Linux运维集群篇 使用squid代理加速负载均衡集群
文章目录
- 前言
- 一、squid服务器
-
- 1 代理的机制和作用
- 2 类型
- 二、部署squid服务
-
- 1.文件解压并编译文件
- 2.修改配置文件
- 3 运行squid配置
- 4 创建脚本文件
- 三 构建传统代理和透明代理
-
- 传统代理
- 透明代理
- 四 ACL访问控制
- 五 ACL日志
前言
一、squid服务器
1 代理的机制和作用
作用
Squid 主要提供缓存加速、应用层过滤控制的功能。
机制
1、代替客户机向网站请求数据,从而可以隐藏用户的真实IP地址。
2、将获得的网页数据(静态 Web 元素)保存到缓存中并发送给客户机,以便下次请求相同的数据时快速响应。
2 类型
传统代理:适用于Internet,需在客户机指定代理服务器的地址和端口。
透明代理:客户机不需指定代理服务器的地址和端口,而是通过默认路由、防火墙策略将Web访问重定向给代理服务器处理。
反向代理:如果 Squid 反向代理服务器中缓存了该请求的资源,则将该请求的资源直接返回给客户端;否则反向代理服务器将向后台的 WEB 服务器请求资源,然后将请求的应答返回给客户端,同时也将该应答缓存在本地,供下一个请求者使用。
二、部署squid服务
1.文件解压并编译文件
systemctl stop firwalld
systemctl disable firewalld.service
wget -P /opt http://www.squid-cache.org/Versions/v3/3.5/squid-3.5.28.tar.gz
tar zxvf squid-3.5.28.tar.gz
yum -y install gcc gcc-c++ make
cd /opt/squid-3.5.28
./configure --prefix=/usr/local/squid \
--sysconfdir=/etc \
--enable-arp-acl \
--enable-linux-netfilter \
--enable-linux-tproxy \
--enable-async-io=100 \
--enable-err-language="Simplify_Chinese" \
--enable-underscore \
--enable-poll \
--enable-gnuregex
make make install
ln -s /usr/local/squid/sbin/* /usr/local/sbin/
useradd -M -s /sbin/nologin squid
chown -R squid:squid /usr/local/squid/var/

2.修改配置文件
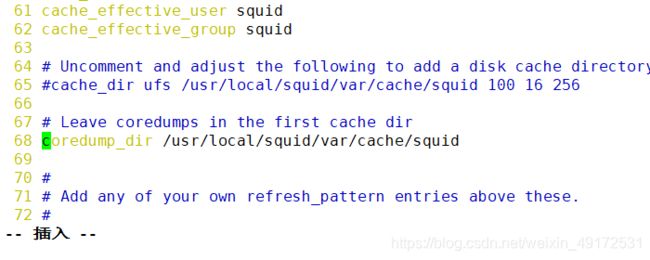
vim /etc/squid.conf
52
http_access allow all
http_access deny all
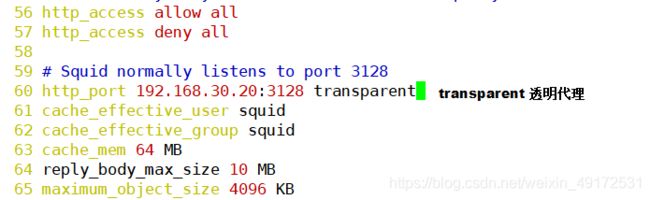
http_port 3128
61
cache_effective_user squid
cache_effective_group squid
68
coredump_dir /usr/local/squid/var/cache/squid

3 运行squid配置
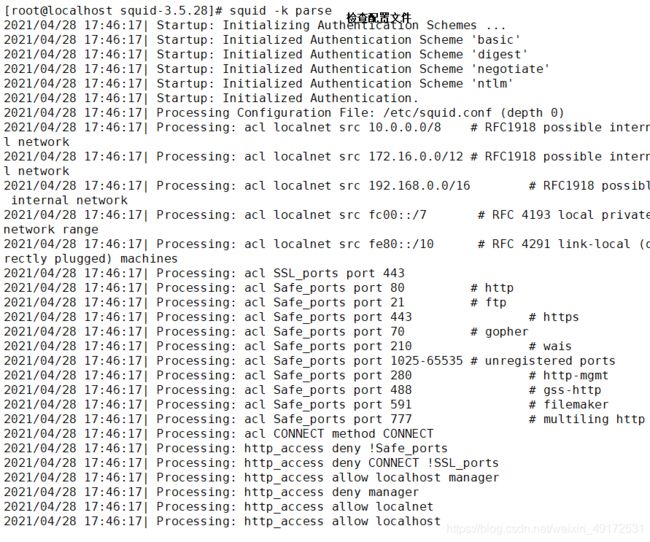
squid -k parse
squid -z 初始化缓存目录
squid 开启服务
netstat -anpt | grep "squid"

4 创建脚本文件
vim /etc/init.d/squid
chmod +x /etc/init.d/squid
chkconfig --level 35 squid on
chkconfig --list squid


三 构建传统代理和透明代理
传统代理
vim /etc/squid.conf
cache_mem 64 MB
reply_body_max_size 10 MB
maximum_object_size 4096 KB
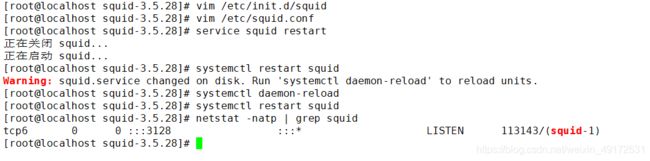
service squid restart
systemctl daemon-reload
netstat -natp | grep squid

配置防火墙策略
iptables -F
iptables -I INPUT -p tcp --dport 3128 -j ACCEPT
iptables -L INPUT

客户机检查

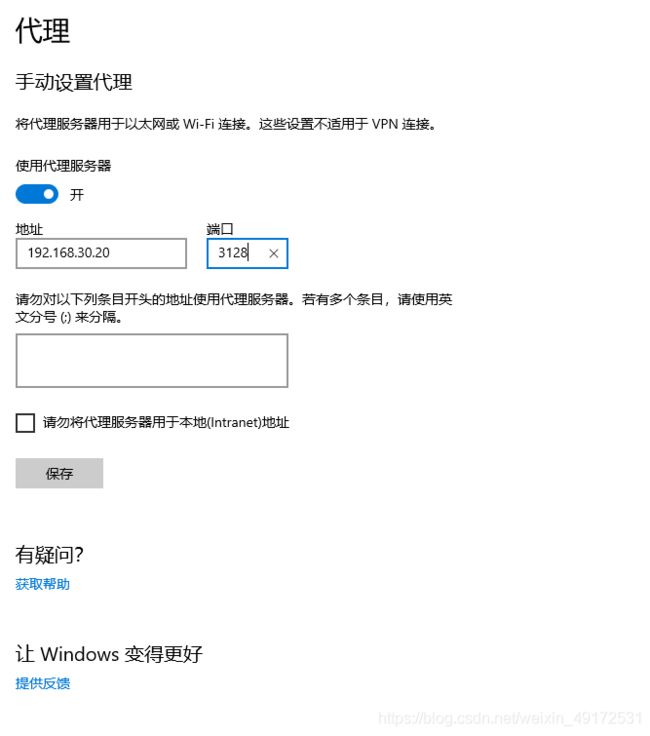
查看web页面

查看日志
cd /usr/local/nginx/logs/
cat access.log
![]()
透明代理
web1
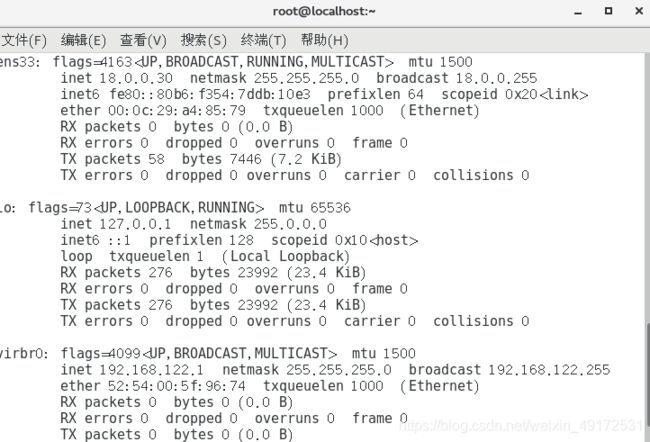
代理
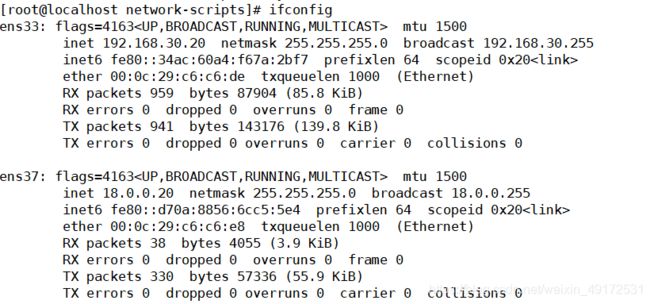
开启服务

开启路由转发

配置防火墙策略

客户机验证
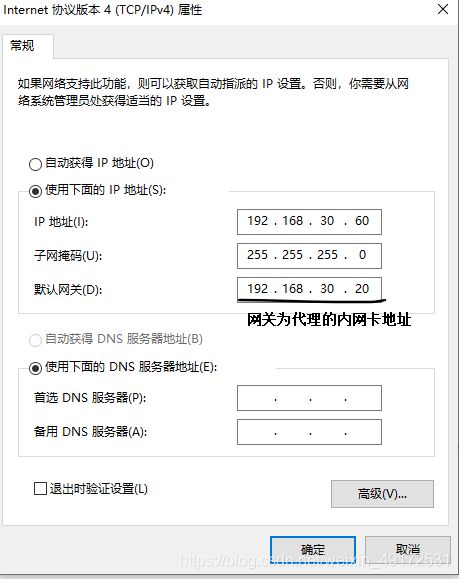

查看日志
![]()
四 ACL访问控制
squid的ACL 访问控制通过以下两个步骤来实现:
(1)使用 acl 配置项定义需要控制的条件;
(2)通过 http_access 配置项对已定义的列表做“允许”或“拒绝”访问的控制。
先写一个列表文件 配置不允许访问的IP 即黑名单
配置文件修改 使用列表文件


直接修改配置文件也可以
vim /etc/squid.conf
.......
acl localhost src 192.168.30.10/24 #源地址为192.168.184.10
acl MYLAN src 192.168.30.0/24 #客户机网段
acl destinationhost dst 192.168.30.22/24 #目标地址为192.168.184.20
acl MC20 maxconn 20 #最大并发连接20
acl PORT port 21 #目标端口21
acl DMBLOCK dstdomain .qq.com #目标域,匹配域内所有站点
acl BURL url_regex -i ^rtsp:// ^emule:// #以rtsp://. emule://开头的URL,-i表示忽略大小写
acl PURL urlpath_regex -i \.mp3$ \.mp4$ \.rmvb$ #以 .mp3、.mp4、.rmvb结尾的URL路径
acl WORKTIME time MTWHF 08:30-17:30 #时间为周一-至周五8:30~17:30, "MTWHF"为每个星期的英文首字母
五 ACL日志
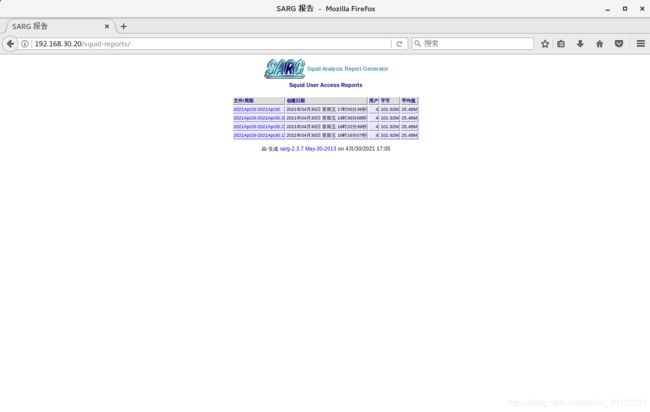
采用sarg来管理日志 是一款squid日志分析工具,采用HTML格式,详细列出每一位用户访问Internet的站点信息、时间占用信息、排名、连接次数、访问量等
#安装图像处理软件包
yum install -y gd gd-devel pcre-devel
mkdir /usr/local/sarg
#将zxvf sarg-2.3.7.tar.gz压缩包上传到/opt目录下
tar zxvf sarg-2.3.7.tar.gz -C /opt/
cd /opt/sarg-2.3.7
./configure --prefix=/usr/local/sarg \
--sysconfdir=/etc/sarg \ #配置文件目录,默认是/usr/loca/etc
--enable-extraprotection #额外安全防护
./configure --prefix=/usr/local/sarg --sysconfdir=/etc/sarg --enable-extraprotection
make && make install
vim /etc/sarg/sarg.conf
--7行--取消注释
access_log /usr/local/squid/var/logs/access.log #指定访问日志文件
--25行--取消注释
title "Squid User Access Reports" #网页标题
--120行--取消注释,修改
output_dir /var/www/html/sarg #报告输出目录
--178行--取消注释
user_ip no #使用用户名显示
--184行--取消注释,修改
topuser_sort_field connect reverse #top排序中,指定连接次数采用降序排列,升序是normal
--190行--取消注释,修改
user_sort_field connect reverse #对于用户访问记录,连接次数按降序排序
--206行--取消注释,修改
exclude_hosts /usr/local/sarg/noreport #指定不计入排序的站点列表的文件
--257行--取消注释
overwrite_report no #同名同日期的日志是否覆盖
--289行--取消注释,修改
mail_utility mailq.postfix #发送邮件报告命令
--434行--取消注释,修改
charset UTF-8 #指定字符集UTF-8
--518行--取消注释
weekdays 0-6 #top排行的星期周期
--525行--取消注释
hours 0-23 #top排行的时间周期
--633行--取消注释
www_document_root /var/www/html #指定网页根目录
#添加不计入站点文件,添加的域名将不被显示在排序中
touch /usr/local/sarg/noreport
ln -s /usr/local/sarg/bin/sarg /usr/local/bin/
sarg --help #获取帮助
#运行
sarg #启动一次记录
#验证
yum install httpd -y
systemctl start httpd
在squid服务器上使用浏览器访问 http://192.168.184.70/sarg,查看sarg报告网页。
#添加计划任务,执行每天生成报告
vim /usr/local/sarg/report.sh
#/bin/bash
#Get current date
TODAY=$(date +%d/%m/%Y)
#Get one week ago today
YESTERDAY=$(date -d "1 day ago" +%d/%m/%Y)
/usr/local/sarg/bin/sarg -l /usr/local/squid/var/logs/access.log -o /var/www/html/sarg -z -d $YESTERDAY-$TODAY &> /dev/null
exit 0
chmod +x /usr/local/sarg/report.sh
crontab -e
0 0 * * * /usr/local/sarg/report.sh