每天学习亿点点-和python爬虫的第一次见面
文章目录
- 前言
- 一、requests模块是什么?
- 二、使用步骤
-
- 1.指定url
- 2.发起请求并获得响应数据
- 3.持久化存储
- 4.UA伪造
- 总结
前言
今天过安检 机器一直在响 安检员搜了半天 也没发现金属 最后才发现原来是我打工人那钢铁般的意志。
提示:本篇是在学习Python基础知识之后的一次小小尝试,以下是本篇文章正文内容。
一、requests模块是什么?
requests模块:python中原生的一款基于网络请求的模块,功能强大,效率极高。使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷。
众所周知,日常生活中的搜索引擎(如百度),其实就是一个巨大的爬虫,在输入想要的内容后,点击‘百度一下’,程序就会搜索你想要的内容,python中的爬虫道理也是一样的。而pthon中requests模块的作用就是模拟浏览器发起请求!
二、使用步骤
1.指定url
这里我用的是搜狗,打个比方,我在搜狗中搜索3,url就会发生变化:
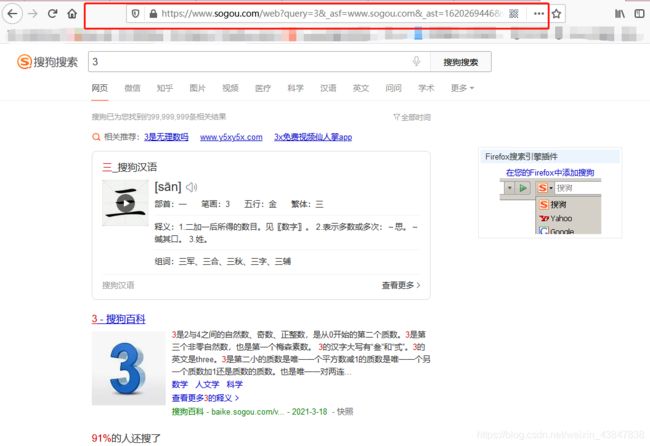
此时url为:https://www.sogou.com/web?query=3&_asf=www.sogou.com&_ast=1620269446&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=4790&sst0=1620269446500&lkt=1%2C1620269441710%2C1620269441710&sugsuv=1616430468352050&sugtime=1620269446500
会发现,后面跟着巨长的一段参数,其实我们只要其中最重要的一个参数query即可,所以,将url修改为:
https://www.sogou.com/web?query=3,重新执行:
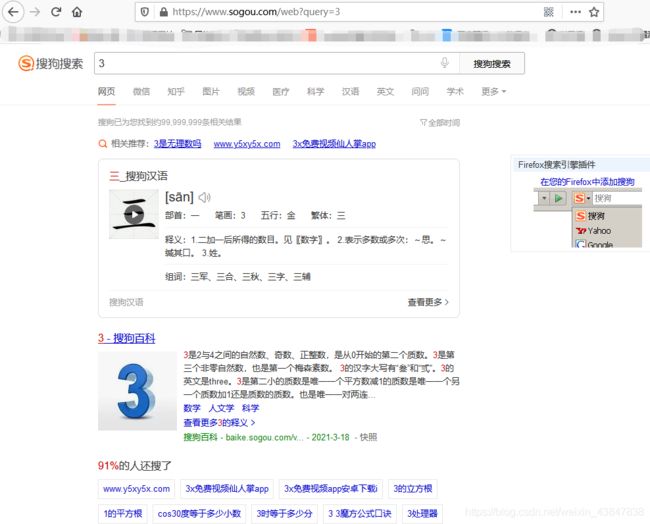
嘿嘿嘿,发现返回的页面也是一样的,都是搜索3以后的结果,因此,这里python我所用的url就是:
代码如下(示例):
import requests
url = "https://www.sogou.com/web"
顺便将想要搜索的内容可自定义,这里我定义了一个变量:
代码如下(示例):
se = input("输入你要查的:")
param = {
"query": se
}
2.发起请求并获得响应数据
代码如下(示例):
response = requests.get(url=url, params=param)
response.encoding = "utf-8"
这里需要用到response模块来获得响应数据,编码用了utf-8,params即参数。
3.持久化存储
代码如下(示例):
page_text = response.text
print(page_text)
fileName = se+ ".html"
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
定义变量page_text来获取响应的文本,并创建一个html格式的文件来存储数据。
4.UA伪造
UA伪造:门户网站的服务器会检测对应请求的载体身份标识,如果检测请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求,但是如果检测到请求的载体身份标识不是基于某一款浏览器的,则标识改请求不是正常的请求(爬虫),则服务器端就很有可能拒绝该次请求。
UA:User-Agent(请求载体的身份标识)
代码如下(示例):
headers = {
"User-Agent": "Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 88.0.4324.150 Safari / 537.36"
}
至此,完整爬虫的代码为:
import requests
if __name__=="__main__":
headers = {
"User-Agent": "Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 88.0.4324.150 Safari / 537.36"
}
url = "https://www.sogou.com/web"
se = input("输入你要查的:")
param = {
"query": se
}
response = requests.get(url=url, params=param, headers=headers)
response.encoding = "utf-8"
page_text = response.text
print(page_text)
fileName = se+ ".html"
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileName+'爬取结束!')
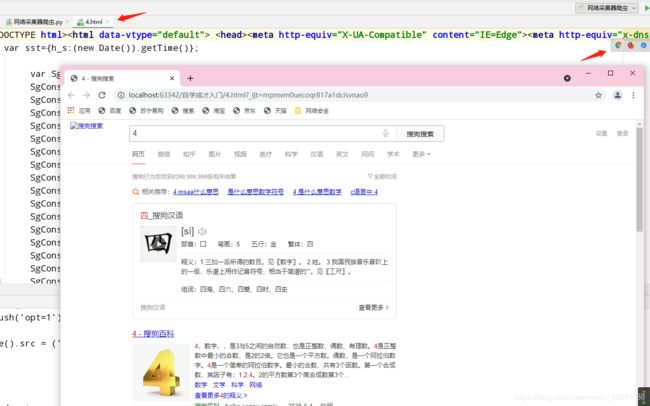
运行结果:
总结
本站所有文章均为原创,欢迎转载,请注明文章出处: https://blog.csdn.net/weixin_43847838/article/details/116448552.。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。