PYTHON学习笔记之(一)2020.08
PYTHON学习笔记之(一)2020.08
Python基础
数据类型
常见的列表、字典,以及元组、集合。
1 列表 list
- 1.1 列表转换字符串
stu = ['王一', '李二', '张三']
print(stu)
nStu = ' - '.join(stu)
print(nStu)
[‘王一’, ‘李二’, ‘张三’]
王一 - 李二 - 张三
- 1.2 字符串转列表
strT = 'a good day'
lst = strT.split(' ')
print(lst)
[‘a’, ‘good’, ‘day’]
2 字典 dictionary
-2.1 字典录入与输出
dicA = {
'a': 'a', 'b': ' good', 'c': ' day'}
print(dicA['a'] + dicA['b'] + dicA['c'])
a good day
dicA = {
'a': 'a', 'b': 'good', 'c': 'day'}
for i in dicA:
print(i + ': ' + dicA[i])
a: a
b: good
c: day
3 元组 tuple
3.1 元组 元组数据不可以修改
tupA = ('a', 'b', 'c', 'd')
print(tupA[1:3])
(‘b’, ‘c’)
4 集合 set
4.1 集合 集合会自动去重复
setA = {
'a', 'b', 'b'}
print(setA)
{‘a’, ‘b’}
运算符
运算符 + - * / > < >= <= == and or not,不一一举例
分支循环
1.if … else …
if 表达式:
code
else:
code
2.for i in 循环变量:
code
3.while 表达式:
code
异常处理
try:
code
except:
code
函数
def funName(参数):
code
常见内部函数:
str、int、len、replace、strip、 split
库的引用
import 库名
from 库名 import 功能/*
有时候引用的库没有需要安装,以下方式:
1.pip install 库名(前提条件安装了pip工具)
cmd 中 pip install requests
2.pycharm安装
File -> Settings
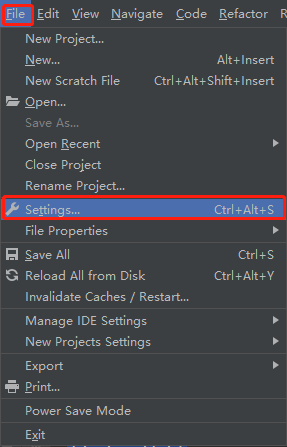
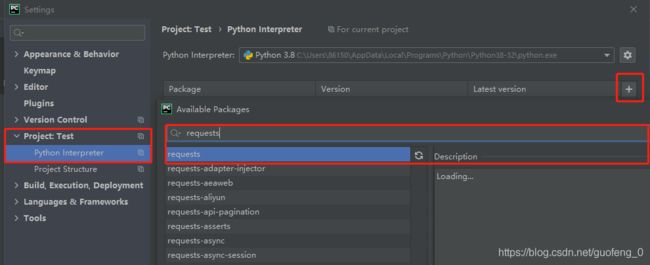
然后点击安装install package即可。
试试爬一个网页
import requests
res = requests.get('https://www.baidu.com').text
print(res)
爬虫基础
网页结构
1 查看网页源代码
F12键
主要使用选择以及元素选项

右键菜单
查看网页源代码
有时通过F12可以看到的内容,而通过右键菜单是看不到的,因为有些网页是通过动态渲染出来的。
F12看到的代码是经过渲染的。
2 网页结构
html
body
h:h1、h2、h3标题
p:段落
a:链接
table:表格
li:序号
img:图片
div:区块
class与id
获取网页源代码
import requests
res = requests.get('https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=02003390_21_hao_pg&wd=疫情').text
print(res)
不可行,需要模拟浏览器发送访问请求。
可以通过requests.get()中的headers参数,模拟浏览器访问请求。
headers提供网站访问者的信息,User-Agent表示用户代理,是通过什么浏览器访问。
headers可以通过在浏览器中输入about:version查看,这里用的谷歌浏览器

修改后的代码如下
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/65.0.3325.181 Safari/537.36'}
res = requests.get('https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=02003390_21_hao_pg&wd=疫情', headers=headers).text
print(res)
执行后便可以获取源代码信息。
分析网页源代码
1 F12键
开发者工具中“选择”选项,选择一个元素,可以在Elements中看到该标题的内容。
2 利用右键菜单
查看网页源代码
3 利用Python输出框
在获取到的源代码中查询
正则表达式
1 正则表达式findall()函数
import re
content = 'hello 123 world'
result = re.findall('\d', content)
print(result)
[‘1’, ‘2’, ‘3’]
正则表达式常用功能
| 符号 | 功能 |
|---|---|
| \d | 一个数字 |
| \w | 一个字母、数字、下划线 |
| \s | 一个空白符、换行符、制表符、空格 |
| \S | 匹配一个非空白符 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| . | 匹配一个任意字符,除换行符 |
| * | 匹配0个或多个表达式 |
| + | 匹配一个或多个表达式 |
| ? | 非贪婪限定符,常与.和*配合使用 |
| () | 匹配括号内的表达式,也表示一个组 |
2 正则表达式非贪婪匹配
2.1 (.?)
其格式如下:
文本A(.?)文本B
文本A百度新闻文本B
import re
content = '文本A百度新闻文本B'
reg = '文本A(.*?)文本B'
result = re.findall(reg, content)
print(result)
[‘百度新闻’]
2.2 匹配.?
reg = '
.?用于填充我们不关心的内容,其中是一些变化的不固定的内容,一直匹配到下一个“>”,并取得(.*?)这部分内容。
2.3考虑换行的修饰符re.S
re.findall(规则, 文本, re.S)
import re
content = '''
文本A百
度新
闻文本B
'''
reg = '文本A(.*?)文本B'
result = re.findall(reg, content, re.S)
print(result)
[‘百\n度新\n闻’]
2.4 re.sub函数
re.sub(’<.*?>’,’’, 待替换的字符串)
2.5 中括号[]用法
为了使. * + ?不再有特殊含义
re.sub(’[*]’, ‘’ ,待替换字符串)
数据提取小CASE
1.获取网页信息
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/65.0.3325.181 Safari/537.36'}
url = 'https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=阿里巴巴'
res = requests.get(url, headers=headers).text
print(res)
2.提取新闻来源和日期
使用F12查看新闻来源标签

使用如下正则表达式
reg = 'reg = '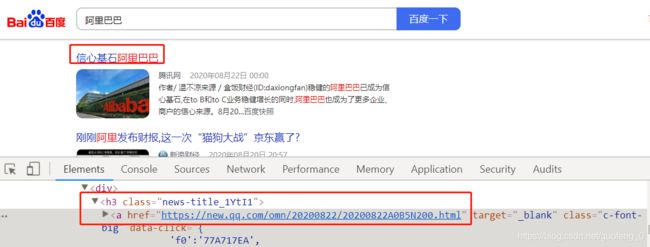
regTitle = '=
re.findall(regTitle, res, re.S)
[‘张勇彭蕾退出蚂蚁集团董事,新增包括阿里巴巴CTO等五名董事’, ‘阿里巴巴发布新财报,年度活跃用户量达7.42亿’, ‘阿里巴巴北京总部,公司太霸气了,带你先睹为快!’, ‘阿里云公布一季度财报 连续四季度强劲增长’, ‘阿里巴巴:长期主义的阶段胜利’, ‘信心基石阿里巴巴’, ‘阿里巴巴发布新一季财报,淘宝直播成交额翻倍增长’, ‘阿里巴巴:停止UCWeb及其他创新业务在印度服务’, ‘鹤壁阿里巴巴托管公司’, ‘刚刚阿里发布财报,这一次“猫狗大战”京东赢了?’]
regLink = '
articleLink = re.findall(regLink, res, re.S)
[‘https://baijiahao.baidu.com/s?id=1675786144786316914&wfr=spider&for=pc’, ‘https://www.lukeji.com.cn/news/xls/21606.html’, ‘https://3g.163.com/news/article/FKLRM0640515D607.html’, ‘https://new.qq.com/omn/20200822/20200822A026GS00.html’, ‘http://dy.163.com/v2/article/detail/FKLD2R1H05199O51.html’, ‘https://new.qq.com/omn/20200822/20200822A0B5N200.html’, ‘http://tech.sina.com.cn/roll/2020-08-22/doc-iivhuipp0077223.shtml’, ‘http://www.scjjrb.com/syxw/e105511285.html’, ‘http://finance.eastmoney.com/a/202008221604220943.html’, ‘https://baijiahao.baidu.com/s?id=1675602491601591953&wfr=spider&for=pc’]
4 数据处理
有些特殊等字符不需要
去掉标题中的em标签
for i in range(len(articleTitle)):
articleTitle[i] = re.sub('<.*?>', '', articleTitle[i])
print(articleTitle)
[‘张勇彭蕾退出蚂蚁集团董事,新增包括阿里巴巴CTO等五名董事’, ‘阿里巴巴发布新财报,年度活跃用户量达7.42亿’, ‘阿里巴巴北京总部,公司太霸气了,带你先睹为快!’, ‘阿里云公布一季度财报 连续四季度强劲增长’, ‘阿里巴巴:长期主义的阶段胜利’, ‘信心基石阿里巴巴’, ‘阿里巴巴:停止UCWeb及其他创新业务在印度服务’, ‘鹤壁阿里巴巴托管公司’, ‘BAT最新成绩单PK:阿里巴巴营收增速最快 百度掉队’, ‘阿里巴巴发布2021财年第一财季财报’]
这样数据准备OK
5 将它们拼接在一起
import requests
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/65.0.3325.181 Safari/537.36'}
url = 'https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=阿里巴巴'
res = requests.get(url, headers=headers).text
regP = '= re.findall(regP, res, re.S)
regT = '= re.findall(regT, res, re.S)
regTitle = '=
re.findall(regTitle, res, re.S)
regLink = '
articleLink = re.findall(regLink, res, re.S)
for i in range(len(articleTitle)):
articleTitle[i] = re.sub('<.*?>', '', articleTitle[i])
print(str(i+1) + ' ' + articleTitle[i] + '\t' + publisher[i] + '\t' + issueTime[i] + '\n'
+ articleLink[i])
1 张勇彭蕾退出蚂蚁集团董事,新增包括阿里巴巴CTO等五名董事 AI财经社 2小时前
https://baijiahao.baidu.com/s?id=1675786144786316914&wfr=spider&for=pc
2 阿里巴巴发布新财报,年度活跃用户量达7.42亿 鹿科技 2020年08月22日 14:49
https://www.lukeji.com.cn/news/xls/21606.html
3 阿里巴巴北京总部,公司太霸气了,带你先睹为快! 网易新闻 2020年08月22日 21:56
https://3g.163.com/news/article/FKLRM0640515D607.html
4 阿里云公布一季度财报 连续四季度强劲增长 腾讯网 2020年08月22日 00:00
https://new.qq.com/omn/20200822/20200822A026GS00.html
5 阿里巴巴:长期主义的阶段胜利 网易新闻 2020年08月22日 17:41
http://dy.163.com/v2/article/detail/FKLD2R1H05199O51.html
6 信心基石阿里巴巴 腾讯网 2020年08月22日 00:00
https://new.qq.com/omn/20200822/20200822A0B5N200.html
7 阿里巴巴:停止UCWeb及其他创新业务在印度服务 新浪科技 2020年08月22日 15:35
http://tech.sina.com.cn/roll/2020-08-22/doc-iivhuipp0077223.shtml
8 鹤壁阿里巴巴托管公司 四川经济网 2020年08月22日 16:06
http://www.scjjrb.com/syxw/e105511285.html
9 BAT最新成绩单PK:阿里巴巴营收增速最快 百度掉队 东方财富网 2020年08月22日 23:05
http://finance.eastmoney.com/a/202008221604220943.html
10 阿里巴巴发布2021财年第一财季财报 亿欧网 2020年08月21日 11:03
https://baijiahao.baidu.com/s?id=1675602491601591953&wfr=spider&for=pc
6 不间断爬取数据
while True:无限循环
time.sleep(3600):每小时一次 需要引入import time包
7 爬取多页数据
手动选择下一页按钮会发现网站后面拼接“&pn=10”
这部分可以写的循环里面即可。
8 设置超时设置 timeout
res = requests.get(url, headers=headers, timeout=10).text #其中10是10秒。
如果超过10秒就会异常
可以用try except进行异常处理
数据库的使用
Python支持数据库
传统数据库
IBM DB2
Firebird (and Interbase)
Informix
Ingres
MySQL
Oracle
PostgreSQL
SAP DB (also known as “MaxDB”)
Microsoft SQL Server
Microsoft Access
Sybase
数据仓库
Teradata
IBM Netezza
其他数据库
…
可以参考
Python数据库接口及API
这里先介绍mysql数据库。
数据库安装
这里安装WampServer,是Apache Web服务器、PHP解释器及MySQL数据库的软件包整合
我用的是联想自带的电脑管家,上图
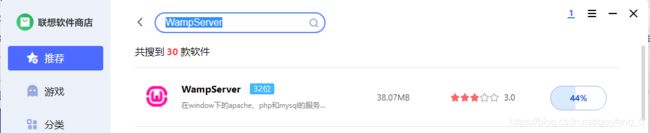
数据库基础
mysql数据库基础
菜鸟教程
简介
MySQL是最流行的关系型数据库管理系统,在WEB 应用方面 MySQL是最好的RDBMS应用软件之一。
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL 是开源的,所以你不需要支付额外的费用。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
- MySQL 对PHP有很好的支持,PHP 是目前最流行的 Web 开发语言。
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。
- MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系统。
数据库管理
- USE 数据库名 :选择要操作的Mysql数据库,使用该命令后所有Mysql命令都只针对该数据库。
- SHOW DATABASES: 列出 MySQL 数据库管理系统的数据库列表。
- SHOW TABLES:显示指定数据库的所有表,使用该命令前需要使用 use 命令来选择要操作的数据库。
- SHOW COLUMNS FROM 数据表:显示数据表的属性,属性类型,主键信息 ,是否为 NULL,默认值等其他信息。
- SHOW INDEX FROM 数据表:显示数据表的详细索引信息,包括PRIMARY KEY(主键)。
- SHOW TABLE STATUS LIKE [FROM db_name] [LIKE ‘pattern’] \G: 该命令将输出Mysql数据库管理系统的性能及统计信息。
- mysql -u root -p:命令行中连接mysql服务器
- 使用 exit 命令
- CREATE DATABASE 数据库名;使用 create 命令创建数据库
- drop 命令删除数据库 drop database <数据库名>;
- 选择数据库 USE 数据库名
类型
大小
范围(有符号)
范围(无符号)
用途
TINYINT
1 byte
(-128,127)
(0,255)
小整数值
SMALLINT
2 bytes
(-32 768,32 767)
(0,65 535)
大整数值
MEDIUMINT
3 bytes
(-8 388 608,8 388 607)
(0,16 777 215)
大整数值
INT或INTEGER
4 bytes
(-2 147 483 648,2 147 483 647)
(0,4 294 967 295)
大整数值
BIGINT
8 bytes
(-9,223,372,036,854,775,808,9 223 372 036 854 775 807)
(0,18 446 744 073 709 551 615)
极大整数值
FLOAT
4 bytes
(-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38)
0,(1.175 494 351 E-38,3.402 823 466 E+38)
单精度浮点数值
DOUBLE
8 bytes
(-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308)
0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308)
双精度浮点数值
DECIMAL
对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2
依赖于M和D的值
依赖于M和D的值
小数值
DATE
3
1000-01-01/9999-12-31
YYYY-MM-DD
日期值
TIME
3
‘-838:59:59’/‘838:59:59’
HH:MM:SS
时间值或持续时间
YEAR
1
1901/2155
YYYY
年份值
DATETIME
8
1000-01-01 00:00:00/9999-12-31 23:59:59
YYYY-MM-DD HH:MM:SS
混合日期和时间值
TIMESTAMP
4
1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07
YYYYMMDD HHMMSS
混合日期和时间值,时间戳
CHAR
0-255 bytes
定长字符串
VARCHAR
0-65535 bytes
变长字符串
TINYBLOB
0-255 bytes
不超过 255 个字符的二进制字符串
TINYTEXT
0-255 bytes
短文本字符串
BLOB
0-65 535 bytes
二进制形式的长文本数据
TEXT
0-65 535 bytes
长文本数据
MEDIUMBLOB
0-16 777 215 bytes
二进制形式的中等长度文本数据
MEDIUMTEXT
0-16 777 215 bytes
中等长度文本数据
LONGBLOB
0-4 294 967 295 bytes
二进制形式的极大文本数据
LONGTEXT
0-4 294 967 295 bytes
极大文本数据
创建数据表
CREATE TABLE IF NOT EXISTS `runoob_tbl`(
`runoob_id` INT UNSIGNED AUTO_INCREMENT,
`runoob_title` VARCHAR(100) NOT NULL,
`runoob_author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRIMARY KEY ( `runoob_id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
- ENGINE 设置存储引擎,CHARSET 设置编码。
删除数据表
DROP TABLE table_name ;
插入数据表
INSERT INTO table_name ( field1, field2,...fieldN )VALUES( value1, value2,...valueN );
查询数据表
SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[LIMIT N][ OFFSET M]
- 查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。
- SELECT 命令可以读取一条或者多条记录。
- 你可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据
- 你可以使用 WHERE 语句来包含任何条件。
- 你可以使用 LIMIT 属性来设定返回的记录数。
- 你可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
正则表达式
MySQL可以通过 LIKE …% 来进行模糊匹配。
SELECT name FROM person_tbl WHERE name REGEXP '^st';
SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';
显示创建表语句
使用 SHOW CREATE TABLE 命令获取创建数据表(CREATE TABLE) 语句,该语句包含了原数据表的结构,索引等。
SHOW CREATE TABLE TABLE_NAME
临时表
MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。
CREATE TEMPORARY TABLE SalesSummary
导出数据
MySQL中你可以使用SELECT…INTO OUTFILE语句来简单的导出数据到文本文件上。
SELECT * FROM runoob_tbl INTO OUTFILE '/tmp/runoob.txt';
SELECT * FROM passwd INTO OUTFILE '/tmp/runoob.txt' FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\r\n';
SELECT a,b,a+b INTO OUTFILE '/tmp/result.text'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM test_table;
Python与数据库交互
创建数据库链接
import pymysql
db = pymysql.connect('localhost', 'root', '123456', 'test', charset='utf8')
cur = db.cursor()
cur.execute('SELECT * FROM TEST1')
data = cur.fetchall()
for i in data:
print(i)
#创建数据库连接
pymysql.Connect()参数说明
host(str): MySQL服务器地址
port(int): MySQL服务器端口号
user(str): 用户名
passwd(str): 密码
db(str): 数据库名称
charset(str): 连接编码,存在中文的时候,连接需要添加charset=‘utf8’,否则中文显示乱码。
connection对象支持的方法
cursor() 使用该连接创建并返回游标
commit() 提交当前事务,不然无法保存新建或者修改的数据
rollback() 回滚当前事务
close() 关闭连接
cursor对象支持的方法
execute(op) 执行SQL,并返回受影响行数
fetchone() 取得结果集的下一行
fetchmany(size) 获取结果集的下几行
fetchall() 获取结果集中的所有行
rowcount() 返回数据条数或影响行数
close() 关闭游标对象
Python从数据库中查询数据
import pymysql
db = pymysql.connect('localhost', 'root', '123456', 'test', charset='utf8')
cur = db.cursor()
sql = 'SELECT ID, NAME FROM TEST1'
cur.execute(sql)
dataS = cur.fetchall()
for row in dataS:
ID = row[0]
NAME = row[1]
print("ID: %s NAME: %s" % (ID, NAME))
ID: 1 NAME: wangyi
ID: 2 NAME: liuer
ID: 3 NAME: zhangsan
爬虫数据存入数据库
将之前爬取的新闻数据存储至MYSQL数据库中。中文报错。
import requests
import re
import pymysql
db = pymysql.connect('localhost', 'root', '123456', 'test', charset='utf8')
cur = db.cursor()
sqlC = 'CREATE TABLE NEWS(ID INT, TITLE VARCHAR(100), NEWS_FROM VARCHAR(100), NEWS_TIME VARCHAR(100), URL VARCHAR(' \
'200)) '
cur.execute(sqlC)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/65.0.3325.181 Safari/537.36'}
keyW = '京东'
url = 'https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=' + keyW
res = requests.get(url, headers=headers).text
regP = '= re.findall(regP, res, re.S)
regT = '= re.findall(regT, res, re.S)
regTitle = '=
re.findall(regTitle, res, re.S)
regLink = '
articleLink = re.findall(regLink, res, re.S)
for i in range(len(articleTitle)):
articleTitle[i] = re.sub('<.*?>', '', articleTitle[i])
sqlI = "INSERT INTO NEWS VALUES('%s','%s','%s','%s','%s')" % (str(i + 1), str(i + 1), str(i + 1), str(i + 1), articleLink[i])
print(sqlI)
cur.execute(sqlI)
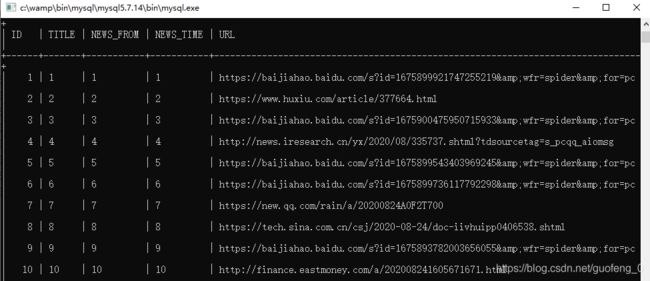
INSERT INTO NEWS VALUES(‘1’,‘1’,‘1’,‘1’,‘https://baijiahao.baidu.com/s?id=1675899921747255219&wfr=spider&for=pc’)
INSERT INTO NEWS VALUES(‘2’,‘2’,‘2’,‘2’,‘https://www.huxiu.com/article/377664.html’)
INSERT INTO NEWS VALUES(‘3’,‘3’,‘3’,‘3’,‘https://baijiahao.baidu.com/s?id=1675900475950715933&wfr=spider&for=pc’)
INSERT INTO NEWS VALUES(‘4’,‘4’,‘4’,‘4’,‘http://news.iresearch.cn/yx/2020/08/335737.shtml?tdsourcetag=s_pcqq_aiomsg’)
INSERT INTO NEWS VALUES(‘5’,‘5’,‘5’,‘5’,‘https://baijiahao.baidu.com/s?id=1675899543403969245&wfr=spider&for=pc’)
INSERT INTO NEWS VALUES(‘6’,‘6’,‘6’,‘6’,‘https://baijiahao.baidu.com/s?id=1675899736117792298&wfr=spider&for=pc’)
INSERT INTO NEWS VALUES(‘7’,‘7’,‘7’,‘7’,‘https://new.qq.com/rain/a/20200824A0F2T700’)
INSERT INTO NEWS VALUES(‘8’,‘8’,‘8’,‘8’,‘https://tech.sina.com.cn/csj/2020-08-24/doc-iivhuipp0406538.shtml’)
INSERT INTO NEWS VALUES(‘9’,‘9’,‘9’,‘9’,‘https://baijiahao.baidu.com/s?id=1675893782003656055&wfr=spider&for=pc’)
INSERT INTO NEWS VALUES(‘10’,‘10’,‘10’,‘10’,‘http://finance.eastmoney.com/a/202008241605671671.html’)
数据清洗
关于中文乱码
decode()和encode()函数。
数据分析NumPy与pandas
NumPy库
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用, 这种组合广泛用于替代 MatLab,是一个强大的科学计算环境,有助于我们通过 Python 学习数据科学或者机器学习。
SciPy 是一个开源的 Python 算法库和数学工具包。
SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。
Matplotlib 是 Python 编程语言及其数值数学扩展包 NumPy 的可视化操作界面。它为利用通用的图形用户界面工具包,如 Tkinter, wxPython, Qt 或 GTK+ 向应用程序嵌入式绘图提供了应用程序接口(API)。
Numpy
Numpy源代码
Scipy
Scipy源代码
Matplotlib
Matplotlib源代码
数据可视化
数据挖掘
解析PDF
解析图片
解析表格
Python与Word
Python与Excel
数据分析决策
邮件系统
服务器部署
机器学习
未完待续
…