最开始学习Linux一些简单的命令。
登录(以xshell为例)
ssh username@ip #执行命令后弹出输入密码的对话框,输入密码点击确定后即可登录
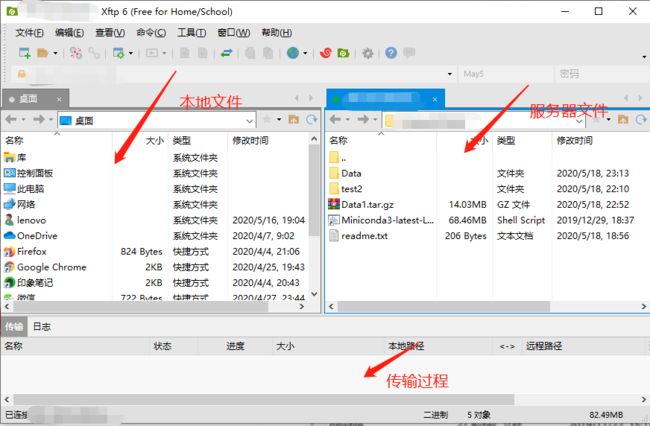
本地与服务器之间传输文件
点击xhsell菜单栏中的XFtp软件的链接图标即可打开XFtp,可通过拖拽进行上传及下载。
常用命令
- pwd:我在哪里?Print work directory,打印当前的工作目录
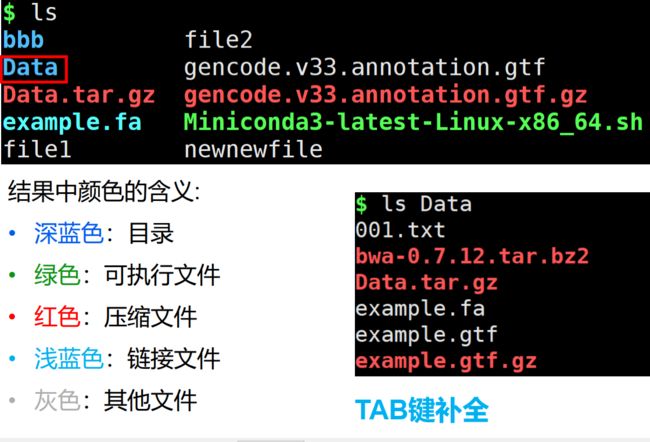
- ls:这里有什么?列出指定路径下信息。语法: ls [参数] [目录/文件名]
常用参数:


附文件颜色的含义:
- cd:更改/切换工作目录,Change the shell working directory

- mkdir:make directory,创建目录或文件夹。参数-p: 递归创建目录/文件夹。
mkdir file1 file2 #同时创建两个文件夹或目录
mkdir test{1..5} #批量创建文件夹test1到test5
mkdir -p test1/test2/test3 #递归创建test1文件夹及test1文件夹下的test2文件夹及test2文件夹下的test3文件夹
- touch:创建文件。
touch file1.txt file2 #同时创建两个文件,不是文件夹
touch file{1..5} #批量创建5个文件
- mv:move。可对文件或文件夹进行移动或重命名。
mv file1 file2 #若file2已存在,则为移动文件(将file1移动到file2文件夹下);若file2不存在,则是将file1重命名为file2
mv file1 ./test1 #将文件file1移动到当前目录下的test1文件夹下
- cp: copy and paste.复制文件或文件夹。
cp book test1 #将book文件复制到test1的文件夹下
cp -r file1 test1 #将file1文件夹递归复制到test1文件夹下

- rm: remove,删除文件或文件夹。
rm file1 #不询问直接删除文件file1
rm -i file1 #在删除文件之前询问是否要删除,比较安全
rm -r file1 #删除文件夹是需要加上-r的选项,加上-i也可再次询问是否删除

- ln: link,ln -s建立软链接,相当于创建快捷方式。
ln -s /home/file1 ./ #将根目录下home目录下的file1目录链接到当前目录下.路径使用绝对路径

- 压缩与解压缩命令:
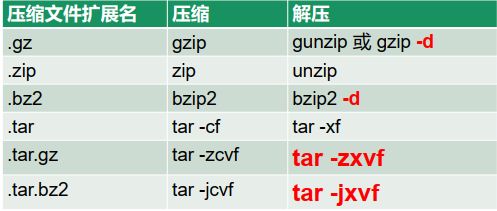 压缩与解压缩.png
压缩与解压缩.png

预习:
- cat/tac命令:
 cat参数.png
cat参数.png
 vi文本编辑器.png
vi文本编辑器.png
vi test0 #弹出编辑界面,完成后ESC键退出,输入:wq表示写入并退出
cat test0 > test90 #将test0重定向为test90(创建新的文件)
cat >newfile.txt #点击enter键后输入内容(新建或覆盖之前的内容),点击ctr+c终止输入
cat >>file1 #向file1中追加内容,不覆盖
zcat tar.gz #查看压缩包内容
- head/tail:显示前/后N行(默认10行)
 head/tail.png
head/tail.png
head/tail -3 test1 #显示test1文件的前/后3行
head/tail -n 3 test1 #显示test1文件的前/后3行
- more:逐页查看文档内容。
 more参数.png
more参数.png - less:升级版逐页查看文档内容。
 less参数.png
less参数.png
less -SN file #按单行及行标查看
zless tar.gz #查看压缩包
-
常见的文本查看命令:
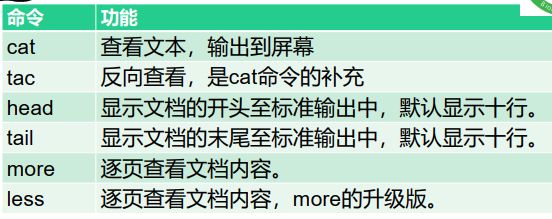 常见文本常看命令.png
常见文本常看命令.png -
wc:文本统计,行数/字符/文本大小计数
 wc参数.png
wc参数.png -
cut:文本切割命令,以列为单位处理数据。分割及提取数据均按行操作。
 cut参数.png
cut参数.png -
sort:排序。
 sort参数.png
sort参数.png -
uniq:去除重复行。uniq之前最好先排序sort。
 uniq参数.png
uniq参数.png -
paste:文本合并命令。默认按列合并文本。为一个文本中列的合并。
 paste参数.png
paste参数.png tr命令:字符替换
cat readme.txt | tr "ae" "AE" #"ae"改成“AE”
cat readme.txt | tr -d "ae" #删除"ae"
cat readme.txt | tr -s "e" #相当于去重复。删减重复字符。jobs命令:
jobs(选项)(参数)
-l:显示进程号;
-p:仅任务对应的显示进程号;
-n:显示任务状态的变化;
-r:仅输出运行状态(running)的任务;
-s:仅输出停止状态(stoped)的任务。
- sed命令:
options:
• -n :禁止显示所有输入内容,只显示经过sed处理的行(常用)
• -e :直接在命令列模式上进行 sed 的动作编辑,接要执行的一个或者多个命令
• -f :执行含有 sed 动作的文件
• -r : sed 的动作支持的扩展正则(默认基础正则)
• -i :直接修改读取的文件内容,不输出。
公式:sed [-opitons] 'script' file(s)
其中,sript公式:[address[,address]] [!] command [arguments]
###-n :禁止显示所有输入内容,只显示经过sed处理的行(常用)
#按行操作,脚本中的p代表打印行
sed '' file1#等同于cat file1
sed -n '2p' file1 #显示file1文件第二行的内容
sed -n '2,5p' file1 #显示file1文件第2到5行的内容
sed -n '2,+4p' file1 #显示file1文件第2行及后面4行的内容
sed -n '1~2p' file1 #显示file1文件的第一行及以后每2行的内容,即1,3,5行等奇数行
#按匹配模式操作,格式'/pattern/command'
sed -n '/t/p' file1 #显示file1文件含有t的行
sed -n '/^t/p' file1 #显示file1文件中以t开头的行
#d命令:删除
sed '/^t/d' file1 #显示去除了以t开头的行
#i命令(insert),在目标行之前插入新行
sed '2i Biotrainee' file1 #在第2行之前插入字符Biotrainee
#a命令(append)在目标行之后插入新行
sed '2a Biotrainee' file1 #在第2行之后插入字符Biotrainee
#c命令,替换
sed '2c Biotrianee' file1 #将第2行替换为字符Biotrainee
- s命令匹配替换
格式】 : s/pattern/replacement/[flags]
【flags】
• 数字:新文本替换第几处模式匹配的
文本
• g(global) : 新文本将替换所有
匹配到的文本
• p:原先行的内容将打印出来
• w file :将替换的结果写到文件中
sed 's/A/a/' file1 #将file1文件的第一个字母A转为小写
sed 's/A/a/3' file1 #将file1文件的第3个字母A变为小写
sed 's/A/a/g' file1 #将file1文件的所有A变为小写a
-
y命令一对一转换
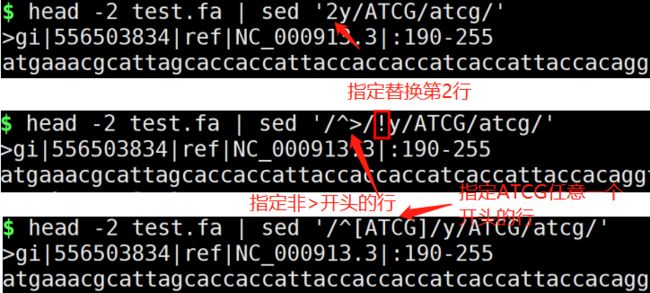 sed y命令.png
sed y命令.png

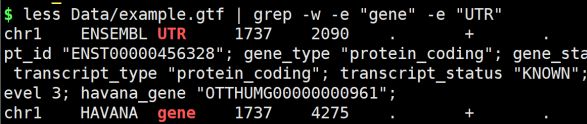
- grep命令:
grep:一种强大的文本搜索工具,能使用正则表达式匹配模式搜索文本,并把匹配的行打印出来。
语法格式: grep [options] pattern file

grep [options] pattern [file]
常用参数:
-v 反向选择,即输出没有没有匹配的行
-n 显示匹配成功的行所在的行号
-c 统计匹配成功的行的数量
-w 完全匹配
-o 只输出匹配的内容
-f 从文件中读取pattern
-e 指定多个匹配模式
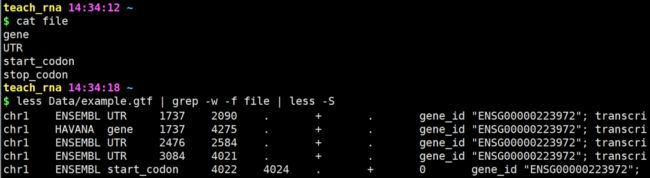
-
awk命令:
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。
awk按行处理数据。
options:
-F 设定分割符
 公式.png
公式.png- 基础结构:
awk ’{script}’ - 模式匹配结构:
awk ’/pattern/{script}’ - 扩展结构:
awk ’BEGIN{script} {script} END{script}’
- 基础结构:
-
awk在读取一行文本时,会用预定义的字段分隔符划分每个数据字段,并分配给一个变量。
➢ $0代表整个文本行;➢ $1代表文本行中的第1个数据字段;
➢ $2代表文本行中的第2个数据字段;
➢ …… awk默认的字段分隔符是任意空白字符(如:空格 or 制表符)
,也可以用 -F 参数自定义分隔符
less -S example.gtf | cut -f 9 |less -S 等同于后者
less -S example.gtf | awk '{print $9}' |less -S #显示第9列,默认分隔符为空格或制表符
less -S example.gtf |awk -F '\t' '{print $9}' |less -S #显示第9列,自定义分隔符为制表符
less -S example.gtf |awk -F '\t' '{print $9,$10}' | less -S #显示第9列
less -S example.gtf |awk '/UTR/{print $9,$10}' | less -S #显示第9第10列中含有UTR的行
less -S example.gtf |awk 'BEGIN {print "Find UTR feature"} \
/UTR/{print $0}
END {print "end"}' | \
less -S #在输出的结果中,开始的地方打印出Find UTR feature的字符,结尾打印出end的字符,中间为重,执行了把含有UTR的所有的整行都打印出来
awk文本分析语言
awk 内置变量
• FS:定义输入字段分隔符, FieldSeparator,同 -F 参数
• RS:定义输入记录分隔符, Record Separator
• OFS :定义输出字段分隔符, Out FieldSeparator
• ORS:定义输出记录分隔符, Out Record Separator
• NF:数据文件中的字段总数,可以简单理解为列数
• NR:已处理的输入记录数,可以简单理解为行数
• 也可以通过 -v 参数自定义变量或传递外部变量
less -S example.gtf |awk 'BEGIN {FS='\t'} {print $9}' | less -S #输出以制表符分割后的第9列数据
less -S example.gtf |awk 'BEGIN {FS='\t'} {print NR,$9}' | less -S
#输出以制表符分割后的第9列数据并带有行号
awk条件和循环语句:
if:条件判断
awk ' { if(判断条件){yes} else{no} } '
for:循环语句
awk ' { for(循环条件) {循环语句} }'
less -S example.gtf |awk '{if ($3=="gene") {print $0}}' | less -S #打印出第3列等于gene的所有的整行
less -S example.gtf |awk '{if ($3=="gene") {print $0}' \
else {print $3 "is not gene"}} | \
less -S #打印出第3列等于gene的所有的整行,若不符合条件,则打印出第3列内容“不是gene”。
less -S example.gtf |awk '{for (i=1;i<8;i++) {print $i}}' | less -S
less -S example.gtf |awk '{for (i=1;i<8;i++) {print $i}}' | \
paste - - - - - - - | less -S #打印出第1到7列内容
awk数学运算:
+(加), -(减), *(乘), ^(幂),/(除), **(平方), % (取余)
int(x) x的整数部分,取靠近零一侧的值
log(x) x的自然对数
less -S example.gtf |awk '/UTR/{print $5-$4}' | less -S #打印出含有UTR行中第5列-第4列的值
less -S example.gtf |awk '/UTR/{print $5/$4}' | less -S #打印出含有UTR行中第5列除以第4列的值
less -S example.gtf |awk '/UTR/{print int($5/$4+0.5}' | less -S # 通过int($5/$4+0.5}来达到四舍五入
- 输入及输出重定向:> >>
