xavier初始化_AI初识:参数初始化深度学习成功的开始
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“”立刻申请入群~
作者:全能言有三
授权转载自公众号:有三AI
【导读】神经网络要优化一个非常复杂的非线性模型,而且基本没有全局最优解,初始化在其中扮演着非常重要的作用。尤其在没有BN等技术的早期,它直接影响模型能否收敛,没有好的初始化的深度学习模型训练起来会很难。
初始化的重要性
2006年Hinton等人在science期刊上发表了论文“Reducing the dimensionality of data with neural networks”,揭开了新的训练深层神经网络算法的序幕。
利用无监督的RBM网络来进行预训练,进行图像的降维,取得比PCA更好的结果,通常这被认为是深度学习兴起的开篇。

这么看来,是因为好的初始化方法的出现,才有了深层神经网络工程化落地的可能性。
好的初始化应该满足以下两个条件:
(1) 让神经元各层激活值不会出现饱和现象;
(2) 各层激活值也不能为0。
也就是激活值不要太大,也不要太小,应该刚刚好,当然这还只是最基本的要求。
我们都知道在早期,sigmoid激活函数是多层感知器模型的标配,上面这篇文章同样也是用sigmoid激活函数,没有那么多问题,是因为使用了预训练。
如果不使用预训练会如何?在Xavier Glorot和Yoshua Bengio提出xavier初始化方法的论文【1】中就对不同的激活函数使用不同的数据集做过实验。

上面是一个四层的神经网络在sigmoid函数激活下的训练过程,可以看到最深的layer4层刚开始的时候很快就进入了饱和区域(激活值很低),其他几层则比较平稳,在训练的后期才能进行正常的更新。
为什么会这样呢?网络中有两类参数需要学习,一个是权重,一个是偏置。对于上面的结果作者们提出了一个假设,就是在网络的学习过程中,偏置项总是学的更快,网络真正的输出就是直接由layer4决定的,输出就是softmax(b+Wh)。既然偏置项学的快,那Wh就没有这么重要了,所以激活值可以低一点。
解释虽然比较牵强,但是毕竟实验结果摆在那里,从tanh函数的激活值来看会更直观。

这个图有个特点是,0,1和-1的值都不少,而中间段的就比较少。在0值,逼近线性函数,它不能为网络的非线性能力作出贡献。对于1,-1,则是饱和区,没有用。
常用的初始化方法
1、全零初始化和随机初始化
如果神经元的权重被初始化为0, 在第一次更新的时候,除了输出之外,所有的中间层的节点的值都为零。一般神经网络拥有对称的结构,那么在进行第一次误差反向传播时,更新后的网络参数将会相同,在下一次更新时,相同的网络参数学习提取不到有用的特征,因此深度学习模型都不会使用0初始化所有参数。
而随机初始化就是搞一些很小的值进行初始化,实验表明大了就容易饱和,小的就激活不动,再说了这个没技术含量,不必再讨论。
2.标准初始化
对于均匀分布,X~U(a,b),概率密度函数等于:

它的期望等于0,方差等于(b-a)^2/12,如果b=1,a=-1,就是1/3。
下面我们首先计算一下,输出输入以及权重的方差关系公式:

如果我们希望每一层的激活值是稳定的,w就应该用n的平方根进行归一化,n为每个神经元的输入数量。
所以标准的初始化方法其权重参数就是以下分布:

它保证了参数均值为0,方差为常量1/3,和网络的层数无关。
3.Xavier初始化
首先有一个共识必须先提出:神经网络如果保持每层的信息流动是同一方差,那么会更加有利于优化。不然大家也不会去争先恐后地研究各种normalization方法。
不过,Xavier Glorot认为还不够,应该增强这个条件,好的初始化应该使得各层的激活值和梯度的方差在传播过程中保持一致,这个被称为Glorot条件。
如果反向传播每层梯度保持近似的方差,则信息能反馈到各层。而前向传播激活值方差近似相等,有利于平稳地学习。
当然为了做到这一点,对激活函数也必须作出一些约定。
(1) 激活函数是线性的,至少在0点附近,而且导数为1。
(2) 激活值关于0对称。
这两个都不适用于sigmoid函数和ReLU函数,而适合tanh函数。
要满足上面的两个条件,就是下面的式子。

推导可以参考前面标准初始化的方法,这里的ni,ni+1分别就是输入和输出的神经元个数了,因为输入输出不相等,作为一种权衡,文中就建议使用输入和输出的均值来代替。

再带入前面的均匀分布的方差(b-a)^2/12,就得到了对于tanh函数的xavier初始化方法。

下面这两个图分别是标准初始化和xavier初始化带来的各层的反传梯度方差,可以看出xavier确实保持了一致性。

4.He初始化
Xavier初始化虽然美妙,但它是针对tanh函数设计的,而激活函数现在是ReLU的天下,ReLU只有一半的激活,另一半是不激活的,所以前面的计算输入输出的方差的式子多了一个1/2,如下。

因为这一次没有使用均匀初始化,而是使用了正态分布,所以对下面这个式子:

需要的就是这样的正态分布。
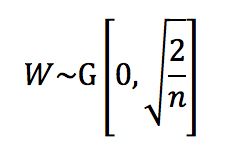
综上,对于两大最经典的激活函数,各自有了对应的初始化方法。虽然后面还提出了一些其他的初始化方法,但是在我们这个系列中就不再详述了。
关于初始化的一些思考
初始化这个问题明显比较麻烦,不然大家也不会这么喜欢用pretrained模型了。
从前面我们可以看到,大家努力的方向有这么几个。
(1) 预训练啊。
机智地一比,甩锅给别人,?。
(2) 从激活函数入手,让梯度流动起来不要进入饱和区,则什么初始化咱们都可以接受。
这其实就要回到上次我们说的激活函数了,ReLU系列的激活函数天生可以缓解这个问题,反过来,像何凯明等提出的方法,也是可以反哺激活函数ReLU。
(3) 归一化,让每一层的输入输出的分布比较一致,降低学习难度。
回想一下,这不就是BN干的活吗?所以才会有了BN之后,初始化方法不再需要小心翼翼地选择。假如不用BN,要解决这个问题有几个思路,我觉得分为两派。
首先是理论派,就是咱们从理论上分析出设计一个怎么样的函数是最合适的。
对于Sigmoid等函数,xavier设计出了xavier初始化方法,对于ReLU函数,何凯明设计了he初始化方法。
在此之上,有研究者分别针对零点平滑的激活函数和零点不平滑的激活函数提出了统一的框架,见文【2】,比如对于sigmoid,tanh等函数,方差和导数的关系如此。

然后是实践派,在训练的时候手动将权重归一化的,这就是向归一化方法靠拢。
[1] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[C]//Proceedings of the thirteenth international conference on artificial intelligence and statistics. 2010: 249-256.
[2] Kumar S K. On weight initialization in deep neural networks[J]. arXiv preprint arXiv:1704.08863, 2017.
[3] Mishkin D, Matas J. All you need is a good init[J]. arXiv preprint arXiv:1511.06422, 2015.
-完-
*延伸阅读
PyTorch 学习笔记(四):权值初始化的十种方法
不用批归一化也能训练万层ResNet,新型初始化方法Fixup了解一下
点击左下角“”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~ 