决策树 随机森林 xgboost_从决策树到随机森林的预测模型优化—以预测保定市空气质量为例...
一、相关理论简介
(一)决策树算法
决策树是一种非参数的学习方法。在一个决策树的决策过程中,决策树的每个非叶节点表示一个特征属性上的测试,每个叶节点存放一个类别。最初问题所在的地方为根节点,在得到结论前的每一个问题都是中间节点,得到的结论都称为叶子节点。但是基于纯度理论较为复杂,所以决策树是利用纯度的对立面——不纯度来进行划分目标变量。决策树算法自从被提出以来,经过几次优化调整,目前主要有ID3、C4.5和CART三种算法,其中ID3、C4.5和CART分别使用信息增益、信息增益率、基尼指数来划分不纯度。在衡量方式的基础上,还需要两个步骤来建立模型,根据分裂属性选择建树和树剪枝。
1 分裂属性选择建树
分类属性选择树杈作为自变量,以上说的三种方法对于分类属性的选择方式跟不纯度的衡量方式一致,不同的属性选择方式决定决策树不同的算法类型。



2 决策树模型的剪枝介绍
在树的构建过程中,许多分支由于噪声值和异常值,会出现过拟合现象,为了处理这种过拟合问题,可使用剪枝的方法去掉部分分支,这也是决策树停止分支的方法之一。
①决策树模型的“先剪枝”处理。在决策树建树过程中,先设定一个指标,当达到指标设定时,就停止构造,一旦停止,该结点即为树叶。不过有一个“视界局限”,在停止分支后,相当于断绝了后继节点“好”的分支的可能性,会导致产生的树不纯度降差最大的地方过分靠近根节点。
② 决策树模型的“后剪枝”处理。默认先建立完全生长的决策树,然后测验树上的所有相邻叶节点,记录其是否不纯度增长,如果增长则剪枝成功,如果不增长则不剪枝,这样对所有的叶结点进行测试。通过这种剪枝方法可以有效地克服“视界局限”,但是也会带来模型非平衡的影响。该种后剪枝方法适合小样本情况,对于大样本的数据则表现较差。
(二)随机森林算法
随机森林(RF)算法是由多个决策树组合而成的集成分类模型,一个决策树是一个分类器,每个分类器中分别用独立同分布的随机变量决定每棵树的生长方向,集成分类能获得比单个模型更好的分类表现。随机森林的两大随机思想为Bagging和特征子空间思想。
①Bagging思想通过不断地有放回抽样来训练对应的决策树。每次约有67%的样本数据被抽中,以此建立的决策树作为集合随机森林模型。
②特征子空间思想通过选择最优属性来作为分裂节点。在决策树节点分裂时,选择随机抽取的属性子集中最优的属性来作为分裂节点。
随机森林的生成步骤如下:
步骤一样本抽取:首先是行采样,对总体样本数据进行随机抽样,因为是有放回抽样,所以会得到有重复的样本集合,但是每个样本分别输入,建立决策树就会减少过拟合现象出现的可能性。接着是列采样,从样本数据中的总特征属性M中随机抽取m个(m<
步骤二完全分裂:第一步完成后会得到不同的子样本,每个样本包含的特征属性也不尽相同。基于此用不同的样本数据建立决策树,使用的是完全分裂的方式。该过程会有两种结果:一种是决策树的某一个叶子节点无法继续分裂,另一种是所有样本的数据都可以被归为同一类。
步骤三:根据以上的决策树模型得到对应的分类结果,最后根据分类标签结果进行记录并投票,表决票数最多的为最终分类结果。
图1为具体流程图:
 图 1 RF基本原理图
图 1 RF基本原理图
(三)模型的调优介绍
建立模型的目的在于正确的预测判别空气质量等级,当模型在测试集上表现糟糕时,就说明建立的模型泛化程度低,泛化误差大,模型的效果不好,泛化误差受到模型结构的影响,如图2所示。只有当模型的复杂度刚好的时候,才能够使模型达到泛化误差最小的目标。
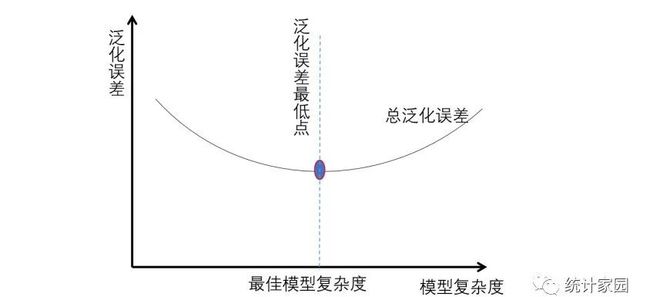 图 2 模型复杂度与泛化误差关系示意图
图 2 模型复杂度与泛化误差关系示意图
模型调优的步骤应该是首先确定建立的模型究竟位于图像的哪一侧,然后向着相反的方向调整模型的复杂度。决策树和随机森林模型一般位于图的右上角,因此,应该朝着减少模型复杂度角度调整模型的参数,把模型往图像的左边移动,防止过拟合。
二、保定市空气质量等级预测的实证分析
(一)数据来源及指标处理
本文数据来源于“天气后报”,通过历史检索可以整理保定市2014-2019年日空气质量状况,数据包含AQI指数、空气中主要污染物浓度以及当天的温度和风力情况,共2008条数据,将数据75%作为训练集,25%作为测试集。
为方便建模分析,根据国家环境保护部对空气质量级别的划分(HJ633-2012),AOI指数分为六个等级:
表 1 空气质量标准等级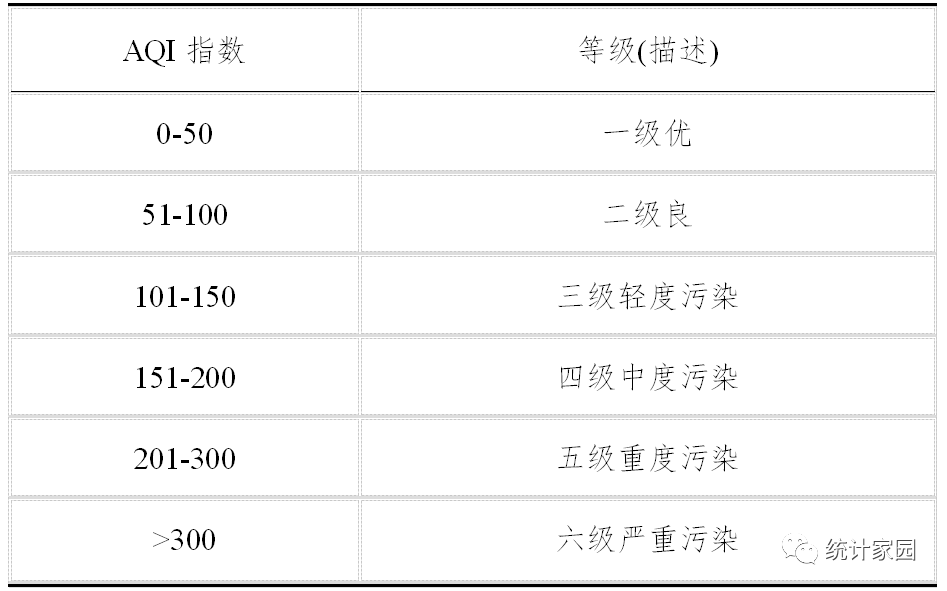
将风力按照如下规则进行量化:
表 2 风力量化范围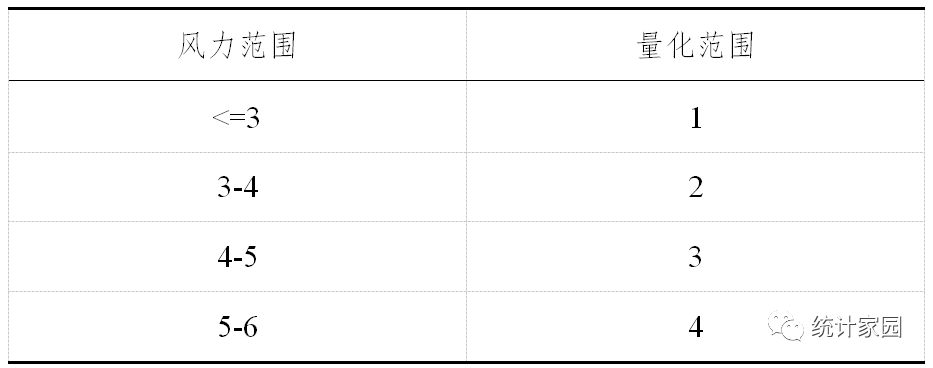
(二)决策树模型
1 基本模型构建
首先依照信息熵方法建立C4.5模式下的决策树,使用fit函数得到最优化的模型训练模型,可以看出此时的决策树默认参数下的决策树模型为10层,部分叶节点的样本数量较少,初步判断存在过拟合的现象。
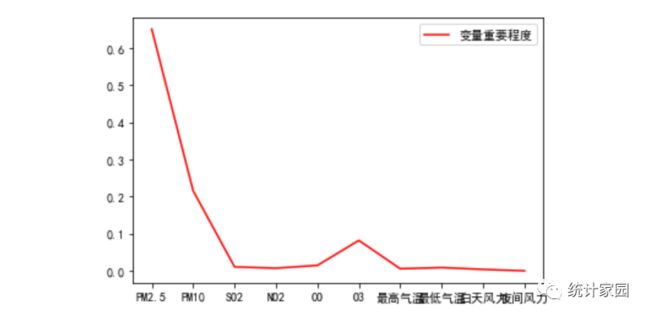 图 3 变量重要程度
图 3 变量重要程度
图3表示变量特征的重要性程度,可以看到PM2.5、PM10和O3对模型的影响程度较高,排在决策树的上层,其次为SO2、NO2、CO、最高气温、最低气温、白天风力和夜间风力在树的下层。
调用score函数对模型进行打分,可以看到训练集的总体精确度为1.0,测试集的精确度为0.89,模型对训练集与测试集的预测精度评分差距很大,可以认为存在一定的过拟合现象,有一定的提升空间。
2 模型参数的优化调整
① criterion的调整:为了要将表格转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法。对分类树来说,衡量这个“最佳”指标叫做“不纯度”。通常来说,不纯度越低,决策树对训练集的拟合越好。
criterion这个参数正是用来决定不纯度的计算方法的。sklearn提供了两种选择:一种是输入“entropy”,使用信息熵(Entropy);另一种是输入“gini”,使用基尼系数(Gini Impurity)。
更改模型参数为“gini”可以得到优化后测试集的预测准确率为86.69%,相对“entropy”参数及信息熵下的模型下降了2.62%。
表 3 参数 criterion 精确度
表3结果显示,所用模型criterion选取的参数最终为“entropy”。
② splitter的调整:splitter也是用来控制决策树中的随机选项的,有两种输入值。输入“best”,决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝;输入“random",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。这也是防止过拟合的一种方式。改变模型的参数对比发现:
表 4 参数 spliter 精确度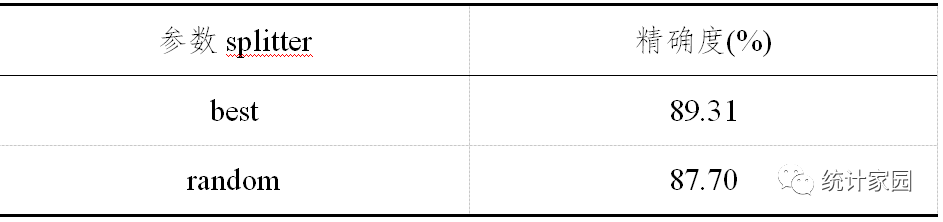
表4中,splitter采用的参数为”best”。
③ max_depth参数的调整:在不加限制的情况下,一棵决策树会生长到衡量不纯度的指标最优,或者没有更多的特征可用为止。上文建立的模型就存在这样的问题,包含了太多的噪声,对测试集的预测结果不够准确,因此需要对模型进行剪枝处理。通过max_depth限制树的深度,超过设定深度的树枝全部剪掉。把决策树模型的层数从1开始逐步增加至10层,计算出每层对应的精确度,如图4:
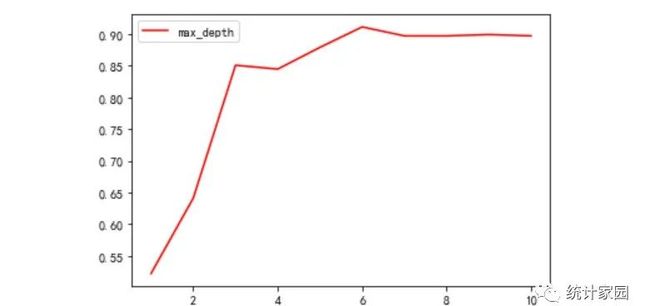 图 4 不同层数对应精确度图
图 4 不同层数对应精确度图
由图4可以看到树的层数为6层时,模型的预测准确率达到最高,所以取使模型准确率较高的6层。
表 5 最优调参准确率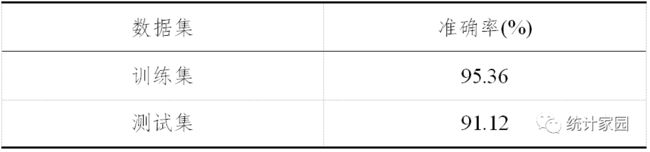
由表5结果对比可以看出,训练集和测试集的预测结果相差不大,模型的过拟合程度降低了,训练集也损失了一定的精确度。
经过上文的分析,综合建立的4个决策树模型选取最优的模型,最终建立最优参数的决策树模型。
那么调参后的预测结果显示如表6:
表 6 决策树算法调参后预测准确率和召回率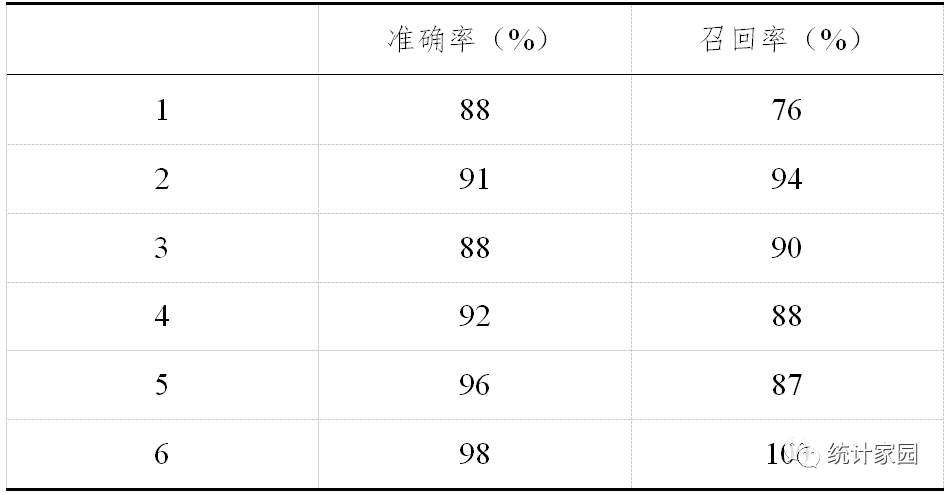
由表6可以看出模型对空气质量为“严重污染”和“重度污染”两个等级的预测精确度达到98%和96%正确,正确率较高;对空气质量为“优”和“轻度污染”两个等级的预测准确率都为88%,有一定的误差,空气质量为“良”和“中度污染的预测准确率在91-92%之间,总体来说模型准确率达到91%。
最终模型的准确率为91%,但是对于空气质量的预测错误率为9%,这对于环境治理来说仍然具有一定的风险,有一定概率的误导性。因此,下面尝试随机森林方法更进一步提高预测的精确度。
(三) 随机森林模型
1 基本模型构建
首先,加载随机森林所需要的命令,为使每次抽样为相同的样本,规定抽取的随机数种子为90,随机森林模型默认初始建立的决策树为10棵,根据训练集数据建立随机森林模型,然后对测试集数据进行预测分析,所得结果如表7:
表 7 随机森林预测结果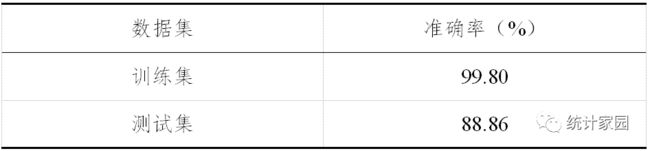
表7结果显示,训练集分类效果准确率高,高达99.80%,测试集准确率仅有92.14%,与训练集相比差距7.66%,差距较大,说明该模型很大程度存在过拟合问题。在此基础上所建立的模型虽然针对特定的数据分类效果极好,但在实际应用中推广率有限,因此,需要对已有模型进行调参。
2 模型参数的优化调整
下面对决策树数量进行调整:选择对模型影响较大的五个参数,分别调整得到最优的随机森林模型并进行预测。
① nestimators参数的调整:在1至200中每隔10个数随机选取数据作为决策树数量,然后计算分类的精确率,所得结果如图5所示:
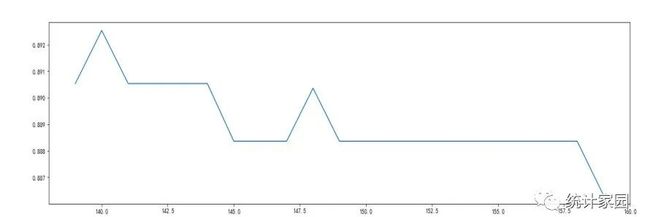 图 5 随机森林算法调参后预测准确率
图 5 随机森林算法调参后预测准确率
这个属性是典型的模型表现与模型效率成反比的影响因子,即便如此,还是应该尽可能提高这个数字,这样才可使模型更准确更稳定.从图5可以看出,选择最高点可以预测最高正确率,因此决策树数量调至140时,预测效果最好,所得到的空气质量预测准确率最高。
② max_depth参数的调整:定义不同深度下的随机森林模型,查找最优的深度。通过调试,确定最优深度为11,最优得分为0.924。
③ min_samples_leaf参数的调整:默认为最高复杂度,向复杂度降低的方向调参,该参数越小模型越简单,通过调试,确定最优叶子节点样例数为1,最优得分0.924。
④ min_samples_split参数的调整:默认为最高复杂度,向复杂度降低的方向调参。通过调试,确定最优分裂内部节点样例数为8,最优得分0.925。
⑤ Criterion参数的调整:可选项为“gini”,“entropy”分别代表模型采取计算方法,来构建决策树,进而构建随机森林模型。就目前模型来看,最优选择是“gini”,最优得分0.925。
根据训练集预测结果来对模型进行评估,在本文中,如对空气质量预测准确率越高,说明该模型预测预测效果越好。
表 8 随机森林算法调参后预测结果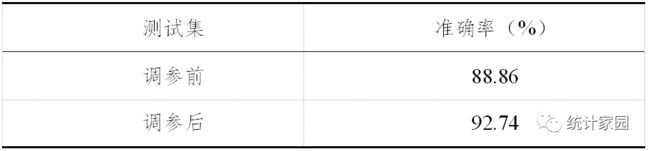
由表8看来,参数调整以后,随机森林预测效果较好。
表 9 随机森林预测结果
由表9可以看出,模型对空气质量为“严重污染”和“重度污染”两个等级的预测精确度达到98%和96%正确,正确率较高;对空气质量为“优”等级的预测准确率都为89%,有一定的误差,空气质量为“良”、“轻度污染”和“中度污染的预测准确率在91-93%之间,总体来说模型准确率达到93%。
在该模型中,使用空气主要污染物浓度和天气状况等十个指标,建立了11棵决策树,得到了较好的预测水平,对空气质量等级的预测结果显示较好。随机森林模型参数比较多,调整较慢,很难找到最优的参数组合是模型应用的不足之处。
(四)评价
总结建立的两个模型,预测正确率展示在表10中:
表 10 模型准确率对比表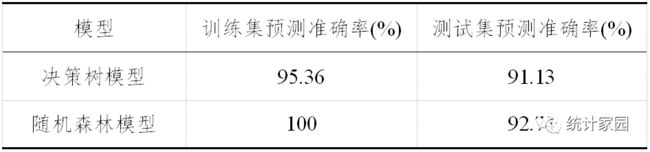
在两个模型的训练集预测上,随机森林的准确率正确率为100%,测试集预测准确率随机森林提高度没有训练集高。作者认为,一方面是为了保证模型的效率性,决策树的个数选择没有选择预测准确率较高的棵树;另一方面是随机森林的参数没有调到最优状态,仍然有提高的空间。不过相比来说选用集成算法随机森林模型较好。
下面是整理的主要Python代码,仅供参考:
#决策树模型import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn import treefrom sklearn.datasets import load_winefrom sklearn.model_selection import train_test_splitXtrain, Xtest, Ytrain, Ytest = train_test_split(data[column_names[1:11]],data[column_names[11]],test_size = 0.25,random_state = 33)Xtrain.shapeXtest.shape# 决策树模型一,默认参数下的模型clf = tree.DecisionTreeClassifier(criterion="entropy")clf = clf.fit(Xtrain, Ytrain)score1 = clf.score(Xtrain,Ytrain)scorec = clf.score(Xtest, Ytest) #返回预测的准确度print(score1)print(scorec)#特征重要性clf.feature_importances_plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签plt.plot(feature_name,clf.feature_importances_,color="red",label="变量重要程度")plt.legend()plt.show()clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30,splitter="best")clf = clf.fit(Xtrain, Ytrain)score = clf.score(Xtest, Ytest)scoreimport graphvizdot_data = tree.export_graphviz(clf,feature_names= feature_name,class_names=["优","良","轻度污染","中度污染","重度污染","严重污染"],filled=True,rounded=True) graph = graphviz.Source(dot_data)graph#我们的树对训练集的拟合程度如何?score_train = clf.score(Xtrain, Ytrain)score_test = clf.score(Xtest, Ytest)print(score_train)print(score_test)clf_y_predict = clf.predict(Xtest)print('模型预测结果')print(list(clf_y_predict))print('测试及实际结果')print(list(Ytest))from sklearn.metrics import classification_report #使用评分函数score获得模型在测试集上的准确性结果print('Accuracy of clf Classifier:',clf.score(Xtest,Ytest))#使用classification_report模块获得其他三个指标的结果(召回率,精确率,调和平均数)print(classification_report(Ytest,clf_y_predict,target_names=['1','2','3','4','5','6']))# 随机森林模型的构建from sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import GridSearchCVfrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import KFoldfrom sklearn.model_selection import train_test_splitimport matplotlib.pyplot as pltimport pandas as pdimport numpy as np# 随机森林模型一默认参数下rfc = RandomForestClassifier(oob_score=True,random_state=90)rfc = rfc.fit(Xtrain,Ytrain)score_r = rfc.score(Xtest,Ytest)score_rscore_q = rfc.score(Xtrain,Ytrain)score_qscore_pre = cross_val_score(rfc,Xtest,Ytest,cv=10).mean() # 交叉验证计算评分均值score_pre# 随机森林模型二找到最优的n_estimators参数scorel = []for i in range(0,300,10): rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1,random_state=0) rfc = rfc.fit(Xtrain,Ytrain) score = cross_val_score(rfc,Xtest,Ytest,cv=10).mean() scorel.append(score)print(max(scorel),(scorel.index(max(scorel))*10)+1)plt.figure(figsize=[20,5])plt.plot(range(1,301,10),scorel)plt.show()scorel = []for i in range(160,240): rfc = RandomForestClassifier(n_estimators=i,n_jobs=-1,random_state=0) rfc = rfc.fit(Xtrain,Ytrain) score = cross_val_score(rfc,Xtest,Ytest,cv=10).mean() scorel.append(score)print(max(scorel),([*range(160,240)][scorel.index(max(scorel))]))plt.figure(figsize=[20,5])plt.plot(range(160,240),scorel)plt.show()#随机森林模型七找到最优参数下的随机森林模型rfc = RandomForestClassifier(criterion='gini',n_estimators=197 ,random_state=90,max_depth=9,min_samples_leaf=1 ,min_samples_split=12)rfc = RandomForestClassifier(n_estimators=100,random_state=90)rfc = rfc.fit(Xtrain,Ytrain)score_s = rfc.score(Xtest,Ytest)score_s# 模型进行评分from sklearn.metrics import classification_report #使用逻评分函数score获得模型在测试集上的准确性结果print('Accuracy of rfc Classifier:',rfc.score(Xtest,Ytest))#使用classification_report模块获得逻辑斯蒂模型其他三个指标的结果(召回率,精确率,调和平均数)print(classification_report(Ytest,lr_y_predict,target_names=['1','2','3','4','5','6']))