时间及每次脚本执行的总时间。
hotshot模块在python2.2中新增,用C写成,有效提高了性能。
cProfile模块是python2.5新增,它替换掉hotshot和profile模块。作者明确了明显的缺点是:需要花较长时间从日志文件中载入分析结果,不支持子函数状态细节及某些结果不准。
使用cProfile和 pstats对python脚本性能分析
cProfile思路
1.使用cProfile模块生成脚本执行的统计信息文件
2.使用pstats格式化统计信息,并根据需要做排序分析处理
1.使用cProfile模块生成脚本执行的统计信息文件
python -m cProfile -o /jtitsm/01_shipper/cProfile_read_xml.txt read_xml.py /jtitsm/TEST/wbmh_1/20171017 /soft/omc_bak/xml/test_1/20171017 /jtitsm/01_shipper_test/logs/file2tcp_xml.log.20171017
参数说明:
使用模块当做脚本运行:-m cProfile
输出参数:-o /jtitsm/01_shipper/cProfile_read_xml.txt
测试的python脚本:read_xml.py
2.python命令行查看统计信息。
执行python:
1 import pstats 2 p=pstats.Stats('/jtitsm/01_shipper/cProfile_read_xml.txt') 3 p.print_stats() 4 #根据调用次数排序 5 p.sort_stats('calls').print_stats() 6 #根据调用总时间排序 7 p.sort_stats('cumulative').print_stats()
*Stats类(pstats.Stats)说明
strip_dirs() 用以除去文件名前的路径信息。
add(filename,[…]) 把profile的输出文件加入Stats实例中统计
dump_stats(filename) 把Stats的统计结果保存到文件
sort_stats(key,[…]) 最重要的一个函数,用以排序profile的输出
reverse_order() 把Stats实例里的数据反序重排
print_stats([restriction,…]) 把Stats报表输出到stdout
print_callers([restriction,…]) 输出调用了指定的函数的函数的相关信息
print_callees([restriction,…]) 输出指定的函数调用过的函数的相关信息
sort_stats支持以下参数:
参数 含义
‘calls’ call count
‘cumulative’ cumulative time
‘file’ file name
‘filename’ file name
‘module’ module name
‘ncalls’ call count
‘pcalls’ primitive call count
‘line’ line number
‘name’ function name
‘nfl’ name/file/line
‘stdname’ standard name
‘time’ internal time
‘tottime’ internal time
----------------------------------------------------------------------------------------------------
Python性能测试方法
对代码优化的前提是需要了解性能瓶颈在什么地方,程序运行的主要时间是消耗在哪里,对于比较复杂的代码可以借助一些工具来定位。本文主要讨论如何在项目中测试Python瓶颈函数,对于模块化程度比较好的项目运用如下方法测试会得到比较好的效果。
测试的方法大致如下:利用profile对每个 python 模块进行测试(具体显示可以采用文本报表或者图形化显示),找到热点性能瓶颈函数之后,再利用 line_profiler 进行逐行测试,寻找具有高 Hits 值或高 Time 值的行,最后把需要优化的行语句通过例如Cython之类的优化工具进行优化
(1)利用profile分析相关的独立模块
利用profile分析相关的独立模块,python内置了丰富的性能分析工具,profile,cProfile与hotshot等。其中Profiler是python自带的一组程序,能够描述程序运行时候的性能,并提供各种统计帮助用户定位程序的性能瓶颈。Python标准模块提供三profilers:cProfile,profile以及hotshot。profile是python的标准库。可以统计程序里每一个函数的运行时间,并且提供了多样化的报表。使用profile来分析一个程序很简单,profile可以直接用python解释器调用profile模块来剖分py程序,如在命令行界面输入如下命令:
python -m cProfile profileTest3.py

其中输出每列的具体解释如下:
●ncalls:表示函数调用的次数;
●tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
●percall:(第一个percall)等于tottime/ncalls;
●cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间;
●percall:(第二个percall)即函数运行一次的平均时间,等于cumtime/ncalls;
●filename:lineno(function):每个函数调用的具体信息
三者对比:profile速度很慢,只能用于一些小的脚本测试,测试大一点的benchmark往往需要十几分钟甚至更多时间。hotshot和cProfile是用C实现的,所以速度比较快。hotshot有一个缺点是它不支持多线程编程,而且在python2.5以后已经不再维护,较新的版本已经不支持。cProfile相比其它两者有速度快而且能够适用所以版本
(2)通过pstats进行文本报表分析 或者 使用gprof2dot进行报表图形树分析
直接使用profile展示出出来的结果很不明朗,需要自己去慢慢找那些模块占用的时间比较多,我们可以先把这个文件编译成为中间结果,使用命令:
python -m cProfile -o funb.prof profileTest3.py
然后可以通过pstats模块进行文本报表分析,它支持多种形式的报表输出,是文本界面下一个较为实用的工具。pstats模块里的有两个有用的函数sort_stats()和t_stats()接受一个或者多个字符串参数,如”time”、”name”等,表明要根据哪一列来排序,这相当有用,例如我们可以通过用time为key来排序得知最消耗时间的函数,也可以通过cumtime来排序,获知总消耗时间最多的函数。另一个相当重要的函数就是print_stats——用以根据最后一次调用sort_stats之后得到的报表。print_stats有多个可选参数,用以筛选输出的数据。
-----------------------------------------------------------------------------
Python的7种性能测试工具:timeit、profile、cProfile、line_profiler、
memory_profiler、PyCharm图形化性能测试工具、objgraph
1.timeit
1 import timeit 2 def fun(): 3 for i in range(100000): 4 a = i * i
>>>timeit.timeit('fun()', 'from __main__ import fun', number=1)
0.02922706632834235
timeit只输出被测试代码的总运行时间,单位为秒,没有详细的统计。
2.profile
profile:纯Python实现的性能测试模块,接口和cProfile一样。
1 import profile 2 def fun(): 3 for i in range(100000): 4 a = i * i
>>>profile.run('fun()')
5 function calls in 0.031 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.016 0.016 :0(exec)
1 0.016 0.016 0.016 0.016 :0(setprofile)
1 0.016 0.016 0.016 0.016 :1(fun)
1 0.000 0.000 0.016 0.016 :1()
1 0.000 0.000 0.031 0.031 profile:0(fun())
0 0.000 0.000 profile:0(profiler)
ncall:函数运行次数
tottime: 函数的总的运行时间,减去函数中调用子函数的运行时间
第一个percall:percall = tottime / nclall
cumtime:函数及其所有子函数调整的运行时间,也就是函数开始调用到结束的时间。
第二个percall:percall = cumtime / nclall
3.cProfile
profile:c语言实现的性能测试模块,接口和profile一样。
1 import cProfile 2 def fun(): 3 for i in range(100000): 4 a = i * i
>>>cProfile.run('fun()')
4 function calls in 0.024 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.024 0.024 0.024 0.024 :1(fun)
1 0.000 0.000 0.024 0.024 :1()
1 0.000 0.000 0.024 0.024 {built-in method exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
ncalls、tottime、percall、cumtime含义同profile。
4.line_profiler
安装:
pip install line_profiler
安装之后kernprof.py会加到环境变量中。
line_profiler可以统计每行代码的执行次数和执行时间等,时间单位为微妙。
测试代码:
C:\Python34\test.py
1 import time 2 3 @profile 4 def fun(): 5 a = 0 6 b = 0 7 for i in range(100000): 8 a = a + i * i 9 10 for i in range(3): 11 b += 1 12 time.sleep(0.1) 13 14 return a + b 15 16 fun()
使用:
1.在需要测试的函数加上@profile装饰,这里我们把测试代码写在C:\Python34\test.py文件上.
2.运行命令行:kernprof -l -v C:\Python34\test.py
输出结果如下:
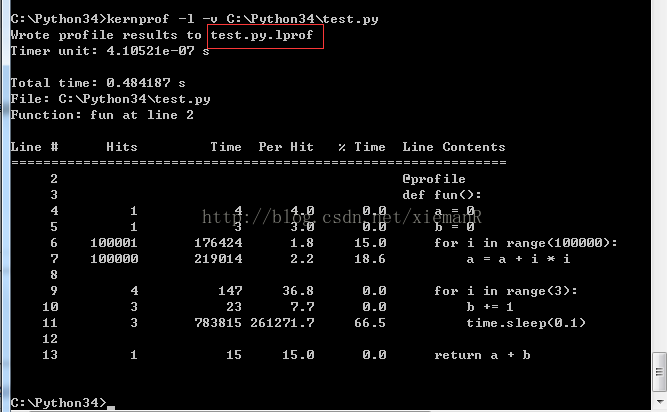
Total Time:测试代码的总运行时间
Hits:表示每行代码运行的次数
Time:每行代码运行的总时间
Per Hits:每行代码运行一次的时间
% Time:每行代码运行时间的百分比
5.memory_profiler
memory_profiler工具可以统计每行代码占用的内存大小。
安装:
pip install memory_profiler
pip install psutil
测试代码:
同line_profiler。
使用:
1.在需要测试的函数加上@profile装饰
2.执行命令: python -m memory_profiler C:\Python34\test.py
输出如下:
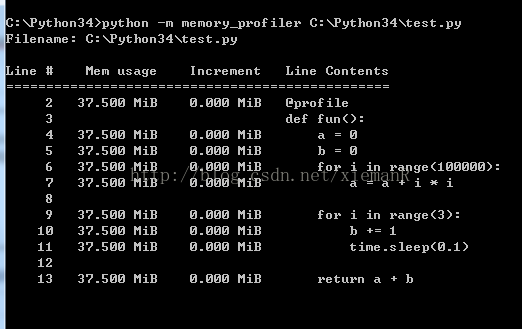
6.PyCharm图形化性能测试工具
PyCharm提供了图像化的性能分析工具,使用方法见利用PyCharm的Profile工具进行Python性能分析。
7.objgraph
objgraph需要安装:
pip install objgraph
使用方法这里不做描述,自行百度。