pytorch实现:卷积神经网络识别FashionMNIST
pytorch实现:卷积神经网络识别FashionMNIST
- 一、卷积神经网络
-
- 1.1 导入需要的包
- 1.2 图像数据准备
- 1.3 卷积神经网络搭建
- 1.4 卷积神经网络训练与预测
- 二、空洞卷积神经网络
-
- 2.1 空洞卷积神经网络搭建
- 2.2 空洞卷积网络预测
一、卷积神经网络
1.1 导入需要的包
对于moduleNotFoundError: No module named ‘pandas’等情况发生时,需要在Anaconda Prompt下进入pytorch(activate pytorch)环境,然后conda install pandas即可。(采用pip安装会报错,但也可以尝试)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import copy
import time
import torch
import torch.nn as nn
import torch.utils.data as Data
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from torch.optim import Adam
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import warnings
warnings.filterwarnings("ignore") #忽略warning
1.2 图像数据准备
train_data=FashionMNIST(root=’./data/FashionMNIST’, train=True, transform=transforms.ToTensor(), download=True) #第一次运行时,需要将download设置为True
train_data=FashionMNIST(root='./data/FashionMNIST',
train=True,
transform=transforms.ToTensor(),
download=False)
test_data=FashionMNIST(root='./data/FashionMNIST', #数据路径
train=False,
transform=transforms.ToTensor(), #装换成tensor变量
download=False) #已经下载过了,不需要下载
#为数据添加一个通道维度,将数据缩放到0-1
test_data_x=test_data.data.type(torch.FloatTensor)/255.0
test_data_x=torch.unsqueeze(test_data_x, dim=1)
test_data_y=test_data.targets
print('test_data_x.shape:', test_data_x.shape)
print('test_data_y.shape:', test_data_y.shape)
#结果
test_data_x.shape: torch.Size([10000, 1, 28, 28])
test_data_y.shape: torch.Size([10000])
#定义一个数据加载器
train_loader=Data.DataLoader(dataset=train_data,
batch_size=64,
shuffle=False,
num_workers=2)
test_loader=Data.DataLoader(dataset=test_data,
batch_size=64,
shuffle=False,
num_workers=2)
print('train_loader的batch数量为:', len(train_loader)) #显示batch的数量
print('test_loader的batch数量为:', len(test_loader)) #显示batch的数量
#结果
train_loader的batch数量为: 938
test_loader的batch数量为: 157
#获得一个batch的数据,进行可视化
for step, (b_x, b_y) in enumerate(train_loader):
if step>0:
break
#可视化batch数据
batch_x=b_x.squeeze().numpy()
batch_y=b_y.numpy()
class_label=train_data.classes
class_label[0]='T-shirt'
plt.figure(figsize=(12, 5))
for i in range(len(batch_y)):
plt.subplot(4, 16, i+1)
plt.imshow(batch_x[i,:,:], cmap=plt.cm.gray) #灰度图
plt.title(class_label[batch_y[i]], size=9)
plt.axis('off')#关闭坐标轴
plt.subplots_adjust(wspace=.05) #调节子图之间的横轴之间的间距

1.3 卷积神经网络搭建
网络结构为:
impute images–>16个33卷积核,relu激活函数,平均池化AvgPool2d–>32个33卷积核,relu激活函数,平均池化AvgPool2d–>全连接层,256个神经元–>全连接层,128个神经元–>输出层,10个神经元。
class MyConvNet(nn.Module):
def __init__(self):
super(MyConvNet, self).__init__()
#super().__init__(),就是继承父类的init方法,同样可以使用super().其他方法名,去继承父类其他方法。
#super(MyConvNet,self).__init__():首先找到MyConvNet的父类,然后将MyConvNet类的对象转化为父类的对象
#然后让这个"被转化"的对象调用自己的__init__()函数。
## 定义第一层卷积层
self.conv1=nn.Sequential(
nn.Conv2d(
in_channels=1, #输入的一张图片
out_channels=16, #输出通道为16
kernel_size=3, #卷积核尺寸
stride=1, #卷积步长
padding=1 #进行填充
), ## 卷积后: (1*28*28)→(16*28*28)
nn.ReLU(), ## 激活函数
nn.AvgPool2d(
kernel_size=2, #平均池化,池化窗口为2*2,步长为2
stride=2 #池化步长为2
), ##池化后:(16*28*28)→(16*14*14)
)
## 定义第二层卷积层
self.conv2=nn.Sequential(
nn.Conv2d(16, 32, 3, 1, 0), ## 卷积后:(16*14*14)→(32*12*12)
nn.ReLU(), ##激活函数
nn.AvgPool2d(2, 2) ##池化后:(32*12*12)→(32*6*6)
)
## 定义全连接层
self.classifier=nn.Sequential(
nn.Linear(32*6*6, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
## 定义前向传播网络
def forward(self, x):
x=self.conv1(x)
x=self.conv2(x)
x=x.view(x.size(0), -1) ##展平层
output=self.classifier(x)
return output
## 输出网络结构
myconvnet=MyConvNet()
print(myconvnet)

1.4 卷积神经网络训练与预测
#定义网络训练过程函数
def train_model(model, train_data_loader, train_rate, criterion, optimizer, num_opochs=25):
'''
#model:网络模型
#train_data_loader:训练数据集,分为训练集和验证集
#train_rate:训练集batchsize百分比
#criterion:损失函数
#optimizer:优化防范
#num_opochs:训练轮次
'''
##计算训练使用的batch数量
batch_num=len(train_data_loader)
train_batch_num=round(batch_num*train_rate)
##复制模型参数
best_model_paras=copy.deepcopy(model.state_dict())
best_acc=0.0
train_loss_all=[]
train_acc_all=[]
val_loss_all=[]
val_acc_all=[]
since=time.time()
for epoch in range(num_opochs):
print('Epoch {}/{}'.format(epoch, num_opochs))
print('-'*10)
##每个epoch有2个训练阶段
train_loss=0.0
train_corrects=0
train_num=0
val_loss=0.0
val_corrects=0
val_num=0
for step, (b_x, b_y) in enumerate(train_data_loader):
if step<train_batch_num:
model.train() ##设置模型为训练模式
output=model(b_x) #进行预测
pre_lab=torch.argmax(output, 1) #放回output每行的最大索引,即求出预测的类别
loss=criterion(output, b_y) #计算loss
optimizer.zero_grad() #梯度初始化为零
loss.backward() #反向传播求梯度
optimizer.step() #更新所有参数
train_loss+=loss.item()*b_x.size(0) #.item()方法得到张量中元素值
train_corrects+=torch.sum(pre_lab==b_y.data) #计算预测正确的个数
train_num+=b_x.size(0) #训练样本个数
else:
model.eval() #设置模型为评估模式,即进入预测模式
output=model(b_x)
pre_lab=torch.argmax(output, 1)
loss=criterion(output, b_y)
val_loss+=loss.item()*b_x.size(0)
val_corrects+=torch.sum(pre_lab==b_y.data)
val_num+=b_x.size(0)
## 计算一个epoch在训练集和验证集上的损失和精度
train_loss_all.append(train_loss/train_num)
train_acc_all.append(train_corrects.double().item()/train_num)
val_loss_all.append(val_loss/val_num)
val_acc_all.append(val_corrects.double().item()/val_num)
print('{} Train Loss: {:.4f} Train Acc: {:.4f}'.format(epoch, train_loss_all[-1], train_acc_all[-1]))
print('{} Val Loss: {:.4f} Val Acc: {:.4f}'.format(epoch, val_loss_all[-1], val_acc_all[-1]))
## 拷贝模型最高精度下的参数
if val_loss_all[-1]>best_acc:
best_acc=val_loss_all[-1]
best_model_paras=copy.deepcopy(model.state_dict())
time_use=time.time()-since
print('Train and val complete in {:.0f}m {:.0f}s'.format(time_use//60, time_use%60))
## 使用最好的模型参数
model.load_state_dict(best_model_paras)
train_process=pd.DataFrame(data={
'epoch':range(num_opochs),
'train_loss_all':train_loss_all,
'val_loss_all':val_loss_all,
'train_acc_all':train_acc_all,
'val_acc_all':val_acc_all})
return model, train_process
#对模型进行训练
optimizer=torch.optim.Adam(myconvnet.parameters(), lr=.0003)
criterion=nn.CrossEntropyLoss() #损失函数
myconvnet, train_process=train_model(myconvnet, train_loader, 0.8, criterion, optimizer, num_opochs=25)

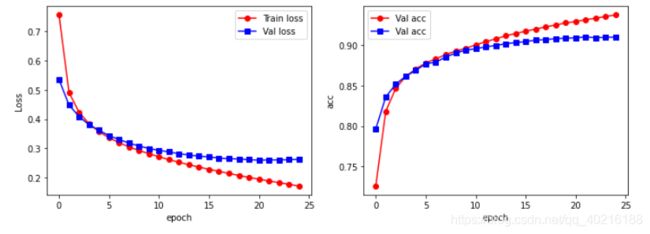
## 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1,2,1)
plt.plot(train_process.epoch, train_process.train_loss_all, 'ro-', label='Train loss')
plt.plot(train_process.epoch, train_process.val_loss_all, 'bs-', label='Val loss')
plt.legend(loc='best')
plt.xlabel('epoch')
plt.ylabel('Loss')
plt.subplot(1,2,2)
plt.plot(train_process.epoch, train_process.train_acc_all, 'ro-', label='Val acc')
plt.plot(train_process.epoch, train_process.val_acc_all, 'bs-', label='Val acc')
plt.legend(loc='best')
plt.xlabel('epoch')
plt.ylabel('acc')
plt.show()
##对测试集进行测试,并可视化预测效果
myconvnet.eval()
output=myconvnet(test_data_x)
pre_lab=torch.argmax(output, 1)
acc=accuracy_score(test_data_y, pre_lab)
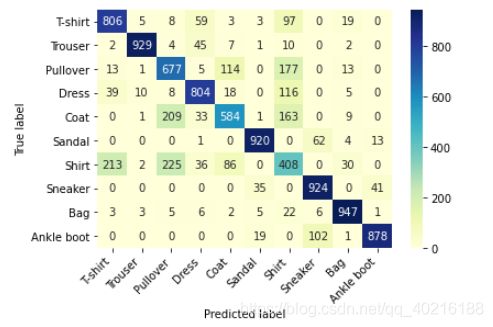
print('在测试集上的预测精度为:', acc)
#结果
在测试集上的预测精度为: 0.7877
#计算混淆矩阵并可视化
conf_mat=confusion_matrix(test_data_y, pre_lab)
df_cm=pd.DataFrame(conf_mat, index=class_label, columns=class_label)
heatmap=sns.heatmap(df_cm, annot=True, fmt='d', cmap='YlGnBu') #annot=True显示数字, fmt='d'格式设置,以整数形式显示, cmap='YlGnBu'颜色
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right')
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
二、空洞卷积神经网络
2.1 空洞卷积神经网络搭建
空洞卷积通过在卷积核中添加空洞(0元素),从而增大感受野,获取更多的信息。
感受野:某一层输出结果中的一个元素所对应的输入层区域的大小。
空洞卷积通过使用函数nn.Conv2d(),调节参数dilation的取值,来实现不同大小卷积核的空洞卷积的运算。
dilation:整数或数组,卷积核元素之间的步幅,该步幅可调整空洞卷积的空洞大小,默认为1
这里引入了一个新的超参数 d,(d - 1) 的值则为塞入的空格数,假定原来的卷积核大小为 k,那么塞入了 (d - 1) 个空格后的卷积核大小 n 为: n=k+(k-1)*(d-1)
进而,假定输入空洞卷积的大小为 i,步长 为 s ,填空大小为p,空洞卷积后特征图大小 o 的计算公式为: o=[i+2p-k-(k-1)(d-1)/s]+1 向下取整
网络结构为:
impute images–>16个33空洞卷积核,relu激活函数,平均池化AvgPool2d–>32个33空洞卷积核,relu激活函数,平均池化AvgPool2d–>全连接层,256个神经元–>全连接层,128个神经元–>输出层,10个神经元。
class MyConvdilaNet(nn.Module):
def __init__(self):
super(MyConvdilaNet, self).__init__()
##定义第一个卷积层
self.conv1=nn.Sequential(
# 卷积后,(1*28*28)→(16*26*26)
nn.Conv2d(1, 16, 3, 1, 1, dilation=2), #输入图像通道数为1,输出通道为16,卷积核为3*3,步长为1,输入两边0填充数量为1,卷积核元素之间的步幅为1
nn.ReLU(), #激活函数
nn.AvgPool2d(2,2) #池化后(16*26*26)→(16*13*13)
)
##定义第二个卷积层
self.conv2=nn.Sequential(
# 卷积后,(16*13*13)→(32*9*9)
nn.Conv2d(16, 32, 3, 1, 0, dilation=2),
nn.ReLU(), #激活函数
nn.AvgPool2d(2, 2) #平均池化,池化层窗口大小为2,步幅为2,池化后,(32*9*9)→(32*4*4)
)
##定义全连接层
self.classifier=nn.Sequential(
nn.Linear(32*4*4, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
##定义网络前向传播路径
def forward(self, x):
x=self.conv1(x)
x=self.conv2(x)
x=x.view(x.size(0), -1) ##展平层, 把卷积池化后的图像展开成:batch_size*(32*6*6)
output=self.classifier(x)
return output
## 输出网络结构
myconvdilanet=MyConvdilaNet()
print(myconvdilanet)

2.2 空洞卷积网络预测
#对模型进行训练
optimizer=torch.optim.Adam(myconvdilanet.parameters(), lr=.0003)
criterion=nn.CrossEntropyLoss() #损失函数
myconvdilanet, train_process=train_model(myconvdilanet, train_loader, 0.8, criterion, optimizer, num_epochs=25)

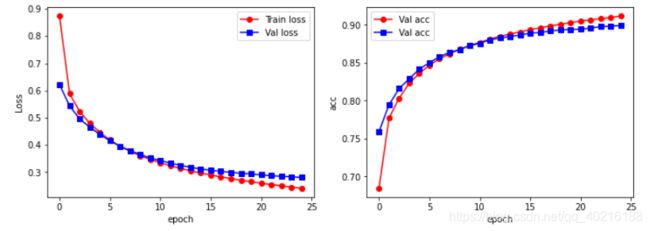
## 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1,2,1)
plt.plot(train_process.epoch, train_process.train_loss_all, 'ro-', label='Train loss')
plt.plot(train_process.epoch, train_process.val_loss_all, 'bs-', label='Val loss')
plt.legend(loc='best')
plt.xlabel('epoch')
plt.ylabel('Loss')
plt.subplot(1,2,2)
plt.plot(train_process.epoch, train_process.train_acc_all, 'ro-', label='Val acc')
plt.plot(train_process.epoch, train_process.val_acc_all, 'bs-', label='Val acc')
plt.legend(loc='best')
plt.xlabel('epoch')
plt.ylabel('acc')
plt.show()
#对测试集进行预测
myconvdilanet.eval()
output=myconvdilanet(test_data_x)
pre_lab=torch.argmax(output, 1)
acc=accuracy_score(test_data_y, pre_lab)
print('在测试集上的预测精度为:', acc)
#结果
在测试集上的预测精度为: 0.7531
#计算混淆矩阵并可视化
conf_mat=confusion_matrix(test_data_y, pre_lab)
df_cm=pd.DataFrame(conf_mat, index=class_label, columns=class_label)
heatmap=sns.heatmap(df_cm, annot=True, fmt='d', cmap='YlGnBu') #annot=True显示数字, fmt='d'格式设置,以整数形式显示, cmap='YlGnBu'颜色
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right')
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
