python中列表是不可变的数据结构_Python内置数据结构——列表(list)
一、分类
数值int float complex bool
序列对象字符串 str
列表 list
元组 tuple
键值对集合 set
字典 dict
二、数值型
数值型int flaot complex bool 都是class,即数字都是对象实例
int: python3 的int就是长整型,且没有大小限制,受限于存储区的大小
float:由整数部分和小数部分组成。支持十进制和科学记数法表示。只有双精度型
complex:由实数和虚部组成,实数和虚部都是浮点数,3+2.4J
bool:int的子类,仅有两个实例True和False,即1和0,可以和整数直接运算
类型转换int(x)返回一个整型
float(x)返回一个浮点数
complex(x)返回一个复数
bool(x)返回一个布尔值
数字的处理函数
round()——四舍六入五去偶
math 模块、floor()地板——向下取整、ceil()天花板——向上取整
int()——取整数部分、//——整除且向下取整
举例
min()——最小值
max()——最大值
pow(x,y)——x**y
math.sqrt()——算数平方根
进制函数,返回值是字符串bin()
oct()
hex()
math.pi——π
math.e——自然常数
三、数据类型判断
type(obj)——返回类型,而不是字符串
isinstance(obj,class or tuple)
举例
四、列表list
一个队列,一个排列整齐的队伍
列表内的个体称作元素,由若干元素组成列表
元素可以是任意对象(数字,字符串,对象,列表等)
列表内的元素是有顺序的,可以使用索引
线性的数据结构
列表是可变的
列表list 定义初始化
list()——创建一个新的空列表
list()——用一个可迭代对象创建新的列表
列表不能一开始就定义大小
举例:
列表索引访问
索引:也叫下标
正索引:从左至右,从0开始,为列表中的每一个元素编号
负所引:从右至左,从-1开始
索引不可以越界,即index<=len(list)-1,否则会引发IndexError
索引访问:list[index], index为索引,使用中括号访问
列表查询
index(vlaue,[start,[stop]])通过值value,从指定区间查找列表内的元素是否匹配
匹配第一个值就立即返回索引
匹配不到就立即抛出异常ValueError
count(value)返回列表中匹配value的次数
时间复杂度index和count都是O(n)
随着列表的规模增大,效率下降
len()返回列表长度,即列表元素个数
列表元素修改
索引访问修改list[index] = value
索引不可以越界
列表增加、插入元素
append(obj)列表尾部追加元素,返回None
返回None就意味着没有新的列表产生,就地修改
时间复杂度O(1)
insert(index,obj)在指定位置index插入元素object
返回None就意味着没有新的列表产生就地修改
时间复杂度,O(n)
索引可以越界超越上界,头部追加
超越下界,尾部追加
extend(iteratable)将可迭代对象的元素追加进来,返回None
就地修改
+链接操作,将两个列表连接起来
产生新的列表,原列表不变
本质上调用的是__add__()方法
*重复操作,将本列表元素重复n次,返回新的列表
列表删除元素
remove(value)从左至右查找第一个匹配value的值,移出该元素,返回None
就地修改
pop(index)不指定索引,就从列表尾部弹出一个元素
指定索引,就从索引处弹出一个元素,索引越界抛出IndexError异常
clear()清除列表所有元素,剩下空列表
列表其他操作
reverse()将列表元素翻转,返回None
就地修改
sort(key=None,reverse=False)对列表元素进行排序,就地修改,默认升序
key一个函数,指定key如何排序lst.sort(key=fun)
in[3,4] in [1,2,[3,4]]
for x in [1,2,3,4]
列表复制
我们先来看一段代码:
上述代码解析:
第一行lst0 = [0,1,2,3];
第二行lst2 = [0,1,2,3];
第三行判断两个列表是否相等,由于两个列表中的元素对应相等,所以结果为True
第四行将lst0赋值给了 lst1;
第五行对lst1的第三个元素进行了修改,修改为10,此时lst1 = [0,1,10,3,];
由于第四行的赋值实际上是将lst0的引用(也就是内存中的地址)复制给了lst1所以此时lst0和lst1实际上为真正的相等,元素相等,内存地址相等;而lst0和lst2两个列表虽然元素相等,但是仅为表面上的相等,内存地址不想等,为两个不相同变量;
综上所述:在Python中的"=="是一种表面上的判断相等,而"="在赋值的过程中是一种复杂类型的引用复制,复制了原变量的内存地址,通俗理解从根上给挖了过去。所以第三问的答案:没有元素的复制过程,只有地址的复制过程。
赋值、浅拷贝、深拷贝
赋值:b=a默认浅拷贝,只是复杂类型引用的复制传递,原始类型改变,被赋值变量也会改变。
 a,b都指向同一父对象,而父对象存放的是子对象的引用
a,b都指向同一父对象,而父对象存放的是子对象的引用
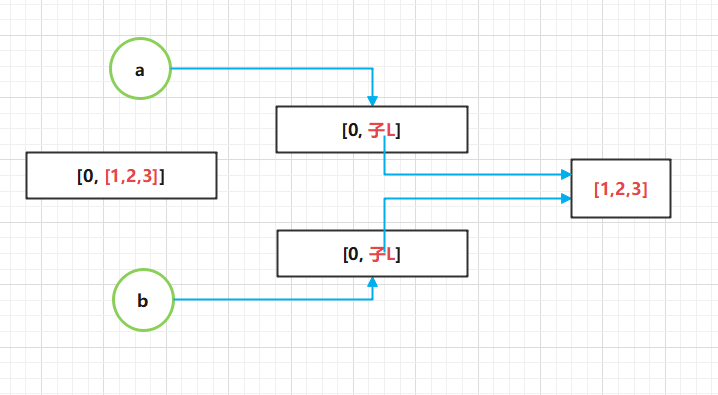
浅拷贝:b = a.copy() 拷贝与被拷贝者,都是独立对象,但子对象还是指向同一对象(同一子对象内存 地址)
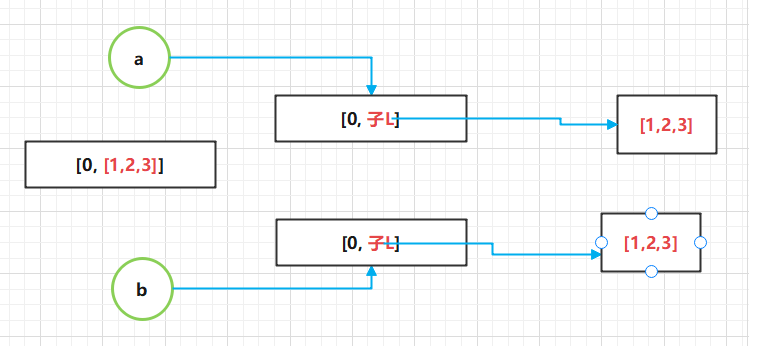
深拷贝:c = copy.deepcopy(a) c和a为完全独立的两个对象,且c内部的子对象也是独立的。
列表解析List Comprehension
例子:现在生成一个列表,元素0-9,对每一个元素自增1后求平方返回新列表
你可能会这样写:
这样写起来还是不够优雅,不够简洁!现在就需要我们的列表解析式上线了:
是不是顿时觉得 眼前一亮呢!
语法[返回值 for 元素 in 可迭代对象 if 条件]
使用[],内部是for 循环,if条件可选
返回一个新的列表列表解析式是一种语法糖编译器会优化,不会因为简写而影响效率,反而因为优化提高了效率
减少了程序的书写量,减少出错
简化了代码,可读性增强
列表解析进阶
[expr for item in iterable if cond1 if cond2]
等价于:
ret = []
for item in iterable:
if cond1:
if cond2:
ret.append(expr)求20以内,既能被2整除又能被3整除的数[i for i in range(20) if i%2 == 0 and i%3 == 0]
[i for i in range(20) if i%2 == 0 if i%3 == 0]
[expr for i in iterable1 for j in iterable2]
等价于ret = []for i initerable1:
for j in iterable2:
ret.append(expr)
举例
[(x, y) for x in 'abcde' for y in range(3)]
[[x, y] for x in 'abcde' for y in range(3)]
[{x: y} for x in 'abcde' for y in range(3)]
生成器表达式Generator expression
语法(返回值 for 元素 in 可迭代对象 if 条件)
列表解析式的中括号换成小括号就行了
返回一个生成器
和列表解析式的区别生成器表达式是按需计算(或惰性求值、延迟计算),需要的时候才计算值
列表解析式是立即返回值
生成器可迭代对象
迭代器
总结:
延迟计算
返回迭代器,可以迭代
从前到最后走完一遍后,不能回头
生成器表达式和列表解析式对比
计算方式生成表达式延迟计算,列表解析式立即计算
内存占用单从返回值本身来说,生成器表达式省内存,列表解析式返回新的列表
生成器没有数据,内存占用极少,但是使用的时候,虽然一个个返回数据,但合起来占用的数据和列表解析式差不多
列表解析式构造新的列表需要占用内存
计算速度单看计算时间,生成器表达式耗时非常短,列表解析式耗时长
但是生成器本身并没有返回值,只返回了一个生成器对象
列表解析式构造并返回了一个新的列表