泰迪杯论文B题(特等奖)
目录
一、简介
1.1研究背景及研究现状
1.2研究任务
1.2.1绝缘子串珠分割
1.2.2绝缘子自爆识别和定位
1.3技术路线流程图
1.3.1模型训练流程图
1.3.2模型测试流程图
二、基本理论
2.1卷积神经网络
2.2全卷积神经网络
2.3残差连接
三、数据预处理
3.1掩膜图像二值化
3.2图像切分
3.3数据扩增
3.4数据集调整
3.5预处理流程图
四、绝缘子串珠分割
4.1图像分割算法
4.1.1Unet 网络
4.1.2Segnet 网络
4.1.3U-Segnet 网络
4.1.4改进的U-Segnet 网络
4.2图像分割技术路线
五、连通区域检测
5.1连通域标记与面积计算
5.2面积阈值的计算
六、图像分割结果分析
6.1实验环境
6.2评价指标
6.3实验过程及结果分析
6.3.1训练超参数设置
6.3.3 结果分析
七、目标检测数据预处理
7.1数据采集
7.2人工标注
7.3绝缘子提取
7.4数据增强
八、目标检测
8.1YOLO v3 算法基本原理
8.2目标检测技术路线
九、实验及结果分析
9.1评价指标
9.2实验过程及结果分析
十、总结与展望
10.1本文工作总结
10.2未来工作展望
参考文献
附录 26
一、简介
1.1研究背景及研究现状
为了保证输电线路的安全、可靠运行,电网运行部门需要定期对输电线变电系统进行巡检、维修以及维护来确保消除故障或者隐患。随着我国经济的高速发展,对电力输电网设备等基础设施的安全运营也提出了更高的要求。架空线路巡检作为保障输配电网正常运行的重要手段之一,一直以来都面临着网线分布广、设施布置复杂,巡线作业强度大、周期长,部分区域自然环境复杂恶劣等问题。传统的电网巡查方式是通过人工进行巡检的,该方法存在以下几个问题。
① 劳动强度大,工作效率低,在危险地段会危及到巡查工人的生命安危。
② 人工录入数据量大,而且录入过程容易出错。
③ 对于工人是否巡查到位无法进行有效的管理,巡查质量不能得到保障
近年来由于无人机或者智能机器人技术的飞速发展,考虑通过拍摄的大量电力设备及线路的现场图片代替人工巡检,其基本工作流程如下。
① 划定无人机工作区域,设定巡查时间。
② 无人机飞达指定区域,进行图片拍摄(要求尽可能达到 360°全方位)。
③ 分析无人机拍摄的图片,并进行问题标注,反馈至调度中心。
④ 调度中心根据问题,安排对应人员进行检修。
但是由于无人机拍摄图片数目多(单个高架塔拍摄图像大于 300 张),尺寸大(4096*2160),人工进行一张图片标注就需要 5-10 分钟,工作量巨大。同时执行标注工作的相关人员极易用眼疲劳,从而导致漏标,错标。鉴于以上情况, 考虑使用图像处理与机器学习(深度学习)的方法,对图片进行标注。
1.2研究任务
架空输电线路巡视主要巡视内容包括:杆塔、导线及避雷线、导线及避雷线的固定与链接、绝缘子、拉线、杆上开关设备、沿线路附近的其他工程等 7 大项内容。以上 7 大项内容中的每一项都还有子项,检查内容繁多,流程繁琐。为了能够先行探索出切实有效的步骤,本次任务以绝缘子巡视中的绝缘子自爆这一故障为目标,主要实现以下两部分内容。
1.2.1绝缘子串珠分割
由于无人机图片较大一般为(4096*2160),绝缘子串珠占据图片中很小的一部分区域,需要设计图像分割算法,对绝缘子串珠坐在的区域进行分割。参赛者需要标记出所给样例每幅图像中的标记绝缘子串珠区域的掩模图像。掩模区域仅整个绝缘子串珠。
1.2.2绝缘子自爆识别和定位
根据分割图像初步识别绝缘子所在的位置,并对绝缘子串珠进行分割,而后参赛者根据所给出的标记样本的 Ground Truth 构建自爆绝缘子识别模型。参赛者利用训练模型对图像中的自爆绝缘子位置进行检测,并利用 BoundingBox 对其进行标记。自爆标记需包括自爆位置周围 2 个完好绝缘子。
1.3技术路线流程图
1.3.1模型训练流程图
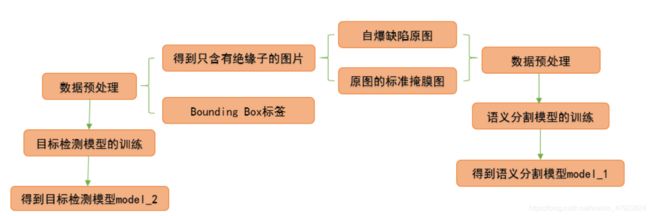
图 1 模型训练流程图
1.3.2模型测试流程图
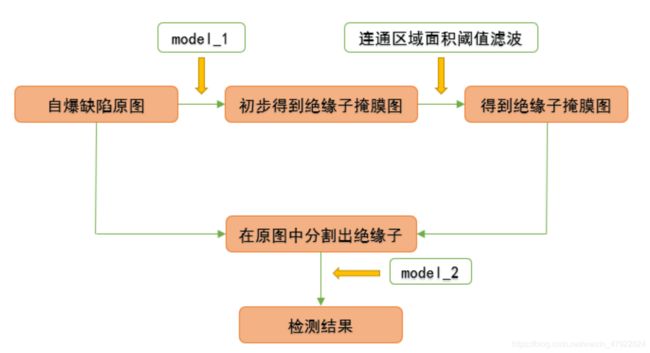
图 2 模型测试流程图
二、基本理论
2.1卷积神经网络
卷积神经网络(CNN)是一种具有稀疏连接和权值共享的深度神经网络模型, 其权值共享的模式减少了训练参数,降低了复杂度,使其变得简单且适应性强, 近年来引起众多科学领域的广泛关注。卷积神经网络直接以图像作为输入,避免 了传统方法提取特征的过程,在图像处理上可保留像素的空间位置关系。其网络 结构对图像的平移、比例缩放、旋转等其他形式的形变具有高度不变性。在卷积 层中,卷积核的作用等同于滤波器,由于 RGB 色彩模式的图像每个通道等同于一个二维矩阵,所以卷积层通过滑动窗口的方式将卷积核与输入图像的每个通道 进行卷积操作,提取出不同类型的特征,称为特征图(feature map, FM),特征图的个数和卷积核的个数相同;池化层又称为子采样层(sub-sampling layer),通过池化操作对数据进行降维,缩小输入数据规模,减少计算量,通常有最大池化、平均池化和随机池化等计算方式;由于卷积和下采样操作造成特征图分辨率降低, 所以利用反卷积层通过插值运算将特征图恢复到输入图像大小,然后输出为二维 矩阵,矩阵的值表示某个像素归属为某一类的概率。卷积网络通过误差反向传播 算法周期性地更新卷积核的权重实现进行求解优化,通过卷积网络模型在数据集 上的误差和精确度确定网络优化程度。
2.2全卷积神经网络
传统的卷积神经网络只能整幅图像进行分类,也就是说只能解决图像识别问题 。全卷积神经网络(FCN)与经典的 CNN 在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层 + softmax 输出)不同,FCN 可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的 feature map 进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类,最后逐个像素计算 softmax 分类的损失, 相当于每一个像素对应一个训练样本,从而解决了图像分割问题。
2.3残差连接
在深度学习中,卷积网络的深度是获得优异性能的重要因素,深层的网络能 够提取到更高级别的特征信息,但随之引起的梯度弥散问题却导致网络无法收敛, 甚至网络退化问题,即增加网络层次反而会导致更大的误差。为了解决该问题,文献[1]通过在一个浅层网络基础上叠加 = 的恒等映射(identify mapping)达到当增加深度时网络性能保持不退化,且理论上允许训练任意深度的网络,其优化方法基本上与网络的深度独立。图 3 为残差连接示意图。左侧连接为残差连接, weight layer 为神经网络中相邻两层。带有残差连接的网络输出公式如下:
y = F ( x , ω i ) + W , x ( 1 ) y=F(x,{\omega_i})+W,x \qquad(1) y=F(x,ωi)+W,x(1)
其中: F 是关于 x 和 ω i {\omega_i} ωi 的函数, F = W 2 σ ( W 1 x ) F=W_2 \sigma(W_1x) F=W2σ(W1x); W i W_i Wi代表神经网络第 i i i层的权值; σ \sigma σ代表激活函数 ReLu; x 是第一层的输入; y 为输出。
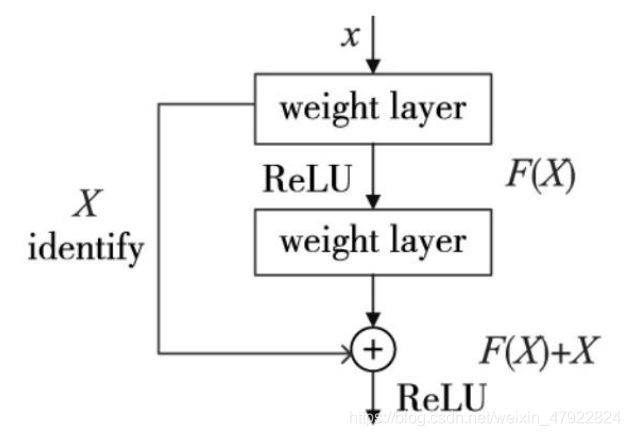 图 3 残差连接示意图
图 3 残差连接示意图
当残差连接的输入和输出维度相同时, W s W_s Ws 退化为 1,维度不同时,通过方阵 W s W_s Ws变换到相同维度。
对于残差 y − x y-x y−x,如果等于 0,则 y = x y=x y=x 就是恒等映射,没有引入额外的参数和计算复杂度,神经网络的负担不会增加;如果不等于 0 但逼近 0,则整个网络只需要学习输入/输出差别的部分即可,简化学习目标。因此,使用残差连接能够保证神经单元的整体输出结果向原始输入靠拢,最大程度地保留主要特征,从而使卷积网络逼近恒等映射,达到最小化误差的目的。
三、数据预处理
3.1 掩膜图像二值化
通过对原始掩膜图像的研究发现,原始的掩膜图像并不是二值图像,如果直接用原始的图像进行模型的训练可能对影响模型的训练效果,所以首先对原始的掩膜图像进行的二值化操作,使得掩膜图像像素值只有 0 和 255 两种像素。
3.2图像切分
由于无人机图片尺寸过大且不统一,不可直接将其作为神经网络的输入。而直接对原图像进行resize 操作会导致图片失真影响训练效果,为了解决这一问题, 本文采用图像切分的方法对原图像进行处理。首先将原图像长宽都 resize 到 256的倍数,然后用 256 × 256 256\times256 256×256 的滑动窗口对原图像进行切割,并以原图像名+每幅图像的位置对切割后的图像进行命名,便于后续对图像进行还原。例如:子图001_10_6.jpg 表示为原图像 001.jpg 的第 10 行第 6 列的位置。原图和其切割后的图像分别如图 4 和图 5 所示。
图 4 原始图像
图 5 切分后的图像
3.3数据扩增
原始数据集共有 40 张无人机图片,经过图像切分后数据集变为了 14459 个子图片,对于深度学习项目来说,数据集是不够的。在此我们通过 OpenCV 对切割后的原图和标注图像进行数据集扩张处理,主要有随机调整大小(让出边缘),图像四周拼接边缘,旋转图像(随机角度),仿射变换(平移),缩放,添加噪声(加入高斯噪声,椒盐噪声)等方法将数据集扩张到了原来的 8 倍。
图 6 数据增强对比图
3.4数据集调整
经过图像切分和数据扩增后数据集被扩增到了 115672 张子图片,由于绝缘子占整张图片的中的很小的一部分,所以在所有的数据集中没有目标(即绝缘子) 的图片占绝大多数,如果把这些图片都放入模型中进行训练,可能会导致模型对背景的识别能力大于对绝缘子的识别能力,导致绝缘子的分割效果不佳。因此, 我们需要将数据集进行调整,使得数据集更加平衡。通过对分割后的标签图像找出所有带有目标的图片一共 15718 张子图片,然后在所有只含背景图片中随机选
出 15718 张图片,构成新的数据集。
表 1 数据集大小变换

3.5预处理流程图
 图 7 图像分割预处理流程图
图 7 图像分割预处理流程图
四、绝缘子串珠分割
4.1图像分割算法
在深度神经网络中使分辨率降低的特征提取部分可以称为编码器,恢复到原图片分辨率的称为解码器,这类网络例如 Unet[2]和 Segnet[4]。
4.1.1Unet 网络
基于全卷积神经网络(FCN),文献[2],提出了一种 U 行结构的全卷机神经网络—Unet。Unet 神经网络模型被广泛的应用到遥感影像和医学影像的语义分割, 该模型是一种编码解码网络结构。其网络结构如图 8 所示,它主要由特征提取部分和上采用还原部分组成,特征提取部分重复地使用了 2 个 3 × 3 3\times3 3×3 卷积层和一个 2 × 2 2\times2 2×2 最大池化层。上采样还原部分使用了两倍的上采样和两个 3 × 3 3\times3 3×3卷积层,每上采样一次都和特征提取部分与之对应的特征图进行拼接,其中每两个 3 × 3 3\times3 3×3 卷积层中第一个 3 × 3 3\times3 3×3 卷积层的作用是降低特征图的数量和提取特征。最后采用Softmax 分类器进行像素级的分类,达到语义分割效果。
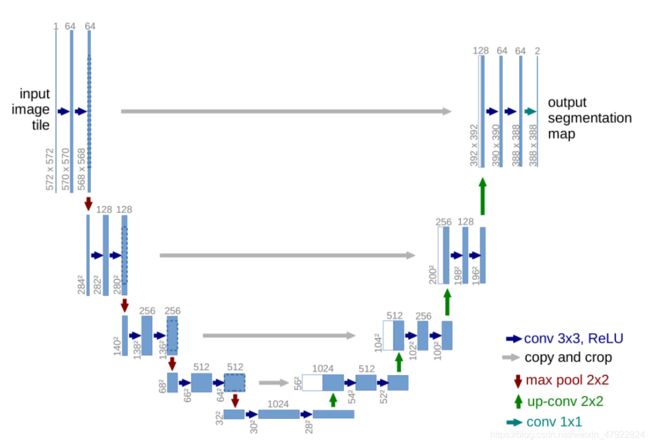
图 8 Unet 网络结构图
4.1.2Segnet 网络
基于全卷机神经网络文献[4]提出了一种新的、实用的用于语义像素分割的深度全卷积神经网络结构 SegNet。Segnet 神经网络是一种以深度卷积为基础,融合编码-解码结构(encoder-decoder)的深度学习网络。编码器网络和解码器网络的对称结构构成了 Segnet 的主要部分,除此之外还有一些输出层。编码器网络由用于图像分类的 VGG16 网络的前 13 层组成,对应图 9 对称结构的左半部分,与完整的 VGG16 网络相比减少了3层,这是由于整个网络结构移除了用在特征提取层之间的全连接层,支持在编码器的深层网络输出中保留更高分辨率的特征图, 同时大幅度减少训练时参数的数量。编码网络部分包括 13 个卷积层(Convolution),其中包括与其配合的批归一化层(Batch Normalization, BN)、激活层 Rectified Linear Unit, ReLU)及池化层(Pooling);解码网络包含相同的 13层卷积层,及与池化层对应的上采样层(Upsampling)。网络最后通过 Softmax 分类器进行像素点分类,完成语义分割。
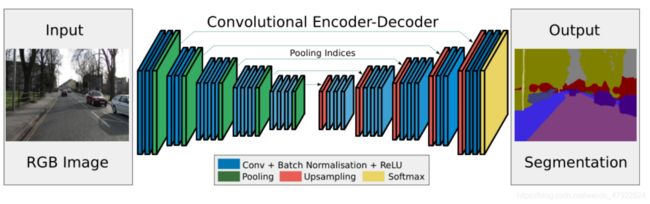
图 9 Segnet 网络结构图
4.1.3U-Segnet 网络
基于 Unet 和 Segnet 神经网络文献[5]在 2018 年提出了一种全卷积神经网络(FCN),它是 SegNet 和 U-Net 两种广泛应用的深度学习分割结构的混合,用于改进脑组织分割,网络结构如图 10 所示。虽然基本架构类似于 SegNet,但创造性地将 Unet 中的跳跃连接结构引入 Segnet 中,这些跳跃连接有助于所提出的网络捕获细粒度多尺度信息,以便更好地识别组织边界。
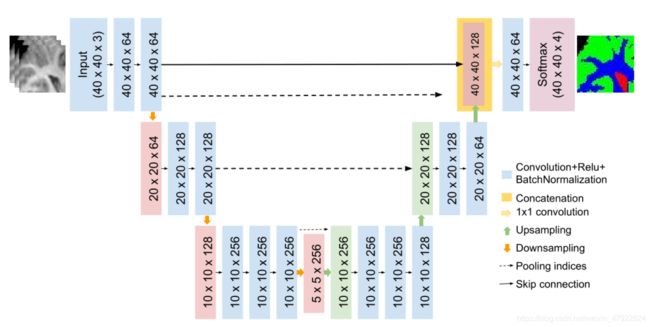 图 10 U-Segnet 网络结构图
图 10 U-Segnet 网络结构图
4.1.4改进的 U-Segnet 网络
本文基于文献[5]提出的 U-Segnet 神经网络模型,提出了一种新的全卷积神经网络(FCN)模型—U-Segnet-Pro,网络结构如图 11 所示。由于本文目的是从无人机图像中分割出绝缘子,而由于无人机图片较大,绝缘子串珠占据图片中很小的 一部分区域,要想更加精确的分割出绝缘子,这就要求提取到图片更深层更精细 的特征,即要求网络达到一定的深度。然而深层的网络能够提取到更高级别的特 征信息,但随之引起的梯度弥散问题却导致网络无法收敛,甚至网络退化问题, 即增加网络层次反而会导致更大的误差。针对此问题文献[1]提出了一种残差网络 结构(Residual Network),该结构解决了由于增加网络深度导致模型退化这一问题。故本文为了得到更好的分割效果,在原始的 U-Segnet 网络编码部分后引入 3 个残差块(Resnet Block)达到增加网络深度的目的。
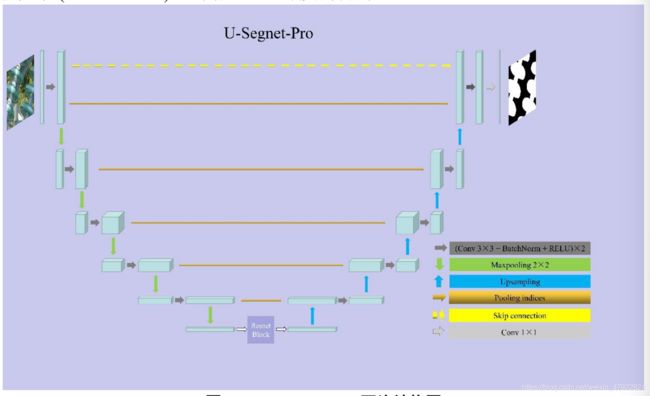
图 11 U-Segnet-Pro 网络结构图
4.2图像分割技术路线
 图 12 图像分割技术路线
图 12 图像分割技术路线
五、连通区域检测
连通域指的是在某个区域内,任意两个像素之间都能够通过由这个区域内的 像素点组成的路径连接起来,并且在这个区域内的所有像素点都具有相似的特征, 一幅二值图像或者多值图像当中可以存在多个连通域,而且任意两个连通域是不 重叠也不会相邻的。连通区域标记是一种在计算机视觉和图像分析处理里面较为 常用的技术,在目标分割与提取、视觉跟踪等领域又很多应用,其主要用来检测 二值图像当中的连通区域并标记,连通域分析方式的使用一般基于先将前景目标 提取出来这样一个前提之上。
将图像分割后得到的图像拼接得到的完整分割图像如图 13 所示,可见除了绝缘子还有一些其他的地方也被分割出来了,这些地方都是一些分散的小点,通过计算连通区域面积,再利用面积阈值即可将其去除。

图 13 图像分割结果
5.1连通域标记与面积计算
从连通域的定义中可以得知,一个连通区域是由具有相同像素值的相邻像素组成的像素集合,也正是通过“相同像素值”和“相邻像素”这两个条件来定位连通域并标记每个连通域。为了保证该标记的唯一性,以此来区别不同的连通域。对于二值图像来说,连通性的判断有两种度量准则,即根据像素的 4 连通和 8 连通两种相邻关系,4 连通域如图 14 所示,八连通域如图 15 所示:

在二值图像中,把符合 4 领域连通域或者 8 领域连通域准则的像素组成的区域标记上唯一的数字,这样的标记就是掩码,通常最大的掩码代表图像中连通域的数目。这样一来,一幅二值图像中的多个目标区域就被分别赋予唯一的标记号,然后对每个掩码所对应的区域做相关记录统计工作,把参数存储到一个存储空间当中。
对一幅二值图像来说,计算其连通域面积就是统计其连通域范围内的白色像素点的个数,以 8 连通域任意一点开始为例,从该点向其邻域开始扫描并延伸至图像边界,在扩展延伸的同时统计白色像素点的数量,由此得到的统计结果就是连通域的面积并将面积值存储到一个一维数组当中。
5.2面积阈值的计算
堆的结构可以分为大根堆和小根堆,是一个完全二叉树,而堆排序是根据堆的这种数据结构设计的一种排序。每个结点的值都小于其左孩子和右孩子结点的值,称之为小根堆。如下图
图 16 小根堆结构示意图
本文采取的是时间复杂度为 0 的“小根堆”方法来确定面积阈值,思路是在存放上一节得到的连通域数组中寻找出和绝缘子串个数保持一致或者接近的 K 个最大值,再从这 K 个值当中选择合适的值,例如平均值或者中值作为设定的面积阈值。经过“小根堆”方法可以得到的所需要的 K 值,此时可以对得到的 K 个值排序,本文取中值 midarea,面积阈值设定为 0.5 × m i d a r e a 0.5 \times midarea 0.5×midarea。利用得到的面积阈值对图 13 做阈值分割,得到的处理结果如图 17 所示:

图 17 连通域面积阈值分割结果
从面积滤波的结果可以看出,图像中复杂的自然背景已经完全被滤除,而且绝缘子串所在的区域也被保留下来了。
六、图像分割结果分析
6.1实验环境
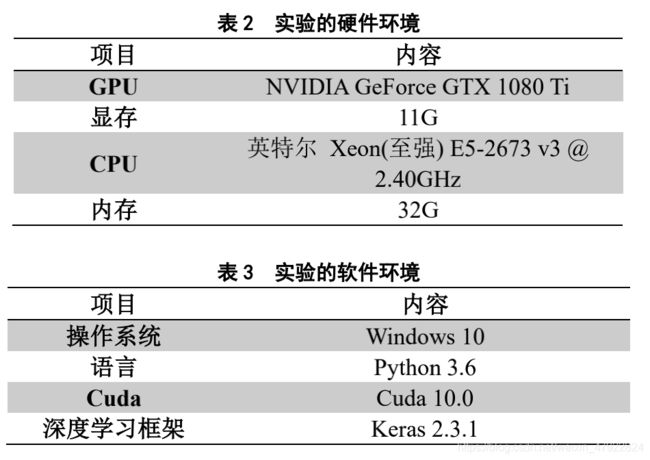
实验采用的机器的硬件环境如表 2 所示,软件环境如表 3 所示。
表 2 实验的硬件环境
表 3 实验的软件环境
6.2评价指标
绝缘子串珠分割采用 Dice 系数进行评价,通常计算两个样本的相似度
d i c e ( A , B ) = 2 ∣ A ∩ B ∣ | A | + | B | dice(A,B)=\frac{2|A \cap B|}{|A|+|B|} dice(A,B)=|A|+|B|2∣A∩B∣
其中,A 为 GroundTruth 区域即专业人士标注的区域,B 为算法分割所得到的区域。Dice 系数取值范围是[0,1],取值越接近 1 则越表明预测的结果与专业人士标注的结果相符合。
6.3实验过程及结果分析
6.3.1训练超参数设置
模型训练的超参数设置如表 4 所示:
表 4 训练超参数设置

学习率(Learning rate)的大小影响参数更新的幅度,如果学习速率过大,可能会使网络不能收敛,如果学习率过小,会导致网络收敛的速度过慢。在深度学习中网络参数进行更新时,开始更新的幅度较大,在接近收敛时更新幅度较小。
如果学习率为一个固定值,在网络快要收敛时会导致越过最优值在最小值附件波动,故在此我们在前 100 epoch 设置学习率大小为 0.001,后 100 epoch 设置为0.0001 进行训练。Batch size 表示每次放入 GPU 进行训练的图片数量,这个值受网络的参数量和 GPU 显存的影响,训练的精度会随着 Batch size 增大而增大, 综合考虑在现有的硬件条件下设为 20。
如图 18 所示,表示在上述超参数设置条件下,模型随着迭代次数的增加训练集的损失情况。

图 18 图像分割损失随迭代次数变化图
6.3.3 结果分析
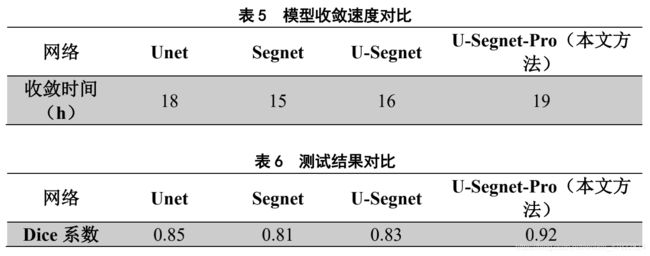
由表 5 和表 6 可知在模型的收敛速度上不如其他网络,但是在模型分割的效果上来看确比其他模型的效果好得多,以少许的收敛速度换取模型的精度,这在工业上是可以接受的。
表 5 模型收敛速度对比
表 6 测试结果对比
七、目标检测数据预处理
7.1数据采集
原始数据集大小为 40,这对目标检测任务来说数据量太少,为了得到较优的模型训练结果,本文首先将原始的数据集进行了扩充。采集了 200 张图片数据,经过人工筛选最终有 46 张图片符合要求,初始数据扩充到 86 张。
7.2人工标注
由于采集到的 46 张图片数据没有掩膜图像,为了不影响模型的训练效果和便于后续进一步提取绝缘子,本文针对这些图像采用人工标注的方法,得到其掩膜图像。使用的标注工具为开源软件 Labelme,其界面如图 19 所示。

图 19 Labelme 软件界面
7.3绝缘子提取
为了提高模型的训练精度,剔除背景对模型训练的影响。本文采用公式(3),利用掩膜图像对原始图像中的绝缘子进行了提取,将绝缘子从图片中分割出来,再放入模型中进行训练。
n e w _ i m g = i m g × m a s k / 255 new\_img=img\times mask/255 new_img=img×mask/255
其中,img 表示原始图片像素值,mask 表示掩膜图片像素值,new _ img 表示提取绝缘子后图片的像素值。
效果图如图 20 所示:

图 20 提取绝缘子前后图片对比
7.4数据增强
经过上述处理后,数据集被扩增到了 86 个,但是对目标检测任务来说还远远不够。故在采用数据增强的方法对数据集进行进一步的扩增。数据增强方法为对原始图片分别进行随机平移,旋转 90 度、180 度、270 度,沿 x 轴翻转,沿 y 轴翻转,颜色通道变换,将数据集扩增了 8 倍。如图 21 所示

图 21 目标检测数据增强对比图
数据集大小变化如下:
表 7 目标检测数据集大小变化
八、目标检测
8.1YOLO v3 算法基本原理
YOLO(you only look once,YOLO)文献[6]是一种基于深度神经网络算法的对象识别和定位算法,将目标检测归类于回归问题,将图片划分为若干网格,在每个网格上通过候选框预测,最终输出每个候选框预测的类别概率和坐标。其特点是运行速度快,可以用于实时系统。在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力。这与绝缘子缺陷检测的应用极为契合。
在基本的图像特征提取方面,YOLO v3 采用了 Darknet-53 网络结构,如图 22 所示,它含有 53 个卷积层,同时借鉴残差网络(residual network)[1],在卷积层之间设置了快捷链路(shortcut connections)。

图 22 Darknet-53 网络结构
Darknet-53 网络采用 256×256×3 作为输入,每个残差组件(residual)有 2 个卷积层和一个快捷链路,如图 23 所示。
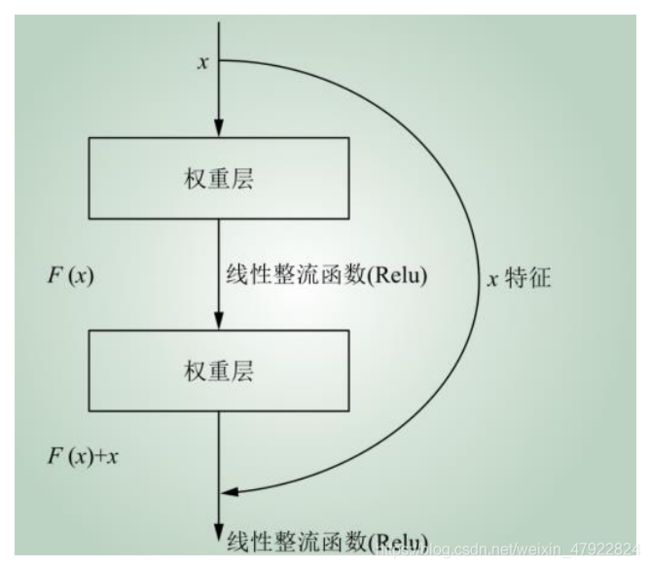
图 23 残差组件
通过引入残差组件,将前若干层的数据输出直接跳过中间层而引入到后面数据层的输入部分,后层的输入特征将有一部分来自其前面某一层的线性贡献。
8.2目标检测技术路线
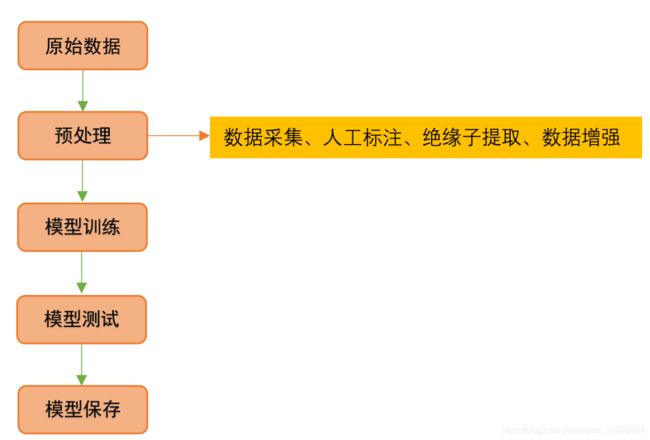
图 24 目标检测技术路线
九、实验及结果分析
9.1评价指标
在此任务中将精度定义为,测试集中检测出来的缺陷框总数占总缺陷框的比重。具体公式如下所示。
A C C = T e s t _ N u m T o t a l _ N u m ( 4 ) ACC=\frac{Test\_Num}{Total\_Num}\qquad(4) ACC=Total_NumTest_Num(4)
其中,ACC 指的是精确度,Test _ Num 指的是测试集中检测出来的缺陷框总数, Total _ Num 指的是总缺陷框数量。
绝缘子自爆区域评价采用 IOU,IOU 表示产生的候选框(Candidate Bound) 与原标记框(Ground Truth Bound)的交叠率或者说重叠度,也就是它们的交集与并集的比值。相关度越高该值。最理想情况是完全重叠,即比值为 1。
I O U = a r e a ( C ) ∩ a r e a ( G ) a r e a ( C ) ∪ a r e a ( G ) ( 5 ) IOU=\frac{ {area(C)}\cap{area(G)}}{ area(C) \cup area(G)} \qquad(5) IOU=area(C)∪area(G)area(C)∩area(G)(5)
9.2实验过程及结果分析
通过对数据集进行扩增,本文共获得 688 张可供训练的绝缘子图片。数据集中包含一串或多串绝缘子,可根据绝缘子是否存在缺陷的情况将其标注为正样本或负样本。进一步将数据集按 9:1 划分,其中训练集占 90%,测试集占 10%。
本文的实验环境如表2 和表3 所示,训练阶段采用异步随机梯度下降法(SDG), 动量项设置为 0.9,权值的初始学习率设置为 0.001,衰减系数设置为 0.0005,采用多尺度训练,历时 2 天,模型的整体损失值稳定在 4.0 左右, 模型的预测示例如图 25 所示。

图 25 模型预测结果示例
YOLO v3 模型与 SSD 模型测试结果对比如表 8 所示,可见 YOLO v3 算法不论是在精度还是 IOU 值大小上均超过 SSD 算法,故 YOLO v3 算法更适合绝缘子的缺陷检测任务。
表 8 测试结果及算法对比

本文也做过直接将没有分割出绝缘子的原始图片放入模型中训练,结果如表9 所示,由表可知,将绝缘子从原始图片中分割出来,大大提高了模型检测的精度和检测 IOU 值。
表 9 是否分割出绝缘子结果对比

十、总结与展望
10.1本文工作总结
本文首先分析了现阶段电力系统人工巡线的弊端和无人机电力巡检的应用研究价值,然后对国内外对航拍图像中绝缘子“自爆”特征识别的研究现状做了说明,介绍了本课题的研究意义与价值,以航拍图像中输电线路的绝缘子“自爆”现象为研究目标。在传统计算机视觉及图像处理相关技术的绝缘子“自爆”特征识别算法的比较基础上,巧妙的采用语义分割与目标检测结合的方式,大大提高了绝缘子“自爆”检测的精度。本文所做的工作主要包括以下三个方面:
1.分析了传统的人工巡检存在的一些问题,然后针对这些问题,提出了用无人机电力巡检结合图像处理与机器学习(深度学习)的方法,对图片进行标注。
2.本文首先直接将原始图像放入 YOLO v3 模型中进行模型的训练,发现训练出来的模型在测试集上的精度较低,原因是无人机拍摄的绝缘子图片存在背景复杂、背景与绝缘子的区分度低、绝缘子种类繁多、数据集覆盖面窄等问题。针对这些问题本文提出先将绝缘子从原始图片中分割出来, 然后再利用 YOLO v3 模型进行训练。
3.将绝缘子从原始图片中分割出属于图像分割中的语义分割,经过多个模型的对比本文使用的语义分割模型是 U-Segnet-Pro,这个模型是在 U- Segnet 的基础上增加网络深度并加入残差块构成。在经过语义分割后的图片除了含有绝缘子外,还有一些其他的“杂点”,为了得到更加纯净的绝缘子串,再采用连通区域面积滤波对图片进行小连通区域的剔除。得到分割出来的掩膜图后,结合原始图像即可将绝缘子分割出来。最后将分割后的绝缘子图片带入 YOLO v3 模型中训练即得到精度较高绝缘子“自爆” 检测模型。
10.2未来工作展望
虽然本文训练出来的模型在测试集上取得了不错的效果,但想要真正使用到实际生活中,仍然具有一定的局限性。
主要有以下三个方面:
1.使用本文提出来的方法对绝缘子“自爆”进行检测,需要先使用图像分割模型将绝缘子从原始图像中分割出来,再利用目标检测模型进行检测。相比传统的检测方法而言,模型的实时性较低,所以这是未来要研究和解决的一个问题。
2.在本文的第五个部分连通区域检测中,进行连通区域面积阈值分割时,有少量的图片,并不能刚好只剩下绝缘子部分,会含有部分背景区域,这个背景区域可能对模型的训练结果产生一定的影响,未来在阈值取值部分可进行深入研究。
3.输电线路所处环境复杂多变,本文提出的绝缘子“自爆”检测模型,所使用的数据集都是比较清晰、明亮的数据,使用这种数据训练出来的模型的鲁棒性不高,在阴雨天,或者是光线较暗的恶劣环境下对模型的精度会有一定的影响。所以提出能够在恶劣环境仍然具有较好适应性和稳定性的识别算法问题是未来研究的一个方向。
参考文献
[1]Deep residual learning for image recognition. He K,Zhang X,Ren S,et al. IEEE Conference on Computer Vision and Pattern Recognition . 2016
[2]U-Net:Convolutional Networks for Biomedical Image Segmentation.
Ronneberger O,Fischer P,Brox T. . 2015
[3]Fully convolutional networks for semantic segmentation. Long J,Shelhamer E,Darrell T. IEEE Transactions on Patern Analysis and Machine Intelligence . 2014
[4]SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla, Senior Member, IEEE . 2016
[5]U-SEGNET: FULLY CONVOLUTIONAL NEURAL NETWORK BASED AUTOMATED BRAIN TISSUE SEGMENTATION TOOL. Pulkit Kumar,Pravin Nagar,Chetan Arora,Anubha Gupta,Indraprastha Institute of Information Technology-Delhi (IIIT-Delhi), Delhi, India . 2018
[6]YOLOv3: An Incremental Improvement. Joseph Redmon, Ali Farhadi,University of Washington.2018
[7]王兵,李文璟,唐欢.改进 Yolo v3 算法及其在安全帽检测中的应用[J/OL].计算机工程与应用:1-11[2020-05-
03].http://kns.cnki.net/kcms/detail/11.2127.TP.20200225.1117.002.html.
[8]鞠默然,罗海波,王仲博,何淼,常铮,惠斌.改进的 YOLO V3 算法及其在小目标检测中的应用[J].光学学报,2019,39(07):253-260.
[9]张凯航,冀杰,蒋骆,周显林.基于 SegNet 的非结构道路可行驶区域语义分割[J]. 重庆大学学报,2020,43(03):79-87.
[10]杨凯,孙志毅,王安红,刘瑞珍,王银,孙前来,康晓丽.基于 YOLO 网络系统的材料缺陷目标检测方法研究[J/OL].系统科学学报,2020(03):70-75[2020-05- 03].http://kns.cnki.net/kcms/detail/14.1333.n.20200224.1123.028.html.
[11]林志成, 缪希仁, 江灏, 陈静, 刘欣宇, 庄胜斌.基于深度卷积神经网络的输电线路防鸟刺部件识别与故障检测[J/OL].电网技术:1-11[2020-05-
03].https://doi.org/10.13335/j.1000-3673.pst.2019.1775.
[12]张焕坤,李军毅,张斌.基于改进型 YOLO v3 的绝缘子异物检测方法[J].中国电力,2020,53(02):49-55.
[13]罗元,王薄宇,陈旭.基于深度学习的目标检测技术的研究综述[J].半导体光电,2020,41(01):1-10.
[14]王孝余,韩冰,李丹丹,罗军,黄胜,张杰.基于视觉的绝缘子缺陷检测方法[J].计算机工程与设计,2019,40(12):3582-3587.
[15]杨文斌. 基于深度学习的图像语义分割关键技术与方法研究[D].南京邮电大学,2019.
[16]黄友文,游亚东,赵朋.融合卷积注意力机制的图像描述生成模型[J].计算机应用,2020,40(01):23-27.
[17]崔振超. 基于 Unet 的舌体分割算法[C]. 中国中西医结合学会诊断专业委员会.中国中西医结合学会诊断专业委员会第十三次全国学术研讨会论文集.中国中西医结合学会诊断专业委员会:中国中西医结合学会,2019:8.
[18]汪志文. 基于深度学习的高分辨率遥感影像语义分割的研究与应用[D].北京邮电大学,2019.
[19]卢秋芬. 基于机器视觉竹条缺陷识别技术研究[D].福建农林大学,2019.
[20]鞠默然,罗海波,王仲博,何淼,常铮,惠斌.改进的 YOLO V3 算法及其在小目标检测中的应用[J].光学学报,2019,39(07):253-260.
[21]吕易航. 航拍图像中绝缘子串检测、分割与自爆故障识别方法研究[D].郑州大学,2019.
[22]苏健民,杨岚心,景维鹏.基于 U-Net 的高分辨率遥感图像语义分割方法[J].计
算机工程与应用,2019,55(07):207-213.
[23]唐静. 基于深度学习的结直肠病理辅助诊断方法研究[D].东南大学,2018.
[24]袁兵. 基于全卷积神经网络的图像分割算法的研究及应用[D].电子科技大学,2018.
[25]温佩芝,苗渊渊,周迎,冯丽园.基于卷积神经网络改进的图像自动分割方法[J].
计算机应用研究,2018,35(09):2848-2852.
[26]熊杰. 航拍图像的绝缘子自爆特征识别研究[D].电子科技大学,2016.
附录
1.SSD 算法简介:
SSD 算法,其英文全名是 Single Shot MultiBox Detector。从名字可看出SSD 是属于 one-stage 方法的多框预测。SSD 是以 VGG16 为基础模型,然后在 VGG16 的基础上增加了卷积层以此来获得更多的特征图,把这些特征图用于后续的检测。SSD 网络模型如下图所示。

SSD 算法网络结构
2.SSD 的基本步骤:
1.输入一幅图片,让图片经过卷积神经网络(CNN)提取特征,并生成feature map。
2.抽取其中六层的 feature map,然后再 feature map 的每个点上生成 default box(各层的个数不同,但每个点都有)。
3.将生成的所有 default box 都集合起来,全部丢到 NMS(极大值抑制)中, 输出筛选后的 default box,并输出。