一、乱码
首先,所有信息在计算机上都是以二进制形式存储。而当出现乱码的时候往往是将这些信息以字符的形式表现之后。这是因为用的编码和解码的方式不一样。
举个例子:
当我们将“祝福”输入电脑时。默认是以GB2312作为字符编码进行编码,将汉字编码成二进制存储在电脑中,当我们再次读取时,若采用UTF-8字符编码来解码输出,就会造成乱码。
就像:
当英国人将“祝福”写在纸上时。默认是以英文来编码,将“祝福”的意思编码成bless。当一个法国人读取时,会通过法语来解码这个单词的意思,在法语中,bless就是“受伤”的意思。就会造成理解错误,而当如果法语如果没有这个单词,就会翻译出错,出现乱码。
二、字符集
字符集是一个规则的集合。就比如上述的英语,汉语,法语。
对于一个字符集来说,正确编码转码一个字符需要三个关键元素:字库表(character repertoire)、编码字符集(coded character set)、字符编码(character encoding form)。
其中字库表相当于一个所有字符的数据库。编码字符集(编码用的字符集)用来表示一个字符在字库中的位置。字符编码(字符的编码)表示将编码字符集转化为实际存储的数值。
一般来说,会直接将编码字符集的值作为编码后的值直接存储。例如ASCLL中A的位置是65位,编码后的A的数值是0100 0001,即十进制的65转化为二进制。
看到这里,可能有人会疑惑:既然每个字符都有自己的编号(编码字符集),那直接存储就好了啊,为什么还要字符编码呢?
其实原因也比较好理解,unicode的出现是为了统一字库表,能够涵盖世界上所有的字符,但实际使用过程中会发现真正用的上的字符相对整个字库表来说比例非常低。例如中文地区的程序几乎不会需要日语字符,而一些英语国家甚至简单的ASCII字库表就能满足基本需求。而如果把每个字符都用字库表中的序号来存储的话,每个字符就需要3个字节(这里以Unicode字库为例),这样对于原本用仅占一个字符的ASCII编码的英语地区国家显然是一个额外成本(存储体积是原来的三倍)。算的直接一些,同样一块硬盘,用ASCII可以存1500篇文章,而用3字节Unicode序号存储只能存500篇。于是就出现了UTF-8这样的变长编码。在UTF-8编码中原本只需要一个字节的ASCII字符,仍然只占一个字节。而像中文及日语这样的复杂字符就需要2个到3个字节来存储。
UTF-8和Unicode的关系
看完上面的解释,那么对于UTF-8和Unicode的关系就比较好理解了。unicode就是上面的编码字符集,而utf-8就是字符编码。也可以理解为unicode是字符在字库里的位置,或者unicode代表整个字库。
unicode几乎包括了所有国家的可能出现的所有字符。Unicode的编号从0000开始一直到10FFFF共分为16个Plane,每个Plane中有65536个字符。而UTF-8则只实现了第一个Plane,可见UTF-8虽然是一个当今接受度最广的字符集编码,但是它并没有涵盖整个Unicode的字库,这也造成了它在某些场景下对于特殊字符的处理困难。
UTF-8编码简介
为了更好的理解后面的实际应用,我们这里简单的介绍下UTF-8的编码实现方法。即UTF-8的物理存储和Unicode序号的转换关系。
UTF-8编码为变长编码。最小编码单位(code unit)为一个字节。一个字节的前1-3个bit为描述性部分,后面为实际序号部分。
1、如果一个字节的第一位为0,那么代表当前字符为单字节字符,占用一个字节的空间。0之后的所有部分(7个bit)代表在Unicode中的序号。
2、如果一个字节以110开头,那么代表当前字符为双字节字符,占用2个字节的空间。110之后的所有部分(7个bit)代表在Unicode中的序号。且第二个字节以10开头
3、如果一个字节以1110开头,那么代表当前字符为三字节字符,占用2个字节的空间。110之后的所有部分(7个bit)代表在Unicode中的序号。且第二、第三个字节以10开头
4、如果一个字节以10开头,那么代表当前字节为多字节字符的第二个字节。10之后的所有部分(6个bit)代表在Unicode中的序号。
具体每个字节的特征可见下表,其中x代表序号部分,把各个字节中的所有x部分拼接在一起就组成了在Unicode字库中的序号:
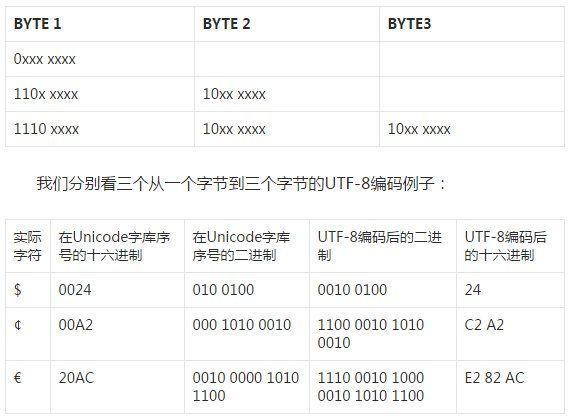
例如“汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以肯定要用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 110001 001001,用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
其中iso 8859-1,gb2312,gbk,gb18030,big5,unicode等都是编码字符集和字符编码一致的字符集,其中,unicode还有好几种字符编码,比如UTF-8,UTF-16等等。
三、乱码解决
根据上诉内容,可以知道大部分的乱码都是由解码编码不统一引起的(iso8859-1解码中文也会乱码),那我们怎么解决呢?
其实只要分析每个需要解码的过程,一一分析就可以知道了。以web应用为例:
首先在jsp上面有一行不可或缺的代码<%@ page contentType="text/html; charset=utf-8" pageEncoding="utf-8"%>
pageEncoding是jsp文件本身的编码
contentType的charset是指服务器发送给客户端时的内容编码
JSP要经过两次的“编码”,第一阶段会用pageEncoding,第二阶段会用utf-8至utf-8,第三阶段就是由Tomcat出来的网页, 用的是contentType。
第一阶段是jsp编译成.java,它会根据pageEncoding的设定读取jsp,结果是由指定的编码方案翻译成统一的UTF-8 JAVA源码(即.java),如果pageEncoding设定错了,或没有设定,出来的就是中文乱码。
第二阶段是由JAVAC的JAVA源码至java byteCode的编译,不论JSP编写时候用的是什么编码方案,经过这个阶段的结果全部是UTF-8的encoding的java源码。
JAVAC用UTF-8的encoding读取java源码,编译成UTF-8 encoding的二进制码(即.class),这是JVM对常数字串在二进制码(java encoding)内表达的规范。
第三阶段是Tomcat(或其的application container)载入和执行阶段二的来的JAVA二进制码,输出的结果,也就是在客户端见到的,这时隐藏在阶段一和阶段二的参数contentType就发挥了功效
参考文献:
Notepad++的多种编码支持
编译.java文件时的编码问题
【笔面试】字符流和字节流的区别以及如何解决乱码问题
jsp中的contentType与pageEncoding的区别和作用
汉字编码转换原理及方法
四、Notepad++
而像Notepad++等软件,有两种功能
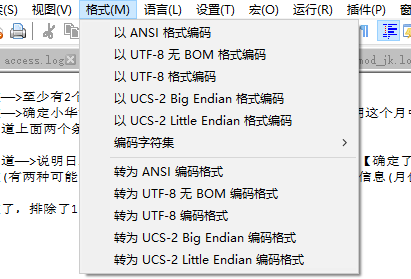
以XXX格式编码是改变编码字符集,意味着在电脑中存储的值是不变的
转为XXX格式编码是改变编码格式,意味着都是同一个字符集,改变的是编码方式,比如UTF-8转UTF-16
utf8mb4可以放表情,4个字节
utf8_bin将字符串中的每一个字符用二进制数据存储,区分大小写。
utf8_genera_ci不区分大小写,ci为case insensitive的缩写,即大小写不敏感。
utf8_general_cs区分大小写,cs为case sensitive的缩写,即大小写敏感。