爬虫04-BeautifulSoup使用(简)
BeautifulSoup-网页解析库
要说明的是,前提是能够成功访问网页,获取网页内容,然后才能使用工具解析。
这里是直接在解析这一步介绍工具的使用。
from bs4 import BeautifulSoup
1. 解析库
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库、执行速度适中 、文档容错能力强 | Python 2.7.3 or 3.2.2)前的版本中文容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, “xml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
2. 基本使用
构造一段html以举例:
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#上面这段是不完整的html代码,用bs可以解析
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.prettify(),'\n') #格式化代码
print('title内容:',soup.title.string) #打印title的内容

3. 标签选择器
3.1 获取整个标签
可以直接用 . +标签名称 来选择标签,这样选出来的是整个元素内容(< >里面的以及标签的具体内容)
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title)) #tag类型
print(soup.head)
print(soup.p) #只输出了一个p标签,默认输出第一个匹配结果

还可以获取标签的名称:
.name函数
soup = BeautifulSoup(html, 'lxml')
print(soup.p.name) #获取最外层标签的名称/title
输出:p
3.2 获取标签属性
.标签名称[‘属性’]
soup = BeautifulSoup(html, 'lxml')
print(soup.a.attrs['href']) #获取链接!
print(soup.p['name'])
输出:
http://example.com/elsie
dromouse
3.3 获取标签内容
.标签.string
soup = BeautifulSoup(html, 'lxml')
print(soup.title.string)
输出:
The Dormouse’s story
3.4 嵌套选择
在标签嵌套比较多,尤其是网页打开,源代码会有很多标签,大标签的名字相同,但大标签里面嵌套的小标签及内容不同,这时需要嵌套选择来区分。
使用 . 来层层迭代
soup = BeautifulSoup(html, 'lxml')
print(soup.head.title.string) #层层迭代的嵌套选择
print(soup.body.p['name']) #默认选择第一个p标签
输出:
The Dormouse’s story
dromouse
3.5 子节点和子孙节点
用另一段html举例:
html = """
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
Lacie
and
Tillie
and they lived at the bottom of a well.
...
"""
(1)选择子节点:
soup = BeautifulSoup(html, 'lxml')
print(soup.p.contents)

得到的是p标签下包含的标签子节点
或者循环的方式(更清晰)
soup = BeautifulSoup(html, 'lxml')
print(soup.p.children) #是一个迭代器类型,需要用循环提取信息
for i, child in enumerate(soup.p.children):
print(i, child) #打印索引和内容

使用for循环分别选出下一层每一个子节点(只见儿子的面,不管儿子带没带孙子)
(循环的思路在提取内容是很有用!)
(2)选择所有子孙节点
soup = BeautifulSoup(html, 'lxml')
print(soup.p.descendants)
for i, child in enumerate(soup.p.descendants):
print(i, child)
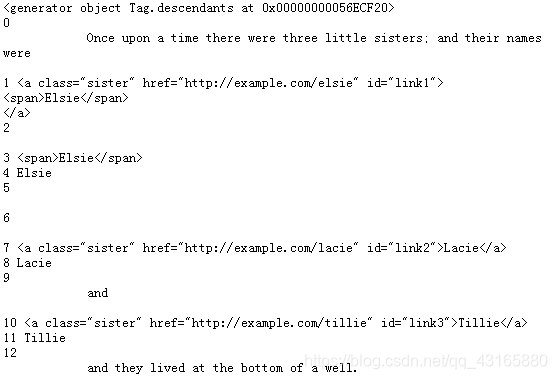
所有子孙节点都被选出来了,不管大小(儿子和孙子的面都见,只要有)。
3.6 父节点和祖先节点
刚才是往下选,现在是往上选。
还是刚才的一段html:
html = """
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
Lacie
and
Tillie
and they lived at the bottom of a well.
...
"""
(1)选择上一层:
soup = BeautifulSoup(html, 'lxml')
print(soup.a.parent)

选出来的是a节点的上一层父节点(见爸爸)。
(2)选择上上一层…
soup = BeautifulSoup(html, 'lxml')
for i,parent in enumerate(soup.a.parents):
print(i,parent)
print('\n')
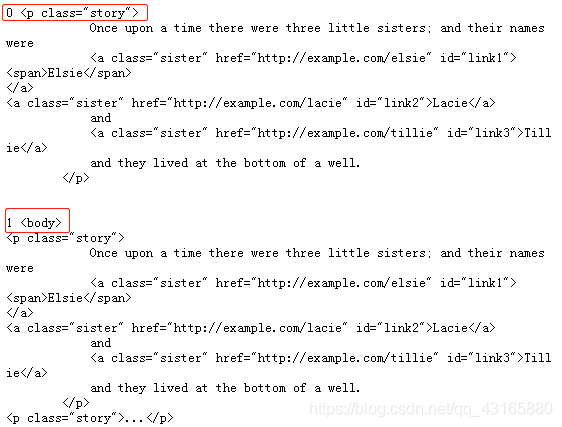
选出来的不只有上一层,还有上上一层,直到最外层(不只见爸爸,还见爸爸的爸爸,…)。
3.7 兄弟节点
soup = BeautifulSoup(html, 'lxml')
#多节点时,默认是以第一个a节点为标准
print(list(enumerate(soup.a.next_siblings)),'\n') #后面的兄弟节点
print(list(enumerate(soup.a.previous_siblings))) #前面的兄弟节点

4. 标准选择器
仅使用标签选择器在很多场景下不能满足
4.1 find_all( name , attrs , recursive , text , **kwargs )
可根据标签名、属性、内容查找文档
以下面一段html为例:
html='''
Hello
- Foo
- Bar
- Jay
- Foo
- Bar
'''
4.1.2 name
查找标签名是ul的节点,输出包含2个元素的列表:
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all('ul')) #结果是列表,包含2个值
print('\n')
print(soup.find_all('ul')[0])
print(type(soup.find_all('ul')[0])) #列表第一个元素的类型

嵌套查找
针对ul节点,查找其下包含的名字为li的子节点:
soup = BeautifulSoup(html, 'lxml')
for ul in soup.find_all('ul'):
print(ul.find_all('li'),'\n')

4.1.3 attrs
查找具有特定属性attrs的节点 _1:
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(attrs={
'id': 'list-1'}),'\n') #字典形式传入属性
print(soup.find_all(attrs={
'name': 'elements'}))

查找具有特定属性attrs的节点 _2:
soup = BeautifulSoup(html, 'lxml')
'''特殊类型的id和class有特定的形式'''
print(soup.find_all(id='list-1'),'\n')
print(soup.find_all(class_='element'))
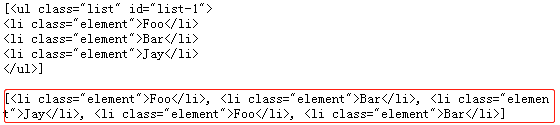 可以看到,只要属性明确,即使是内嵌直接胆,也可以直接选出来。
可以看到,只要属性明确,即使是内嵌直接胆,也可以直接选出来。
4.1.4 text
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text='Foo'))
输出:
[‘Foo’, ‘Foo’]
查找text,但是输出是只输出内容,在元素查找时不是很方便。
4.2 find( name , attrs , recursive , text , **kwargs )
find返回单个元素,find_all返回所有元素
返回结果就不是列表了,而是一个元素(默认第一个)
soup = BeautifulSoup(html, 'lxml')
print(soup.find('ul'),'\n')
#默认返回第一个ul
print(type(soup.find('ul')),'\n')
print(soup.find('page'))

4.2.1 find查找父节点/兄弟节点
find_parents() 返回所有祖先节点
find_parent() 返回直接父节点
find_next_siblings() 返回后面所有兄弟节点
find_next_sibling() 返回后面第一个兄弟节点
find_previous_siblings() 返回前面所有兄弟节点
find_previous_sibling() 返回前面第一个兄弟节点
find_all_next() 返回节点后所有符合条件的节点
find_next() 返回第一个符合条件的节点
find_all_previous() 返回节点后所有符合条件的节点
find_previous() 返回第一个符合条件的节点
5. CSS选择器
通过select( )直接传入CSS选择器即可完成选择。
还是刚才的一段html:
html='''
Hello
- Foo
- Bar
- Jay
- Foo
- Bar
'''
5.1 获取标签
使用CSS选择器时,有不同的符号表示。
选择class是用 .
选择id是用#
示例1:
soup = BeautifulSoup(html, 'lxml')
'''选择class是用. '''
print(soup.select('.panel .panel-heading'),'\n')
'''选择标签不需要加内容'''
print(soup.select('ul li')) #ul里面所有的li标签挑出来
'''选择id是用#'''
print('\n')
print(soup.select('#list-2 .element')) #层层迭代
#print(type(soup.select('ul')[0]))

示例2:
soup = BeautifulSoup(html, 'lxml')
for ul in soup.select('ul'): #通过循环输出,可以直接以上面的形式层层迭代输出内容
print(ul.select('li'),'\n')
print('循环迭代出每个li节点:','\n')
for ul in soup.select('ul'):
ul_n=ul
print('\n')
for li in ul_n.select('li'):
print(li)
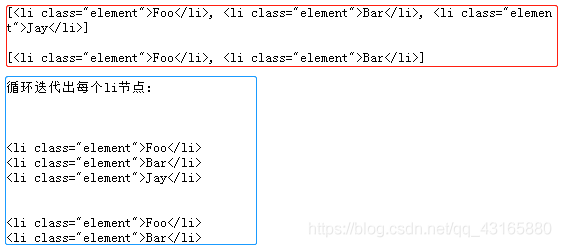
通过循环,可以逐一选出最小的节点。
5.2 获取属性
中括号[ ],或.attrs[ ]
soup = BeautifulSoup(html, 'lxml')
for ul in soup.select('ul'):
print(ul['id'])
print(ul.attrs['id'])
输出:
list-1
list-1
list-2
list-2
输出的是属性值。
5.3 获取内容
get_text( )
soup = BeautifulSoup(html, 'lxml')
for li in soup.select('li'):
print(li.get_text())
输出:
Foo
Bar
Jay
Foo
Bar
输出的是节点具体的内容(字符串)。
6. 其他
除了lxml解析库,还有html.parser(个人用的还不多…不太了解)
可使用find()、find_all() 查询匹配单个结果或者多个结果
需要记住常用的获取属性和文本值的方法