行人重识别阅读笔记之Unity Style Transfer for Person Re-Identification
行人重识别阅读笔记之Unity Style Transfer for Person Re-Identification
- 摘要
-
- 主要问题
-
- CamStyle的不足
- UnityGAN
- 论文贡献
- 模型
-
- UnityGAN
- UnityStyle
- Deep Re-ID Model
- Pipeline
-
- Training
- Testing
- 总结
paper: https://arxiv.org/pdf/2003.02068.pdf
摘要
风格变换一直是ReID的一个主要挑战,其目的是在不同的摄像机下匹配相同的行人。现有的研究试图用相机不变描述子空间学习来解决这个问题。当不同相机拍摄的图像差异较大时,会产生更多的图像伪影。
为了解决这个问,作者提出了一种统一风格UnityStyle自适应方法。此方法可以平滑同一个摄像机和不同摄像机之间的风格差异。具体来说,首先创建UnityGAN来学习相机之间的风格变化,给每个相机生成形态稳定的风格统一图像,即UnityStyle图像。使用UnityStyle图像来消除不同图像之间的风格差异,使query和gallery之间更好的匹配。
主要问题
由于环境、光线等因素的影响,每个摄像头拍摄的图像风格对于同一个人往往是不同的。即便是同一个摄像机,也会因为时间不同,拍出风格不同的照片。因此,图像的风格变化,对最终结果有相当大的影响。
解决思路是在不同的摄像机之间获得稳定的特征表示。此前的方法:
1、传统方法有KISSME、DNS等。
2、IDE、PCB通过深度表示学习来解决。
3、使用GANs学习不同相机之间的风格差异,通过风格转移的方法对数据进行增强,从而得到CamStyle。
CamStyle的不足
本文对前者方法CamStyle指出不足之处:
1、在CycleGAN生成的转移样本中会有图像伪影,尤其是对于成型部分,生成了大量的错误图像。
2、生成的图像增强会给系统带来噪音,需要用标签光滑正则化Label Smooth Regularization(LSR)需要调整网络性能。
3、生成的增强图像只能作为扩展训练集的数据增强方法,效果不明显。
4、需要训练的模型数量是C2¬C(C是摄像机的个数),这意味着随着摄像机的增加,需要训练的模型将越来越多,这不适用于算力不足的场景。
UnityGAN
针对上述问题,本文构建了一种UnityStyle自适应方法,用于平滑同一个摄像机内部和不同摄像机之间的风格差异。作者使用UnityGAN来克服CycleGAN容易变形的问题。利用UnityGAN学习的每个摄像头的style数据,得到适合所有相机风格的UnityStyle图像,使得生成的增强图像更加高效。最后,结合真实图像和UnityStyle图像作为新的数据增强训练集。
UnityStyle自适应方法具有以下优点:
1、作为一种数据增强方案,生成的增强样本可以与原始图像一样处理。因此UnityStyle图像不再需要LSR。
2、通过适应不同的摄像机模式,它对同一个摄像机内的样式变化也具有鲁棒性。
3、不需要额外的信息,而却所有增强都来自ReID任务。
4、只需要训练C个UnityGAN模型,不需要太多的计算资源。
论文贡献
综上所述,本文的贡献可以概括为:
1、提出UnityStyle方法,用于生产形态稳定、风格变化的增强图像,并与真实图像等效,不在需要LSR。
2、UnityStyle不需要训练大量的模型。只需要使用少量的计算资源来训练C个模型。
模型
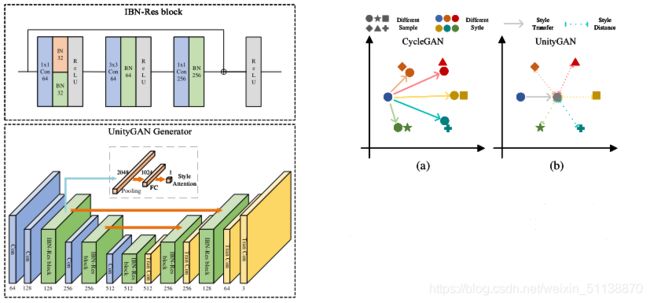
UnityGAN
UnityGAN集合了DiscoGAN和CycleGAN的优点,并加以改进。其中DiscoGAN使用标准架构,其狭窄的瓶颈层bottleneck layer可能会阻止输出图像在输入图像中保留视觉细节。CycleGAN引入了残差快residual blocks来增加DiscoGAN的容量。但是在单个尺度层上使用残差块并不能在多个尺度层上保留信息。
UnityGAN结合了两个网络,在多尺度层引入残差块和跳转链接,可以同时保留多尺度信息,使变化更加精确和准确。通过多尺度的传递,UnityGAN可以生产结构稳定的图像,避免生产结构错误的图像,与CycleGAN不同的是,UnityGAN试图生产一张混合所有样式的图片,而不必学习每个样式的转换。
此外,创建一个IBN-Res块,它可以保证结构信息的同时增强样式变化的健壮性。在UnityGAN模型中添加IBN-Res块,使模型适应风格变化,确保模型生成同一风格的伪图像。
给定图像域X和Y,设G:X->Y,F:Y->X。DX和DY分别表示G和F的鉴别器。为了改变样式的同时保留图像的特征信息,在公式中加入了身份映射损失identity mapping loss。身份映射损失可以表示为:
![]()
因此,UnityGAN的损失函数包含四种损失归一化项:标准GANs损失、特征匹配损失、身份映射损失和循环重建损失。
总目标函数是: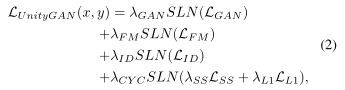
![]()
![]()
其中,SLN是调度损失归一化 scheduled loss normalization,
λGAN+λFM+ λID+ λCYC= 1, λSS+ λL1= 1,所有系数都>0。
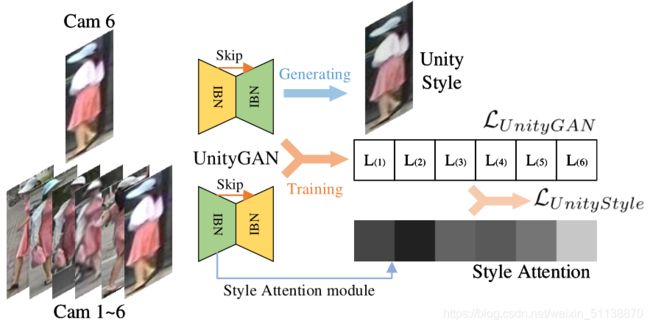
在训练过程中,将训练集的每个摄像头和所有摄像头作为一组来训练一个UnityGAN模型。UnityGAN可以生产稳定的结构图像,减少训练模型的数量。但是UnityGAN生产的图像在风格上不稳定,为了解决这个问题,提出了UnityStyle loss函数,以确保UnityGAN生成 的图像风格稳定。
UnityStyle
UnityStyle图像是由UnityGAN生成的,可以平滑同一个摄像机内和不同相机之间的风格差异。利用UnityStyle图像进行模型训练和预测,提高模型的性能。
为了保证UnityGAN能够生成UnityStyle图像,作者在UnityGAN生成器中添加了Style Attention模块。通过这个模块,底层图像特征得到Style化的注意特征。定义输入图像x的Style Attention为![]()
其中Astyle是Style Attention模块,G1是UnityGAN生成器的第一个IBN-Res块的输出。
最终UnityStyle loss函数为:
其中,c是摄像机编号,C是摄像机数量。A(yi)是第i个摄像机的style attention。
在此loss函数的约束下,模型会生产一副风格稳定的图像,该图像的风格介于所有摄像机风格之间。
Deep Re-ID Model
这里论文中以IDE举例嵌入他们的方法。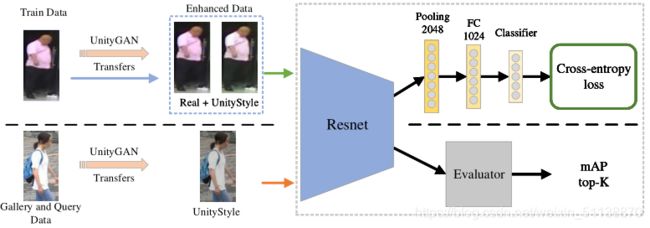
输入图像大小指定为256x128,在训练过程中,需要确保最终分类层输出和训练集中的标签数量一致。如上图所示,将最后一层分类层替换为两个全连接层。在测试过程中,使用模型的2048维特征输出进行评估。Evaluator使用输出特征计算平均精度(mAP)和top-K(表示正确结果在K个top检索结果中所占比例)
Pipeline
Training
在训练之前,使用训练好的UnityGAN Transfers来生成UnityStyle图像。结合真实图像和UnityStyle图像作为增强的训练集,在训练中,以增强后的数据量中的图像作为输入,大小指定为256x128,随机抽取N副真实图像 和N副UnityStyle图像。根据上述定义,得到损失函数: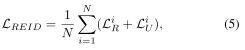
![]()
其中,xR是真实图像样本,xU是UnityStyle图像样本。LCross是交叉熵损失函数。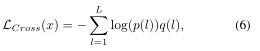
其中L是标签数量,p(l)是x的标签被预测为l的概率,q(l) = {1 if l = y|0 if l 6=y}是真实分布,根据前面的描述![]()
在q(l)中,y是当前图像对应的真实标签。
对于有真实标签y的x,根据公式(6)可以得到![]()
进一步根据公式(7)和公式(5),可以得到![]()
这里,piR是第i个真实图像被正确预测的概率,piU是第i个UnityStyle图像被正确预测的概率。
Testing
为了进行测试,将其分为查询数据集和图库数据集,前面引入UnitStyle的概率,以确保两个数据集的图像在开始测试之前通过UnityStyle传输生成相应的UnityStyle图像。使用生成的UnityStyle图像作为新的输入进行测试,UnityStyle缩小了测试集中元素样式之间的差异,可以进一步提高查询性能。
总结
在我看来本篇论文可以说是做为一种数据增强的方法更贴切。所做的工作看上去就是在增强数据。
核心思想是通过GANs生成图像来尽可能的减小摄像头之间以及摄像头图像内部的风格差异。
其方法是通过所构建的UnityGAN来集合所有摄像头中同一行人的图像来生成符合所有摄像头不同风格的图像,其中图像生成被UnityStyle约束,然后以生成的UnityStyle图像并上真实图像作为增强数据集去训练模型。在预测阶段使用UnityGAN来生成符合模型风格的伪图像进行预测。相当于训练和测试都进行了数据预处理。