1.从传统三层架构与DDD分层架构的编程演变其实是思想的演变。
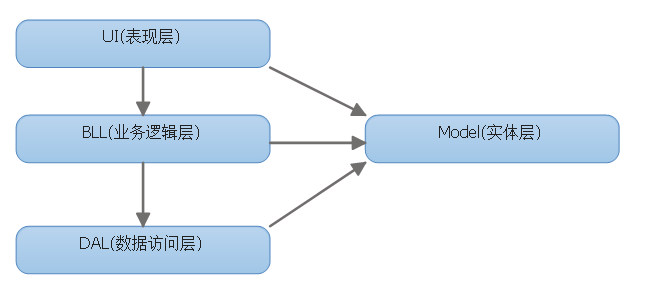
传统三层架构,即用户界面层UI、业务逻辑层BAL、数据访问层DAL。一般同时还有建立一个Model实体类的工程项目。DDD分层架构,即表现层UI、应用层Application、领域驱动层Doman、基础设施层Infrastructure。
传统三层架构,我一直使用、结构单一、逻辑也清晰,三层各处理各自的事务,上层向下层引用接口与方法,下层向上层提供接口服务,各层之间调度方法时可能通过Model传值,也可以返回值Model。但以往,我处理的业务逻辑层中,基本上都是将DAL层的接口值返回给业务逻辑层,然后BLL层再将结果返回给UI层,BLL层只做了上传下达的作用,其它的作用发挥得较少。以往三层架构中的重点是BLL层。当我需要新增业务功能时,或者需要CRUD操作,需要将UI层、BLL层、DAL层都需要增加类文件以达到处理CRUD操作的功能。当然,传统三层架构中,也会引入一个新的Common工程或Utility工程,为BLL、DAL、UI提供共用或通用方法或行为的支持。若是有需要对第三方软件或系统提供数据接口,这时,可以将接口作为IIS站点或WebService 或WebAPI提供,此时这个接口可以放在UI供第三方调用。
DDD分层架构,是从传三层架构中演变过来的。它将传统的三层架构做了一定的变更,将四个层中的内容做了重新归内,并对分层结构的业务重点作了分配。UI层还是UI层、应用层用于调度第三方的应用接口、以及提供口服务给第三方,同时将在应用层增加Dto工程项目用于操作应用层与UI层的数据传递即值对象传递以及Dto与Model实体类之间的映射,将传统的BLL层、Model层归纳到领域驱动层Domain中,同时将仓储的接口层放在Domain层中,将传统的DAL层实现以及通用的Common层或Utility层归纳到基础设施层Infrastructure中。
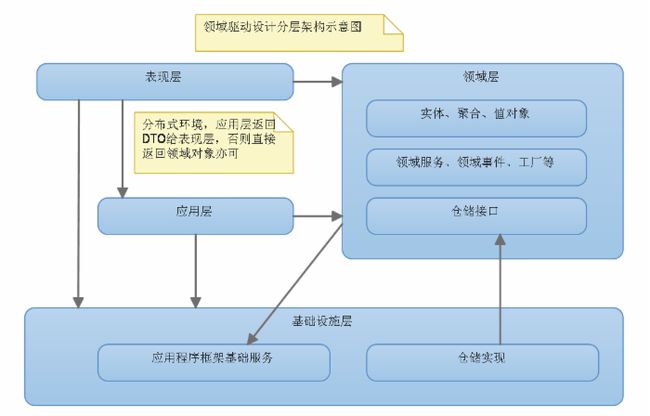
从传统三层架构(包括Common公共层、Model实体层)演变到DDD领域驱动模型设计的分层架构,从项目归纳上比较,可能多了DAL接口层即仓储接口层,其它的工程项目只是做了位置上的迁移。同时传统BLL层的命名变理为Service,同时在应用层增加了Dto工程项目。
2.通过例子说明DDD相对于三层架构的好处:
例子: 假设现在有一个银行支付系统项目,其中的一个重要的业务用例是账户转账业务。系统使用迭代的方式进行开发,在1.0版本中,该用例的功能需求非常简单,事件流描述如下:
主事件流:
1) 用户登录银行的在线支付系统
2) 选择用户在该银行注册的网上银行账户
3) 选择需要转账的目标账户,输入转账金额,申请转账
4) 银行系统检查转出账户的金额是否足够
5) 从转出账户中扣除转出金额(debit),更新转出账户的余额
6) 把转出金额加入到转入账户中(credit),更新转入账户的余额
备选事件流:
4a)如果转出账户中的余额不足,转账失败,返回错误信息
A、面向过程的设计方式(贫血模型)
设计方案如下(忽略展示层部分)[V1.0.0]:
1) 设计一个账户交易服务接口AccountingService,设计一个服务方法transfer(),并提供一个具体实现类AccountingServiceImpl,所有账户交易业务的业务逻辑都置于该服务类中。
2) 提供一个AccountInfo和一个Account,前者是一个用于与展示层交换账户数据的账户数据传输对象,后者是一个账户实体(相当于一个EntityBean),这两个对象都是普通的JavaBean,具有相关属性和简单的get/set方法。

这时候,新需求来了,在1.0.1版本中,需要为账户转账业务增加如下功能,在转账时,首先需要判断账户是否可用,然后,账户的余额还要分成两部分:冻结部分和活跃部分,处于冻结部分的金额不能用于任何交易业务,我们来看看变更后的代码 [V1.0.1]:

这时候,1.0.2的需求又来了,需要在每次交易成功后,创建一个交易明细账,于是,我们又必须在transfer()方面里面增加创建并持久化交易明细账的业务逻辑 [V1.0.2] :

业务需求不断复杂化:账户每笔转账的最大额度需要由其信用指数确定、需要根据银行的手续费策略计算并扣除一定的手续费用……,随着业务的复杂化,transfer()方法的逻辑变得越来越复杂,逐渐形成了上文所述的成百上千行代码。有经验的程序员可能会做出类此“方法抽取”的重构,把转账业务按逻辑划分成若干块:判断余额是否足够、判断账户的信用指数以确定每笔最大转账金额、根据银行的手续费策略计算手续费、记录交易明细账……,从而使代码更加结构化。这是一个好的开始,但还是显然不足。
假设某一天,系统需求增加一个新的模块,为系统增加一个网上商城,让银行用户可以进行在线购物,而在线购物也存在着很多与账户贷记借记业务相同或相似的业务逻辑:判断余额是否足够、对账户进行借贷操作(credit/debit)以改变余额、收取手续费用、产生交易明细账……
面对这种情况,有两种解决办法 [V1.0.3] :
1) 把AccountingServiceImpl中的相同逻辑拷贝到OnlineShoppingServiceImplementation中;
2) 让OnlineShoppingServiceImpl调用AccountingServiceImpl的相同服务.
显然,第二种方法比第一种方法更好,结构更清晰,维护更容易。但问题在于,这样就会形成网上商城服务模块与账户收支服务模块的不必要的依赖关系,系统的耦合度高了,如果系统为了更灵活的伸缩性,让每个大业务模块独立进行部署,还需要因为两者的依赖关系建立分布式调用,这无疑增加了设计、开发和运维的成本。
有经验的设计人员可能会发现第三种解决办法:把相同的业务逻辑抽取成一个新的服务,作为公共服务同时供上述两个业务模块使用。这就是笔者将会马上讨论的方案——使用领域驱动设计。
B.面向过程的领域驱动设计方式(充血模型)
为了节省篇幅,这里就直接以最复杂的业务需求来进行设计。
领域驱动设计的一个重要的概念是领域模型,首先,我们根据业务领域抽象出以下核心业务对象模型:
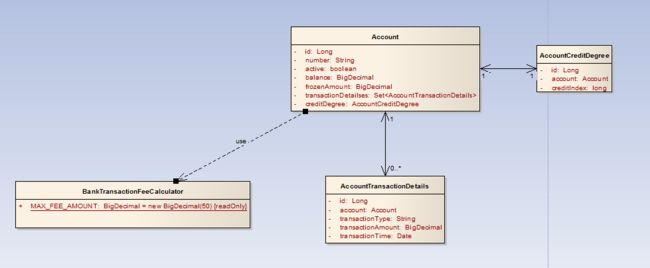
Account:账户,是整个系统的最核心的业务对象,它包括以下属性:对象标识、账户号、是否有效标识、余额、冻结金额、账户交易明细集合、账户信用等级。
AccountTransactionDetails: 账户交易明细,它从属于账户,每个账户有多个交易明细,它包括以下属性:对象标识、所属账户、交易类型、交易发生金额、交易发生时间。
AccountCreditDegree: 账户信用等级,它用于限制账户的每笔交易发生金额,包含以下属性:对象标识、对应账户、信用指数。
BankTransactionFeeCalculator: 银行交易手续费用计算器,它包含一个常量:每笔交易的手续费上限。
我们知道,领域对象除了具有自身的属性和状态之外,它的一个很重要的标志是,它具有属于自己职责范围之内的行为,这些行为封装了其领域内的领域业务逻辑。于是,我们进行进一步的建模,根据业务需求为领域对象设计业务方法:
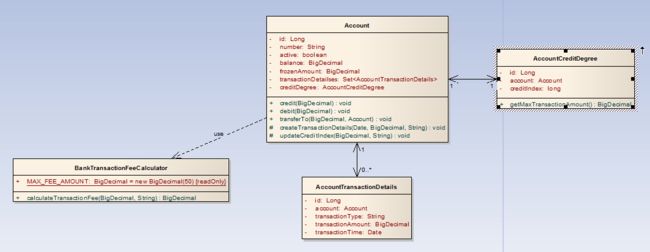
根据职责单一的原则,我们把功能需求中描述的功能合理的分配到不同的领域对象中:
Account:
credit:向银行账户存入金额,贷记
debit:从银行账户划出金额,借记
transferTo:把固定金额转入指定账户
createTransactionDetails:创建交易明细账
updateCreditIndex:更新账户的信用指数
(我们可以看到,后两个业务方法被声明为protected,具体原因见后述)
AccountCreditDegree:
getMaxTransactionAmount:获取所属账户的每笔交易最大金额
BankTransactionFeeCalculator:
calculateTransactionFee:根据交易信息计算该笔交易的手续费
经过这样的设计,前例中所有放置在服务对象的业务逻辑被分别划入不同的负责相关职责的领域对象当中,下面的时序图描述了AccountingServiceImpl的转账业务的实现逻辑(为了简化逻辑,我们忽略掉事物、持久化等逻辑):
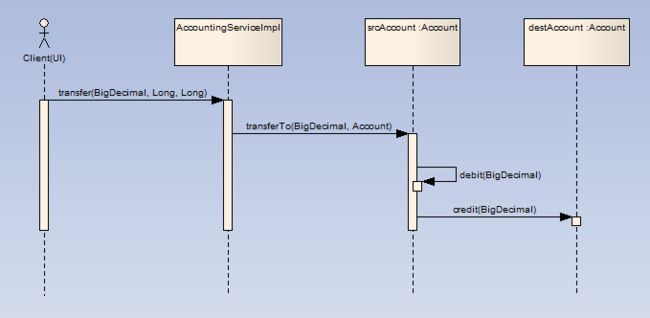
再看看AccountingServiceImpl.transfer()的实现逻辑:
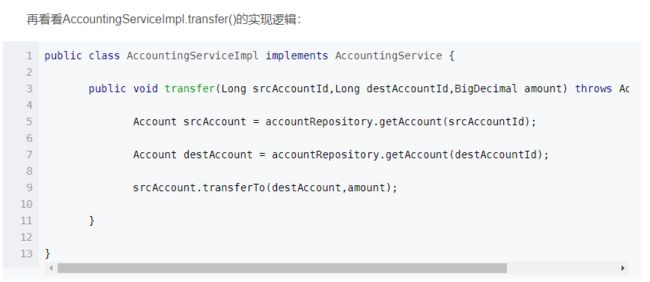
我们可以看到,上例那些复杂的业务逻辑:判断余额是否足够、判断账户是否可用、改变账户余额、计算手续费、判断交易额度、产生交易明细账……,都不再存在于AccountingServiceImplementation的transfer方法中,它们被委派给负责这些业务的领域对象的业务方法中去,现在应该猜到为什么Account中有两个方法被声明为protected了吧,因为他们是在debit和credit方法被调用时,由这两个方法调用的,对于AccountingServiceImpl来说,由于产生交易明细(createTransactionDetails)和更新账户信用指数(updateCreditIndex)都不属于其职责范围,它不需要也无权使用这些逻辑。
我们可以看到,使用领域驱动设计至少会带来下述优点:
业务逻辑被合理的分散到不同的领域对象中,代码结构更加清晰,可读性,可维护性更高;
对象职责更加单一,内聚度更高;
复杂的业务模型可以通过领域建模(UML是一种主要方式)清晰的表达,开发人员甚至可以在不读源码的情况下就能了解业务和系统结构,这有利于对现存的系统进行维护和迭代开发;
再看看如果这时需要加入网上商城的一个新的模块,开发人员需要怎么去做,还记得上面提过的第三种方案吗?就是把账户贷记和借记的相关业务抽取到成一个公共服务,同时供银行在线支付系统和网上商城系统服务,其实这个公共的服务,本质上就是这些具有领域逻辑的领域对象:Account、AccountCreditDegree、……,由此我们又可以发现领域驱动设计的一大优点:
系统高度模块化,代码重用度高,不会出现太多的重复逻辑。
3.DDD中分层架构
在分解复杂的软件系统时,分层是我们最常用的手段之一。然而,在领域驱动设计中,层次和包的划分看起来与我们的结构又有一定区别,本文主要讨论DDD中的分层架构及每层的意义,以及与传统的三层架构的区别。
为什么要分层
软件设计中分层的设计随处可见,但是分层能带来什么好处呢?或者说,我们为什么要考虑分层架构呢?
由于现实世界的复杂性,分层可以提供一个相对高层的视角来分解和简化我们的问题,此外分层也可带来可测试、可维护性、灵活性、可扩展性等方面的好处。
简化复杂性,关注点分离,结构清晰;
降低耦合度,隔离层次,降低依赖(上层无需关注下层具体实现),利于分工、测试和维护(可维护性);
提高灵活性,可以灵活替换某层的实现;
提高扩展性,方便实现分布式部署;
看起来十分简单,好像就是把系统划分为一定的层数,并把他们堆叠组织起来。但是,当落实到具体的实践时,如何划分、各层存在的意义、如何取舍以及相应的依赖关系却并没有想象中那么容易,边界的重合部分、不同场景下关注点、层次内部的具体分解以及层次的粒度等都是我们需要考虑的问题。
什么是分层架构
2.1 分层的历史
最广为人知的应该就是经典的三层架构:展示层、业务逻辑层、数据访问层。
Martin Fowler在《企业应用架构模式》中也是类似的三层进行展开的:表现层,领域层,数据源层。
还有各种其他分层架构,这里就不一一描述了。
面对如此多的分层架构,我们不禁思考,他们分层的依据又是什么?能否抽象出一些相同点和不同点?又该在什么时候加入哪些合适的中间层?在实践中我们又该采取怎样的架构呢?
2.2 分层的本质
分层其实是把一系列相同或相似的对象进行分类放在同一层,然后根据他们之间的依赖关系再确定上下层次关系。可以看出,分层的核心在于分类和关联。
通常,我们可以将系统划分为变化较大的业务部分和相对稳定的技术部分;对于业务来说,又可划分为展示部分(前台)和内部处理逻辑(后台)两大部分;展示又可分为数据/页面部分和接口部分。如此不断的进行细分和抽象,我们可以迭代出更细粒度的分类/层次,如下所示:
业务:需要重点关注,我们的目的也是分离出具体的业务领域逻辑:
外部展示(表现层/接口层):数据、页面(web)、远程接口(interface/api)
内部逻辑处理:应用逻辑(应用层/服务层)、具体业务逻辑(领域层)
技术:相对稳定,具体业务无关(基础设施层)
数据访问(数据访问层)
日志、安全、异常、缓存等
当然,分类并不唯一,基于不同的视角我们可能会有不同的分类标准。比如数据访问层也可以归类到业务相关/内部逻辑处理的部分,因为可能涉及到一些对具体业务表的操作。
此外,根据问题领域和解决方案的复杂程度,我们可以有不同的层次。比如在业务不太复杂时,我们可以把应用层和领域层合并为一层。
DDD经典分层架构
上面我们在分析分层的本质时也提到了一些基本的层次和分类标准,但那只是一个非常粗粒度的划分。
在实际决策时,我们需要知道各层的职责、意义以及相应的场景;而落实到代码层面时,我们还需要知道各层所包含的具体内容、各层的一些常见的具体策略/模式、层次之间的交互/依赖关系。
首先我们来看一下Evans在《领域驱动设计》中提到的分层架构。
问:为什么要分成这样的四层?
分层主要目的是为了简化复杂性,系统中最复杂的部分应该就是我们的业务逻辑。当系统交互或者工作流比较复杂时,我们会考虑从业务逻辑中抽出这部分作为应用层。而各个领域内的代码则化为领域层,这样层级结构更加清晰。
3.1 用户界面层/表示层
用户界面层负责向用户显示信息和解释用户指令。这里指的用户可以是另一个计算机系统,不一定是使用用户界面的人。
该层包含与其他应用系统(如web服务、RMI接口或web应用程序以及批处理前端)交互的接口与通信设施。
它负责输入参数的解释、验证以及转换。另外,它也负责输出参数的序列化,如通过HTTP协议向web浏览器或web服务客户端传输HTML或XML,或远程Java客户端的DTO类和远程外观接口的序列化。
可以看出,该层的主要职责是与外部用户(包括web服务、其他系统)交互,如接受用户的反馈,展示必要的数据信息。主要包含web部分和远程服务部分等。
web部分一般包含常见的Servlet,Controller等组件,而远程接口部分主要由Facade、DTO和Assembler等构成。
Facade:远程外观,一个粗粒度的外观,不含任何领域逻辑
DTO:数据传输对象
Assembler:对象组装器,负责数据传输对象与领域对象相互转换,不对外暴露
问:参数的校验为什么在用户界面层?领域层的校验和用户界面层的校验有什么不同?
校验应该取决于校验的内容,一般推荐尽早校验,不过这里主要是进行一些简单的、不涉及业务规则的校验。具体的业务规则的校验放在领域层。
问:为什么需要DTO?DTO和VO是同一个东西吗?
领域对象关系比较复杂,很难序列化,而且用户很多时候并不需要整个模型,大部分时候需要的只是其中的一部分内容,DTO可以有效减少网络调用的开销。此外,领域模型内部的逻辑也无需暴露给外部。
DTO一般用于远程服务,如果是内部使用的话,一般可以直接使用领域对象。
VO中有前端状态信息,比如成功失败等。
问:为什么需要Assembler?
主要目的是解耦,负责数据传输对象和领域对象之间的相互转换。BeanUtils也可以做到相应的功能(dozer相对好一些),不过Assembler更为清晰,安全与可控,缺点在于手工代码量稍多。
3.2 应用层
应用层定义了软件要完成的任务,并且指挥表达领域概念的对象来解决问题。该层所负责的工作对业务来说意义重大,也是与其他系统的应用层进行交互的必要通道。
应用层要尽量简单。它不包含任务业务规则或知识,只是为了下一层的领域对象协助任务、委托工作。它没有反映业务情况的状态,但它可以具有反映用户或程序的某个任务的进展状态。
应用层主要负责组织整个应用的流程,是面向用例设计的。该层非常适合处理事务,日志和安全等。相对于领域层,应用层应该是很薄的一层。它只是协调领域层对象执行实际的工作。
综上所述,应用层是表达user case和user story的主要手段,主要用于协调领域模型与其他应用组件的工作(并不处理业务逻辑)。
应用层中主要组件是Service,因为主要职责是协调各组件工作,所以通常会与多个组件交互,如其他Service,领域对象,Repostitory等。
一种比较常见的做法是:应用层通常接受来自用户界面层的参数,再通过Repostitory获取到聚合示例,然后执行相应的命令操作(很薄的一层)。
问:为什么要有应用层?
业务比较复杂时,我们会从业务逻辑中拆分出应用层和领域层。
如果在领域对象中事先针对具体应用的逻辑,会降低应用之间的可重用性。
此外,如果将来需要加工作流之类的工具来实现应用逻辑,如果之前是混杂在一起的话则不好拆分。
3.3 领域层/模型层
领域层主要负责表达业务概念,业务状态信息和业务规则。
Domain层是整个系统的核心层,几乎全部的业务逻辑会在该层实现。
领域模型层主要包含以下的内容:
实体(Entities):具有唯一标识的对象
值对象(Value Objects): 无需唯一标识
领域服务(Domain Services): 一些行为无法归类到实体对象或值对象上,本质是一些操作,而非事物
聚合/聚合根(Aggregates & Aggregate Roots): 聚合是指一组具有内聚关系的相关对象的集合,每个聚合都有一个root和boundary
工厂(Factories): 创建复杂对象,隐藏创建细节
仓储(Repository): 提供查找和持久化对象的方法
关于各个元素的具体含义、职责以及相关误区,可参考领域建模核心概念解析.
对于这些具体的对象,可定义一些标准领的Annotation来规范。
3.4 基础设施层
基础设施层为上面各层提供通用的技术能力:为应用层传递消息,为领域层提供持久化机制,为用户界面层绘制屏幕组件。
基础设施层以不同的方式支持所有三个层,促进层之间的通信。
基础设施包括独立于我们的应用程序存在的一切:外部库,数据库引擎,应用程序服务器,消息后端等。
作为基础设施层,Infrastructure为Interfaces、Application和Domain三层提供支撑。所有与具体平台、框架相关的实现会在Infrastructure中提供,避免三层特别是Domain层掺杂进这些实现,从而“污染”领域模型。Infrastructure中最常见的一类设施是对象持久化的具体实现。
问: Repository作用是什么?和DAO的关系
之前对Repository也曾有过误解(在我们的系统中有一个repository层位于dao和service之间)。
DAO主要是从数据库表的角度来看待问题的,并且提供CRUD操作(只是对数据库表的一个封装),是一种面向数据处理的风格(事务脚本);
而Repository(资源库)和Data Mapper(数据映射器)更加面向对象,通常用于领域模型中。
因为数据访问层的暴露可能会破坏对象的封装性,对象的关系和数据一致性也难以维护,所以 应该尽量避免在领域模型中使用DAO模式,推荐使用聚合本身来管理业务逻辑。
模型的形态
不同的架构、不同的层、不同的应用场景中有着不一样的建模需求,因此表达相同概念的模型可能会有不同的形态,例如:
充血模型:领域模型架构中包含了领域逻辑和领域属性的领域模型。
失血模型:传统三层架构中只有get/set方法,没有业务逻辑的POJO对象。
贫血模型:类似充血模型,但是不包括持久化相关逻辑。
PO(Persistant Object):持久化对象,即DAO从JDBC取出来的对象。传统三层架构中,PO即POJO组件中的对象,存在于DAO和Service之间。
DO(Domain Object):领域对象,领域模型架构中,PO从数据库取出来后,有一个“重建”的概念,即根据数据还原实体,这个被还原的实体就是DO,存在于DAO和Service之间。
DTO(Data Transfer Object):数据传输对象。对传统三层架构来说,该对象存在于Service和Controller之间。PO到DTO的转换可以在Service或Controller中实现。
VO(View Object):视图对象。Controller在返回DTO给视图时,可能还需要包括状态信息例如操作成功/失败的状态码、提示文本等。这时就需要在DTO外面再包一层,即View Object。该对象存在于Controller和Web之间,由Controller进行装配