爬取珍爱网各地区数据
今天咱们就爬取珍爱网,链接:http://www.zhenai.com/zhenghun
页面:
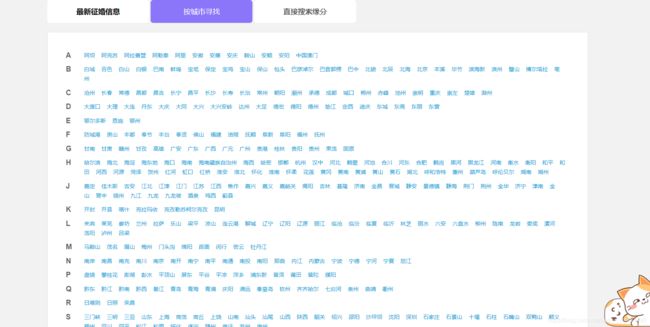
我们点击要按城市寻找,截图
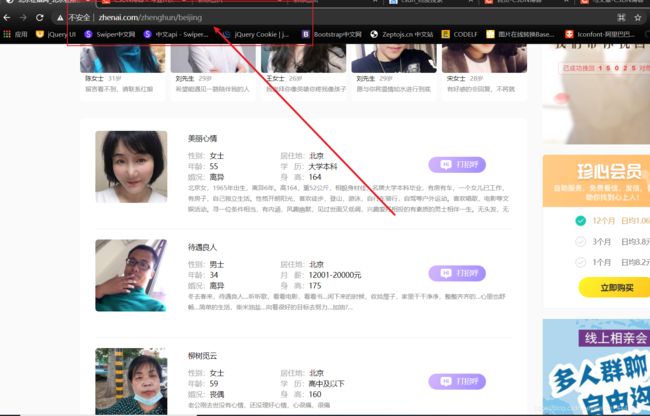
我们随便点一个,就以北京为例:
链接为:http://www.zhenai.com/zhenghun/beijing
我们访问一个城市,就是把北京替换成其他城市的英文,这里我们最后说,使用python模块将它转换,我们救助去页面的这几个字段,用户名,性别,居住地,年龄,婚况,身高,还有描述,薪资和学历乱七八糟,有的写有的没写,我们就抓拿几个字段,我们先看下响应是否在html中
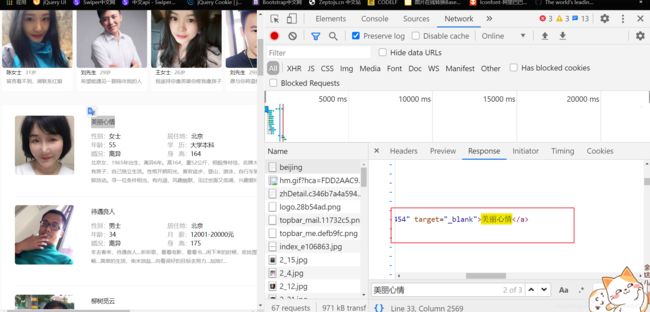
cookie自己登陆一个账号自己填充,我用自己的手机号注册的,真害怕你们干坏事…(〃‘▽’〃)
这就是静态的加载,自己登陆一个账号获取cookie,我们就用etree树配合xpath抓取我们先写代码:
from lxml import etree
import requests
class Zhenai(object):
# 初始化
def __init__(self,city):
self.url = 'http://www.zhenai.com/zhenghun/{}'.format(city)
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36',
'Cookie': '****************',
'Referer': 'https://link.csdn.net/?target=http%3A%2F%2Fwww.zhenai.com%2Fzhenghun%2F',
'Host': 'www.zhenai.com'
}
# 发送请求获取数据
def get_data(self):
response = requests.get(url=self.url, headers=self.headers)
return response
# 解析数据
def parse_data(self,response):
html = etree.HTML(response.content.decode("utf-8"))
node_list = html.xpath('//div[@class="g-list"]/div[@class="list-item"]/div[2]')
temp = {
}
for node in node_list:
temp['用户名'] = node.xpath('./table/tbody/tr[1]/th/a/text()')[0]
temp['性别'] = node.xpath('./table/tbody/tr[2]/td[1]/text()')[0]
temp['居住地'] = node.xpath('./table/tbody/tr[2]/td[2]/text()')[0]
temp['年龄'] = node.xpath('./table/tbody/tr[3]/td[1]/text()')[0]
temp['婚况'] = node.xpath('./table/tbody/tr[4]/td[1]/text()')[0]
temp['身高'] = node.xpath('./table/tbody/tr[4]/td[2]/text()')[0]
temp['描述'] = node.xpath('./div/text()')[0]
我们抓的这些只是一个页面的,我们就要拿到所有的页面的数据,而不是只拿一页我们就不拿了分析页面
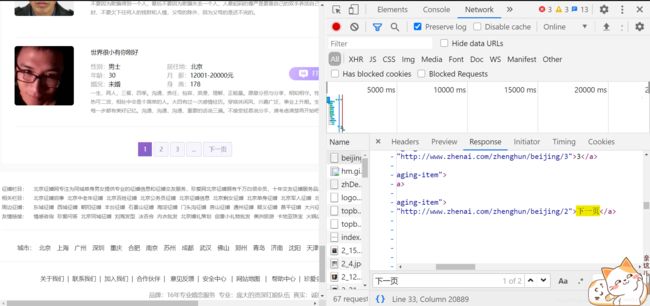
发现翻页也是静态加载的,而且下一页也是拼接好的,我们用xpath获取就好了
try:
next_url = html.xpath('//a[contains(text(), "下一页")]/@href')[0]
print(next_url)
self.url = next_url
response = self.get_data()
self.parse_data(response)
except:
return

我们发现翻页了,这个代码我就整体实现了,我们就把他封装的更完美,比如我输入德州,自动转换为英文 dezhou,,我们就抓取德州的珍爱网信息,我们就采用 xpinyin模块,用法:
from xpinyin import Pinyin
p = Pinyin()
pinyin = p.get_pinyin("德州") # 默认是以‘-’来分割的
最后会发现是de-zhou是这样的,他就是一个str,我们使用字符串的replace方法把横线删除,这样做的目的我们一会就可以看到了
if __name__ == '__main__':
name = str(input("请输入你要爬取的城市:"))
p = Pinyin()
pinyin = p.get_pinyin(name) # 默认是以‘-’来分割的
city = pinyin.replace('-','')
f = open(name+'.csv', 'a',newline='',encoding="gb18030")
csv_writer = csv.writer(f)
csv_writer.writerow(["用户名", "性别", '居住地',"年龄","婚况","身高","描述"])
zhenai = Zhenai(city)
zhenai.run()
我采用用户输入进行判断页面抓取,保存文件是excel,文件名字是城市名字效果:
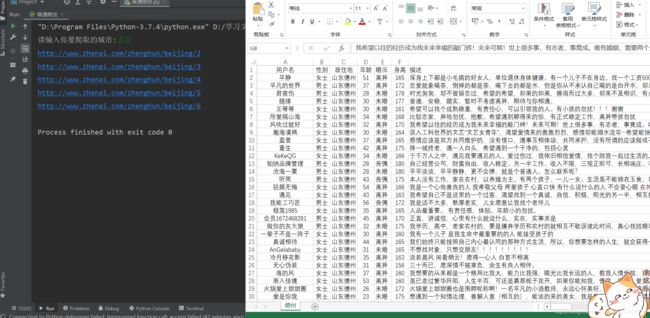
整体代码如下:
# -- coding: utf-8 --
# @Time : 2021/2/9 22:17
# @Software: PyCharm
from lxml import etree
import requests
from xpinyin import Pinyin
import csv
class Zhenai(object):
def __init__(self,city):
self.url = 'http://www.zhenai.com/zhenghun/{}'.format(city)
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36',
'Cookie': '************************',
'Referer': 'https://link.csdn.net/?target=http%3A%2F%2Fwww.zhenai.com%2Fzhenghun%2F',
'Host': 'www.zhenai.com'
}
def get_data(self):
response = requests.get(url=self.url, headers=self.headers)
return response
def parse_data(self,response):
html = etree.HTML(response.content.decode("utf-8"))
node_list = html.xpath('//div[@class="g-list"]/div[@class="list-item"]/div[2]')
temp = {
}
for node in node_list:
temp['用户名'] = node.xpath('./table/tbody/tr[1]/th/a/text()')[0]
temp['性别'] = node.xpath('./table/tbody/tr[2]/td[1]/text()')[0]
temp['居住地'] = node.xpath('./table/tbody/tr[2]/td[2]/text()')[0]
temp['年龄'] = node.xpath('./table/tbody/tr[3]/td[1]/text()')[0]
temp['婚况'] = node.xpath('./table/tbody/tr[4]/td[1]/text()')[0]
temp['身高'] = node.xpath('./table/tbody/tr[4]/td[2]/text()')[0]
temp['描述'] = node.xpath('./div/text()')[0]
csv_writer.writerow([temp['用户名'],temp['性别'],temp['居住地'],temp['年龄'],temp['婚况'],temp['身高'],temp['描述']])
try:
next_url = html.xpath('//a[contains(text(), "下一页")]/@href')[0]
print(next_url)
self.url = next_url
response = self.get_data()
self.parse_data(response)
except:
return
def run(self):
response = self.get_data()
self.parse_data(response)
if __name__ == '__main__':
name = str(input("请输入你要爬取的城市:"))
p = Pinyin()
pinyin = p.get_pinyin(name) # 默认是以‘-’来分割的
city = pinyin.replace('-','')
f = open(name+'.csv', 'a',newline='',encoding="gb18030")
csv_writer = csv.writer(f)
csv_writer.writerow(["用户名", "性别", '居住地',"年龄","婚况","身高","描述"])
zhenai = Zhenai(city)
zhenai.run()
代码就到这里结束了,有不明白的可以私信我,明天就要过年了,祝大家新年快乐!!!!!牛气冲天
