本教程对seaborn官方教程的理解性翻译,在原教程的基础上有适当的删减,调整。仅供参考交流

. 可视化数据集的分布
- 单元分布
- 双元分布
- 可视化数据集中的pairwise relationship
1. 单元分布 sns.distplot()
-
直方图(hist)+内核密度函数(kde)
在seaborn中最简便查看单元分布的函数是distplot().该函数默认绘制直方图并拟合内核密度估计。通过调整参数可以分别绘制直方图,拟合内核密度图,地毯图等。
x = np.random.normal(size=100)
sns.distplot(x);

-
直方图
sns.distplot(x,kde=False) / plt.hist()
当绘制直方图时,你需要调整的参数是bin的数目(组数)。displot()会默认给出一个它认为比较好的组数,但是尝试不同的组数可能会揭示出数据不同的特征。
sns.displot(x,bins=20,kde=False,rug=True)

当绘制直方图时,最重要的参数是
bin以及
vertical,以确定直方图的组数和放置位置
sns.distplot(x, bins=20, kde=False, rug=True);

-
核密度估计
sns.distplot(x,hist=False) / sns.kdeplot(x)
核密度估计图使用的较少,但其是绘制出数据分布的有用工具,与直方图类似,KDE图以一个轴的高度为准,沿着另外的轴线编码观测密度。
sns.displot(x,hist=False,rug=True)

绘制KDE图比绘制直方图要复杂得多,每个观测值首先要以该值为中心的正(高斯)曲线代替。然后各个点在加起来,计算支持网格点中每个点的密度值,然后将得到的曲线归一化,使其面积小于,即得到核密度估计图
在seaborng中也有一个函数kdeplot(),使用这个函数,我们可以得到同样的曲线,这个函数在distplot()中也被调用,但是他提供了更多更方便的借口,来进行可视化调整。
sns.kdeplot(x,shae=Ture)

参数
bw(binwidth)同直方图的bin一样,控制了估算与数据间的紧密程度。与我们之前提到的内核宽度一致,默认情况下,函数会直接猜一个数据,但尝试更大或更小bw情况的,或许会更有帮助。
sns.kdeplot(x)
sns.kdeplot(x, bw=.2, label="bw: 0.2")
sns.kdeplot(x, bw=2, label="bw: 2")
plt.legend();

使用cut参数,可以控制曲线绘制多远的极限值。然而这仅仅只是影响曲线如何绘制,并不会影响曲线本身
sns.kedplot(x,shade=True,cut=0)
sns.rugplot(x)

-
拟合参数分布
sns.distplot(x,kde=False,fit=stats,gamma)
你也可以通过使用distplot()来拟合出一个数据集的参数分布,直观上来评估其余观测数据是否关系密切。
x = np.random.gamma(6, size=200)
sns.distplot(x, kde=False, fit=stats.gamma);

2. 二元变量分布 sns.jointplot()
seaborn也能用来可视化二元变量的分布,最简单的方法是使用jointplot(),这个函数能够产生一个多面板的图像,在图像上包括两个变量之间的关系,在单独的坐标中还绘制出了各个变量的分布。
mean,cov=[0,1],[(1,.5),(.5,1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"])
-
散点图
sns.jointplot(x='x',y='y',data=df)
可视化二元分布最常见的方式是绘制散点图。散点图通过散点位置来代表x,y值。这和地毯图绘制在二维上类似。你可以通过matlibplot中的plt.scatter绘制散点图,当然你也可以直接使用sns.jointplot来绘制。
sns.jointplot(x="x", y="y", data=df);

通过调节参数kind={scatter,hex,reg,resid,kde}可绘制不同种类的图。
-
Hexbin图
sns.jointplot(x=x,y=y,data=df,kind='hex')
一个直方图的二维模拟被称为“Hexbin”图,因为这类图通过六角箱颜色的深浅来表示落于六角箱类观测值的数目。因此这类图比较适用于观察较大的数据集。该图可以使用plt.hexbin绘制,当然也可以调参使用jointplot()绘制,当使用时最好设置为白色背景,图像效果最佳。
x,y=np.random.mutivariate_normal(mean,cov,1000).T
with sns.axes_style("white")
sns.jointplot(x=x,y=y,kind="hex",color='k')

-
核密度估计
sns.jointplot(x='x',y='y',data=df,kind='kde')
sns.kdeplot(df.x,df.y)
也可以通核密度函数来表现二元分布的分布,在seaborn,这样的图通过等高线图来表现二元分布的。
sns.jointplot(x="x", y="y", data=df, kind="kde");

sns也提供kedplot()函数来让你直接绘制二维核密度图。这样你就可以绘制这类图到一个特定的matplotlib轴上。
f,ax=plt.subplots(figsize(6,6))
sns.kedplot(df.x,df.y,ax=ax)
sns.rugplot9(df.x,color='g',ax=ax)
sns.rugplot(df.y,veritical=True,ax=ax)

-
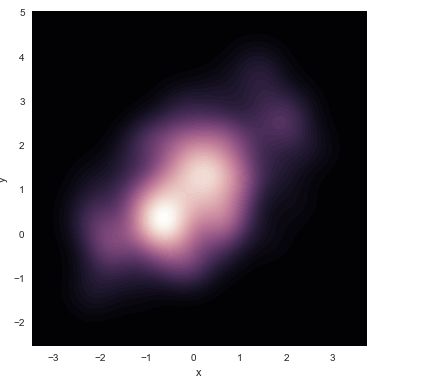
sns.kedplot(df.x,df.y,n_level=60,shade=True)
如果你希望你的二维变量密度更连续,你可以通过增加等高线数量来完成
f,ax=subplots(figsize=(6,6))
cmp=sns.cubehelix_palette(as_cmap=True,dark=0,light=1,reverse=True)
sns.kedplot(df.x,df.y,cmap=map,n_level=60,shade=True)
-
JointGrid 高级图像管理对象
jointplot()使用JointGrid来管理图形。如果你想更灵活的绘图可以通过使用JointGrid。jointplot()在绘图后将返回jointplot对象,你可以用他来添加更多的图层或调整其他可视化。
g=sns.joinplot(x='x',y='y',data=df,kind='kde',color='m')
g.plot_joint(plt.scatter,c='w',s=30,linewidth=1,marker='+')
g.ax_joint.collection[0].set_alpha(0)
g.set_axis_label("$X$","$Y$")

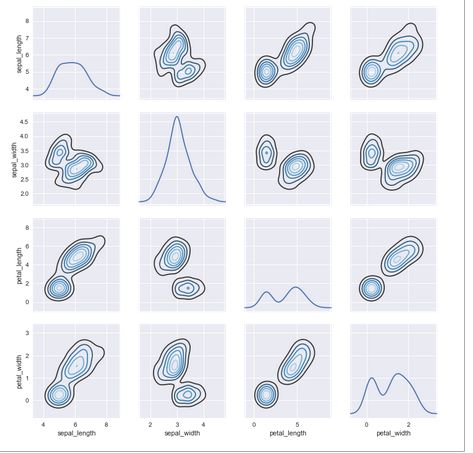
3.可视化成对关系sns.pairplot()
为了绘制一个数据集中多个成对的二元分布,你可以使用pairplot()功能,该功能将创建矩阵,来展现两两变量间的关系。默认情况,各单变量分布将绘制在对角线上。
iris=sns.load_dataset("iris")
sns.paiplot(iris)

高级图像管理对象PairGrid
和jointplot()与JointGrid的关系一样,可以使用PairGrid对pairplot进行更多个性化设计。
g=sns.Pairgrid(iris)
g.map_diag(sns.kdeplot)
g.map_offdig(snsn.kdeplot,cmap="Blues_d",n_levels=6)