本人是一名典型的吃货,所以今天想研究一下大众点评网上海美食的数据。
一、数据爬虫
首先是爬虫部分,由于大众点评页面最多显示50页数据,所以要爬取到所有上海美食数据的话,要分行政区域,然后在每个区中再分美食的小类型,分别进行爬取,这样就可以获取到大部分数据了。
爬虫思路:
1、首先分析一下网址,http://www.dianping.com/search/category/1/10/g101r5 通过查看几个网址后可以发现,最后的g101和r5这两个编码,分别代表美食类型和行政区,所以先把美食编码和行政区编码爬取下来。
2、写两个for循环,把初始URL、美食编码和行政区编码拼接到一起。
3、拼接好后,对每一个拼接好的页面翻页,得到所有页面。
4、从所有页面中,获取详情页的URL。
5、对详情页解析,获取上海美食数据的详细信息。
Scrapy代码:
import scrapy
from dzdpscrapy.items import DzdpscrapyItem
import requests
from bs4 import BeautifulSoup
from lxml import etree
import time
import re
import random
hds=[{'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'},\
{'User-Agent':'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'},\
{'User-Agent':'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'},\
{'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0'},\
{'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36'},\
{'User-Agent':'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'},\
{'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'},\
{'User-Agent':'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0'},\
{'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'},\
{'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'},\
{'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'},\
{'User-Agent':'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11'},\
{'User-Agent':'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11'}]
class DianpingSpider(scrapy.Spider):
#拼接行政区和美食类型的所有URL
name = "dianping"
# location = ['r1','r2','r3','r4','r5','r6','r7','r8','r9','r10','r12', 'r13', 'r5937', 'r5938', 'r5939', 'r8846', 'r8847', 'c3580']
foodtype = ['g111', 'g114', 'g508', 'g109', 'g106', 'g104', 'g248','g219', 'g3243', 'g251', 'g26481', 'g203', 'g107', 'g105', 'g108', 'g215', 'g247', 'g1338', 'g1783','g101', 'g198', 'g25474', 'g199', 'g200', 'g201', 'g202', 'g113', 'g224', 'g226', 'g225', 'g25151', 'g132', 'g24645', 'g24646', 'g24648', 'g24650', 'g24647', 'g24649', 'g24652', 'g112', 'g210', 'g217', 'g221', 'g222', 'g1881', 'g213', 'g1819', 'g223', 'g216', 'g1821', 'g211', 'g212', 'g214', 'g220', 'g117', 'g244', 'g242', 'g241', 'g243', 'g110', 'g32733', 'g3027', 'g208', 'g4477', 'g116', 'g238', 'g24340', 'g232', 'g254', 'g231', 'g233', 'g253', 'g234', 'g103', 'g205', 'g207', 'g1947', 'g206', 'g102', 'g4467', 'g4469', 'g4473', 'g115', 'g227', 'g228', 'g230', 'g229', 'g118', 'g133', 'g134', 'g311', 'g26482', 'g250', 'g26483', 'g2774', 'g249', 'g246', 'g26484', 'g252']
location = ['r1', 'r835', 'r838', 'r836', 'r837', 'r2', 'r865', 'r870', 'r866', 'r872', 'r869', 'r868', 'r867', 'r871', 'r24031', 'r873', 'r3', 'r812', 'r811', 'r814', 'r813', 'r4', 'r842', 'r839', 'r840', 'r843', 'r841', 'r845', 'r844', 'r5', 'r801', 'r802', 'r804', 'r803', 'r806', 'r808', 'r5947', 'r809', 'r810', 'r2869', 'r5948', 'r807', 'r2867', 'r12029', 'r805', 'r22947', 'r2868', 'r8446', 'r9179', 'r24141', 'r24020', 'r22948', 'r8929', 'r24017', 'r24024', 'r70326', 'r24018', 'r70602', 'r67275', 'r70265', 'r70531', 'r6', 'r860', 'r861', 'r859', 'r863', 'r864', 'r862', 'r7', 'r815', 'r818', 'r9177', 'r816', 'r819', 'r2866', 'r817', 'r2865', 'r12038', 'r813', 'r8', 'r828', 'r827', 'r830', 'r829', 'r22949', 'r12026', 'r2864', 'r22950', 'r22951', 'r9', 'r821', 'r822', 'r824', 'r825', 'r823', 'r826', 'r820', 'r22946', 'r10', 'r854', 'r858', 'r855', 'r856', 'r857', 'r8445', 'r12', 'r846', 'r849', 'r848', 'r850', 'r2528', 'r847', 'r852', 'r853', 'r982', 'r8597', 'r8928', 'r851', 'r22952', 'r22953', 'r22957', 'r22955', 'r22956', 'r22958', 'r70507', 'r22954', 'r67276', 'r13', 'r834', 'r831', 'r8441', 'r8440', 'r8442', 'r2527', 'r833', 'r9170', 'r9171', 'r8443', 'r9169', 'r8444', 'r5937', 'r5941', 'r5943', 'r5940', 'r5942', 'r26146', 'r22979', 'r22986', 'r11374', 'r24019', 'r22983', 'r22987', 'r22981', 'r9178', 'r22980', 'r22982', 'r22985', 'r70277', 'r67354', 'r22984', 'r5938', 'r5946', 'r5962', 'r5944', 'r5945', 'r22988', 'r22991', 'r22989', 'r27830', 'r22990', 'r22992', 'r24022', 'r65166', 'r24021', 'r5939', 'r22993', 'r5949', 'r22995', 'r30340', 'r24023', 'r70209', 'r22994', 'r8846', 'r9172', 'r24025', 'r22961', 'r22964', 'r9173', 'r22959', 'r22960', 'r22965', 'r22963', 'r22962', 'r66320', 'r66319', 'r8847', 'r9174', 'r65207', 'r22974', 'r22970', 'r22971', 'r22969', 'r22967', 'r66226', 'r22968', 'r22966', 'r22975', 'r22972', 'r22973', 'c3580', 'r64598', 'r64606', 'r64609', 'r64599', 'r64614', 'r64602', 'r64601', 'r64607', 'r64605', 'r64604', 'r64612', 'r64611', 'r64603', 'r64600', 'r64597', 'r64608', 'r8848']
def start_requests(self):
for lbs in self.location:
for ft in self.foodtype:
url = 'http://www.dianping.com/search/category/1/10/%s%s' % (lbs, ft)
yield scrapy.Request(url=url,callback=self.next_page)
def next_page(self,response):
#翻页,得到所有页面
url = str(response.url)
pages = response.xpath('//*[@id="top"]/div[6]/div[3]/div[1]/div[2]/a/text()').extract()[-2]
if pages:
for i in range(1,int(pages)):
urls = url + 'p' + str(i)
yield scrapy.Request(url = urls ,callback=self.parse_url)
else:
yield scrapy.Request(url = url ,callback=self.parse_url)
def parse_url(self, response):
#获取详情页URL
req = requests.get(response.url).text
soup = BeautifulSoup(req,'lxml')
hrefs = soup.select('#shop-all-list > ul > li > div.txt > div.tit > a[data-hippo-type="shop"]')
for i in hrefs:
base_url = 'http://www.dianping.com'
shop_url = base_url + str(i['href'])
yield scrapy.Request(url=shop_url, callback=self.parse_detail)
def parse_detail(self,response):
#解析详情页
item = DzdpscrapyItem()
req = requests.get(url = response.url,headers=hds[random.randint(0,len(hds)-1)]).text
selector = etree.HTML(req)
item['name'] = selector.xpath('//*[@id="basic-info"]/h1/text()')[0].strip() #店名
item['address'] = selector.xpath('//*[@id="basic-info"]/div[2]/span[2]/text()')[0].strip() #地址
item['comment'] = selector.xpath('//*[@id="reviewCount"]/text()')[0] if selector.xpath('//*[@id="reviewCount"]') else None #评论数
item['score'] = selector.xpath('//*[@id="basic-info"]/div[1]/span/@title')[0] if selector.xpath('//*[@id="basic-info"]/div[1]/span/@title') else None #星级
item['price'] = selector.xpath('//*[@id="avgPriceTitle"]/text()')[0][3:] if selector.xpath('//*[@id="avgPriceTitle"]') else None #价格
item['flavor'] = selector.xpath('//*[@id="comment_score"]/span[1]/text()')[0][3:] if selector.xpath('//*[@id="comment_score"]/span[1]') else None #口味
item['environment'] = selector.xpath('//*[@id="comment_score"]/span[2]/text()')[0][3:] if selector.xpath('//*[@id="comment_score"]/span[2]') else None #环境
item['service'] = selector.xpath('//*[@id="comment_score"]/span[3]/text()')[0][3:] if selector.xpath('//*[@id="comment_score"]/span[3]') else None #服务
item['tel'] = selector.xpath('//*[@id="basic-info"]/p/span[2]/text()')[0].strip() if selector.xpath('//*[@id="basic-info"]/p/span[2]')else None #电话
item['time'] = selector.xpath('//*[@id="basic-info"]/div[4]/p[1]/span[2]/text()')[0].strip() if selector.xpath('//*[@id="basic-info"]/div[4]/p[1]/span[2]') else None #营业时间
item['category1'] = selector.xpath('//*[@id="body"]/div[2]/div[1]/a[2]/text()')[0].strip() if selector.xpath('//*[@id="body"]/div[2]/div[1]/a[2]') else None #分类1
item['category2'] = selector.xpath('//*[@id="body"]/div[2]/div[1]/a[3]/text()')[0].strip() if selector.xpath('//*[@id="body"]/div[2]/div[1]/a[3]') else None #分类2
item['category3'] = selector.xpath('//*[@id="body"]/div[2]/div[1]/a[4]/text()')[0].strip() if selector.xpath('//*[@id="body"]/div[2]/div[1]/a[4]') else None #分类3
pattern = re.compile('shopGlat.*?"(.*?)",.*?shopGlng.*?"(.*?)",.*?cityGlat', re.S)
pois = re.findall(pattern, response.text)
item['poi'] = (pois[0][0]+','+pois[0][1]) #坐标
yield item
二、数据清洗
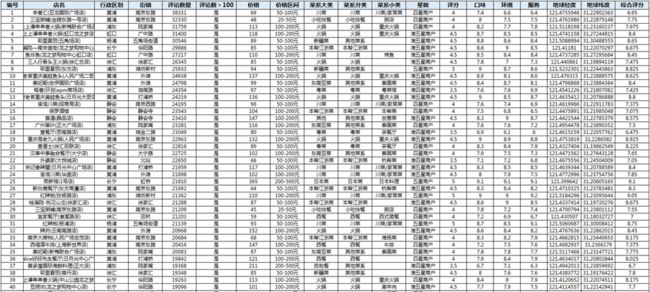
1、对所有记录编号,方便做数据统计。
2、新增字段【是否连锁店】,店名去除分店的名称(去除括号内的名称),然后对去除分店后的店名进行计数统计,大于1的店名即为连锁店。
3、通过QGIS软件匹配出个公司所在的行政区和街镇(区域)。�
4、新增字段【评论数>100】,后面有些分析评论数筛选大于100的,评论数太少的评分和价格可能与实际不符。
5、新增字段【价格区间】,对价格进行。
6、新增字段【菜系分类】,面包甜点、咖啡厅等归为非正餐,新疆菜、西北菜等店数较少的菜系归类为其他菜系。
7、新增字段【评分】,星级转换为分数,五星商户转为5分,准五星商户转换为4.5分,以此类推。
8、新增字段【综合评分】,根据口味、环境、服务得出综合评分,综合评分 = 口味*0.5 + 环境 * 0.25 + 服务 * 0.25�
9、坐标转换,大众点评网使用的是火星坐标系,所以要转换为WGS84地球坐标系,方便在QGIS中做分析,这里用到的是别人写好的python代码,可以在各坐标系之间进行转换,地址https://github.com/wandergis/coordTransform_py。�
10、对异常数据进行清洗,数据格式统一。
11、大众点评的行政区还是按照原先的划分,这里我按照最新的标准,闸北和静安合并为静安,黄浦和卢湾合并为黄浦。�清洗之后,大概长这样:
三、数据分析及可视化
1、区域
①上海各区店数和密度
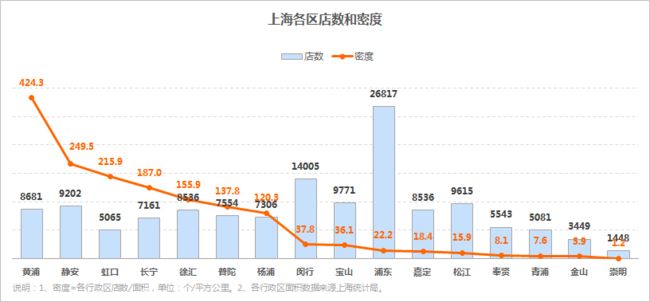
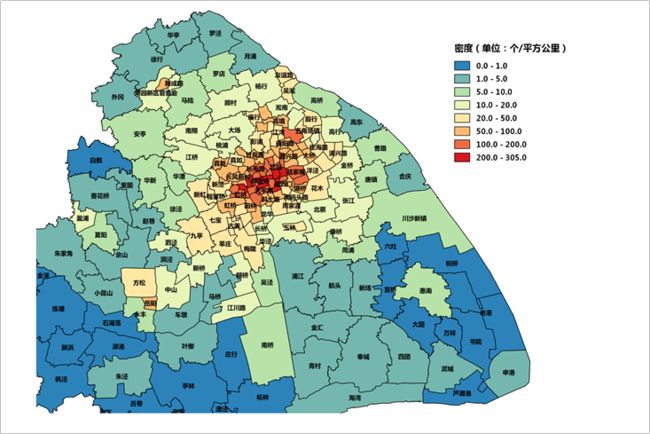
上海各行政区中,商户密度最高的黄浦区,前7名均为市区,后9名均为郊区,商户数最多的是浦东。
②上海各街镇商户密度
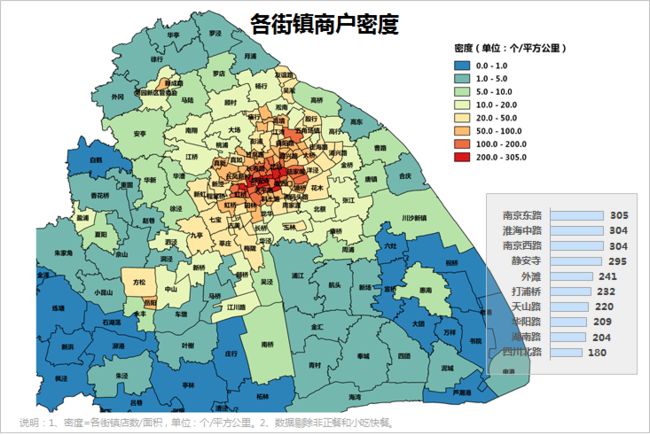
上海各街镇的商户密度分布中,商户数最多的是南京东路、淮海中路、南京西路等上海最繁华的商业区。
2、价格
①上海各区商户的平均价格
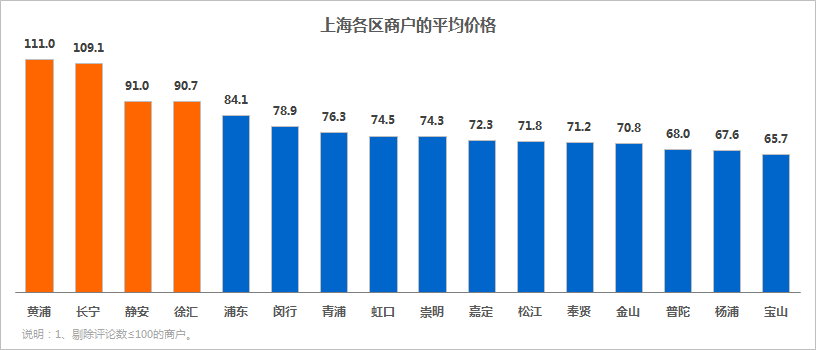
上海各区商户平均价格最高的是黄浦区、长宁区、静安区和徐汇区。
②上海商户各星级商户占比
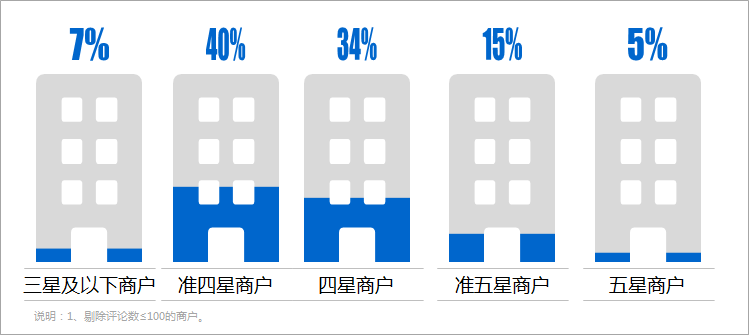
③各价格区间商户数分布
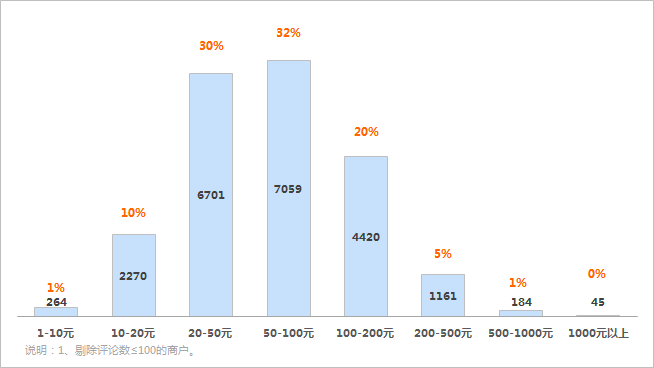
上海的商户价格,主要集中在20-50元和50-100元,占比均为30%和32%。
④价格区间与商户星级关系
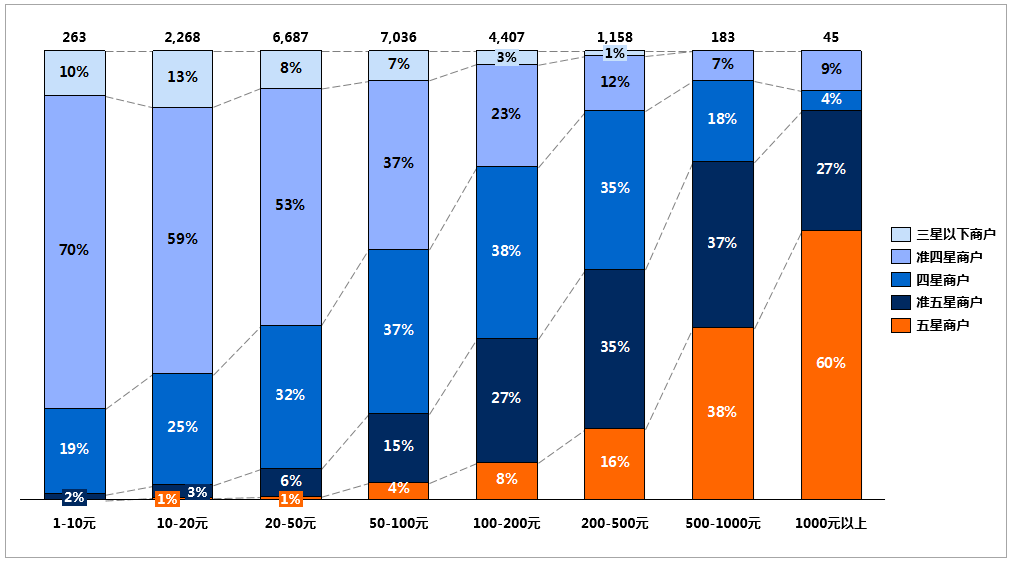
整体来看,价格越高,商户星级越高,果然还是越贵的东西越好吃,作为一名吃货,最大的梦想就是随时随地想吃什么就吃什么,所以要抓紧挣钱了。
⑤上海价格TOP20商户
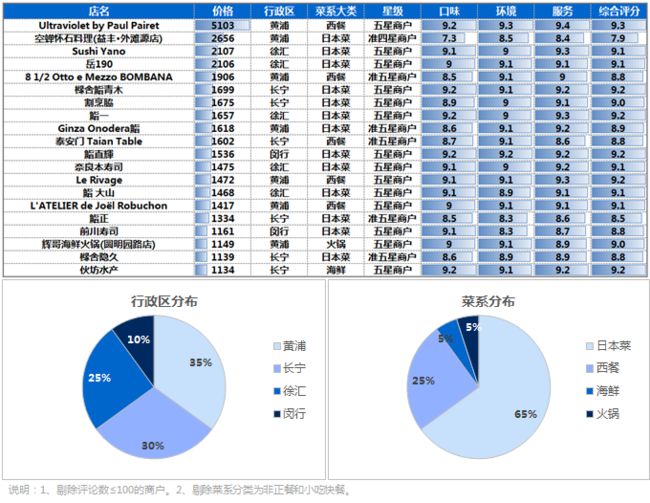
接下来我们就看看人均价格最高的商户都是哪些,作为屌丝的我,听都没听过这些店,这些店主要分布在黄浦、长宁、徐汇、闵行,居然没有被网友称为宇宙中心的大静安,菜系主要以日本菜和西餐为主,火锅和海鲜各一个。
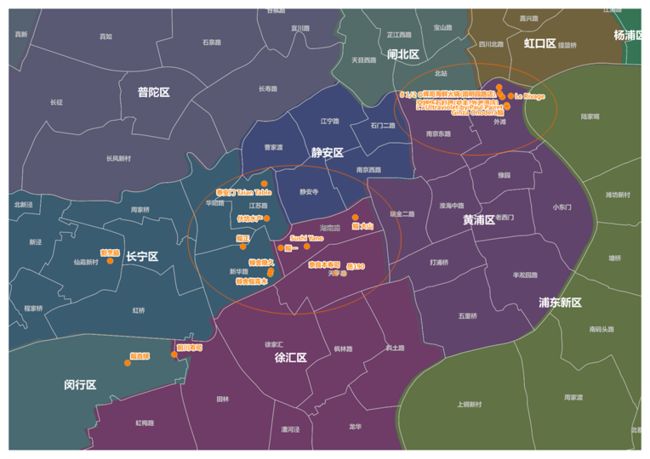
再看一下这些店的具体坐标,用QGIS画出坐标图,果然是没有大静安,而这些店主要集中在外滩和新华路、湖南路等区域。
3、菜系
①菜系分布
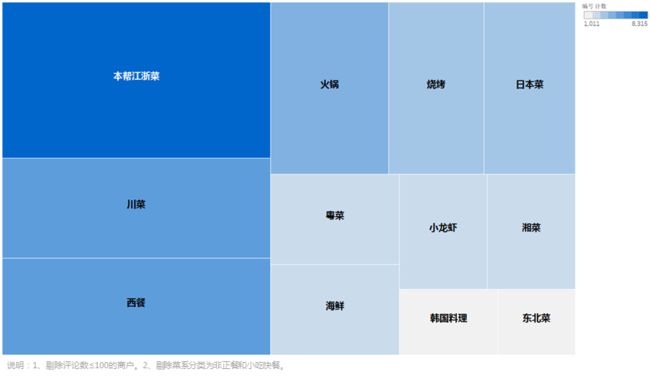
虽然上海是个包容的国际大都市,外地人很多,口味方面各有所爱,各种菜系应有尽有,但是菜系占比最高的还是江浙沪这边的本地菜——本帮江浙菜,第二名是我的最爱——川菜,由于本人酷爱吃辣,所以川菜和湘菜是我最喜欢吃的菜系,看来跟我口味一样重的人还是挺多的。西餐排在第三有点意外,看了一下数据源,很多披萨、汉堡等应该归到小吃快餐的小店也归到西餐了,所以比较多。
②各菜系平均价格(剔除评论数<100)
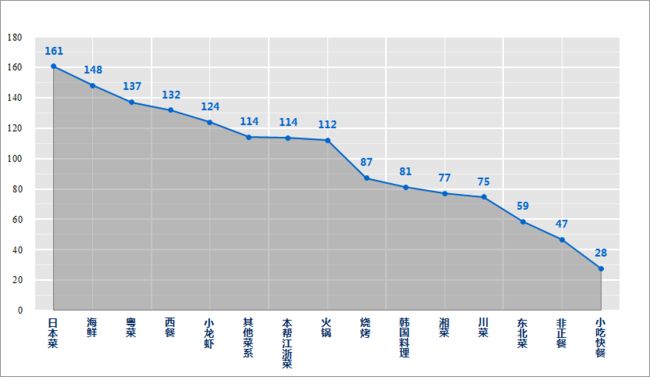
各菜系的平均价格前三位的是日本菜、海鲜、粤菜,正餐中价格最低的是东北菜,小吃快餐人均28元。
③菜系与商户星级关系
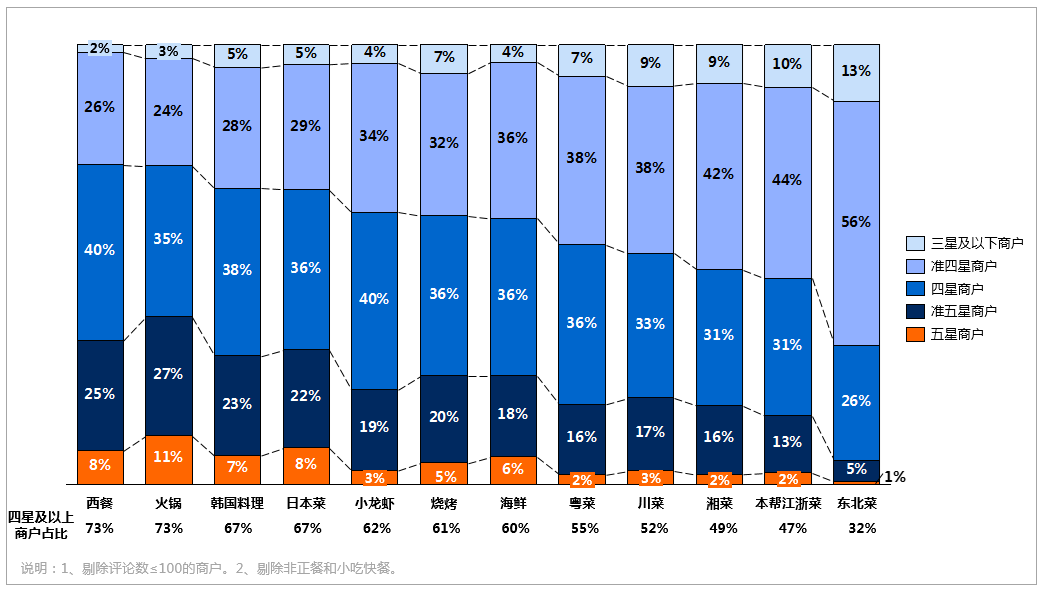
以本人多年使用大众点评的经验,四星以上的商户大部分还是比较不错的,所以来看一下各菜系四星以上商户的占比排名,占比最高的是西餐73%,其次是火锅和韩国料理,东北菜和本帮江浙菜占比最低,所以在吃这两个菜系的时候要谨慎选择。
④各菜系的价格与综合评分的关系

整体来看,平均单价越高的菜系评分越高,但是有一些菜系跟整体趋势有一定差别,韩国料理、烧烤、火锅在上置信区间线之上,性价比相对较高,而东北菜、本帮江浙菜和粤菜在下置信区间线之下,性价比相对较低。