AI-powered, full stack, automated performance management
问题生命周期
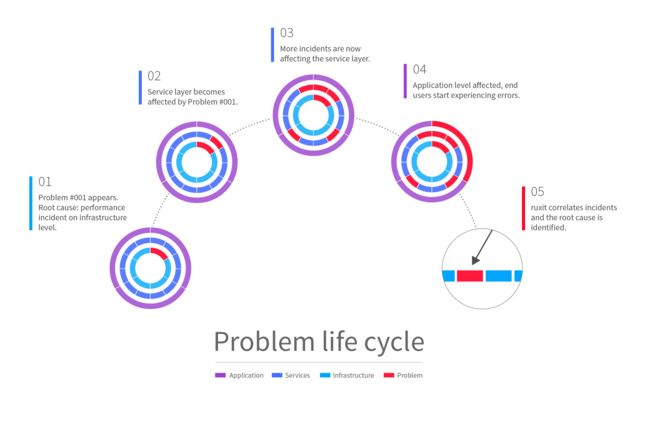
性能异常如何发现?它会影响到哪些应用或服务?Dynatrace 采用基准性能偏差比较法来发现异常,并通过依赖关系进行关联。下面通过一个基础设施层的性能异常导致的故障案例来深入了解。
1. Dynatrace 检测到一个基础设施层的性能异常,此时,创建一个新的问题以便追溯,并发送告警通知。
2. 几分钟后,这个基础设施的问题导致某个应用服务的性能出现下降。
3. 其他应用服务的性能也相继出现问题。此时,单个的基础设施问题逐渐演变成了一系列的服务级问题,并且前者是后者的根因。
4. 最终,服务级问题开始影响终端用户与应用的交互体验。在问题生命周期中,此时转化为一个应用级问题,它包含一个基础设施层的根因以及若干个服务级根因。
5. Dynatrace 感知整个环境的所有依赖关系,因此,可以将影响客户体验的性能异常与基础设施的问题进行关联,从而快速解决问题。 您的环境中出现的每个问题都可以使用上述根因分析方法进行定位,只需在问题详情页面点击根因分析,就能看到 Dynatrace 对该问题执行的分析结果。
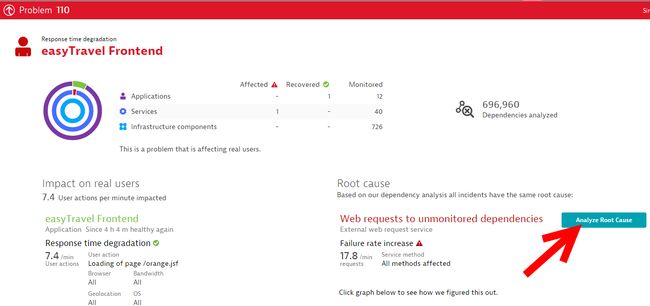
问题检测
Dynatrace 提供了一种全方位的应用程序运行状态监控,它从多个角度持续监控你的应用程序。
应用程序(终端用户)- 经验告诉我们,当终端用户访问你的应用程序时,最关注响应时间与整体性能。
服务- 也就是你的应用程序提供给客户的各种服务,包括 Web 请求,数据库请求和服务间通信。
基础设施- 这一层包括为您的客户提供服务的物理/虚拟机。具体可细分为服务器,数据库,主机和进程等。

如何关联各层间的异常事件?
Dynatrace 了解应用程序栈中所有层与组件之间的依赖关系,比如应用程序调用了哪些服务?该服务运行在哪些主机的哪些进程上?
分析底层依赖关系
点击问题详情页面的可视化解析路径,可以查看导致问题发生的底层服务或基础设施异常事件分析。可视化解析路径显示了您的应用程序与支持它的底层服务和基础设施组件之间的依赖关系。
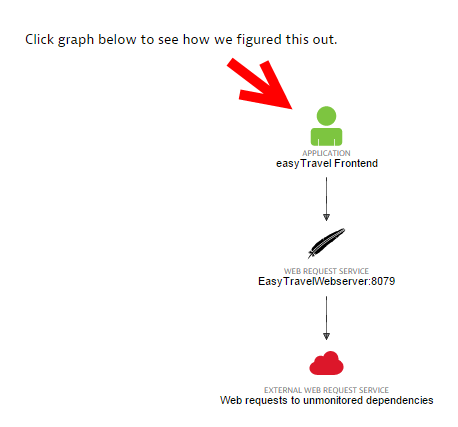
每一个可视化解析路径都包含一个问题演进查看器,可以使用它来回放问题随时间的演变情况。在这里,我们可以非常详细地看到问题发生期间,应用依赖关系的交互与执行情况。比如,你可以看到哪些服务调用失败或基础设施健康问题导致了其他服务调用失败,并最终导致影响客户体验的应用异常。

为什么要关注最慢的 10% 的响应时间?
虽然大部分 APM 工具专注于平均响应时间,但 Dynatrace 特别强调最慢的 10% 的响应时间,这是因为,如果你只知道大多数用户的平均(中位数或平均值)响应时间,你可能就会遗漏一个严重问题:某些用户正在遭受无法容忍的性能问题。
比如一个典型的搜索服务,它会执行一些数据库调用,这些数据库调用的响应时间可能会有很大差异,这取决于它们的数据是走缓存 or 数据库?中位数度量方法在这种场景也难以胜任,尽管你的大多数用户(走缓存)的响应时间还不错,但少数用户(走数据库)将遭受无法容忍的性能问题,因此,将监控的重点放在最慢的 10% 的客户上,可以解决这类问题。
如何有效发挥时间相关性?
单看时间相关性,难以有效地识别大部分性能问题的根因。因此,Dynatrace 更强调事件序列。
首先,让我们来看一个简单的时间相关性的例子,服务 A 调用了服务 B。在问题演变过程中,第一个发生的异常事件是服务 B 性能下降,然后,出现了服务 A 性能下降的事件。在这个案例中,时间相关性似乎很好地表明了问题的根因:服务 B 的性能下降导致了服务 A 的性能下降,但这只是一个简单的场景。
如果问题演变序列中的事件更加细化,交叉更紧密怎么办?如果示例中的服务 A 有一段很长的性能问题历史怎么办?在这些场景下,就无法断定服务 A 的问题是由服务 B 导致的,可能服务 A 只是周期性历史问题的又一次呈现。这些细微之处导致了单独的时间相关性无法有效确定问题的根因。
问题与事件
问题
Dynatrace 的问题包括 AI 驱动分析,环境上下文,根因分析以及细节信息。问题能够自我表述,比如性能下降,功能不当和服务不可用等。一个问题可能是单个事件或多个事件的结果。
事件
Dynatrace 中的事件是指手动执行操作,比如机器重启,系统关机,进程重启或代码部署等。在服务器上执行的任何手动操作都是一个事件,即使它是一种周期性调度事件。
你可以在事件模块找到每一个独立主机、虚拟机或服务的事件列表。

代码部署事件
软件代码的部署也属于一种事件,这种部署事件有时会导致性能问题。Dynatrace 将跟踪所有事件,并关联所有发现的性能事件。如果我们注意到新代码部署或系统重启后,立即出现了性能下降,我们将通知你,并提供部署前后的性能测量比较。这些信息可以直接发送给软件开发者,以便快速修复。
问题如何提出与评估?
Dynatrace 通过指定阈值持续检测服务水位,如果发现性能下降或错误率升高,就生成一个新的问题事件。采用5分钟滑动窗口来评估响应时间的剧烈上升,采用15分钟滑动窗口来评估响应时间的缓慢上升。
检测阈值
Dynatrace 采用三种类型的阈值:
动态基线:多维度的动态基线根据历史数据自动生成检测阈值,这类基线主要用于检测响应时间、错误率和负载等指标。
内置的静态阈值:Dynatrace 采用内置的静态阈值来检测所有的基础设施异常事件,比如 CPU 过高、磁盘空间不足,或内存不足等。
用户自定义静态阈值:你可以更改基础设施的默认检测阈值,也可以将应用程序和服务的动态基线切换为静态阈值。
通过动态基线生成的异常事件与静态阈值方法有较大差异,下面将提供两种方法的详细介绍。
动态基线
Dynatrace 通过动态基线来自动学习应用/服务的响应时间、错误率和负载等指标的检测阈值。
针对响应时间,Dynatrace 同时采集了中位数与90线(最慢的10%)的值,如果中位数和90线同时出现异常上升,则提出一个减速(响应慢)的事件。
应用基线用来预测下述4个维度的指标:
用户行为:应用程序的用户操作,例如登录、注销等。
地理位置:将用户会话来源的地理位置进行层次化组织,可以分为大陆、国家、地区和城市。
浏览器:浏览器层次划分,先区分类型,如 Firefox 和 Chrome,在同一类型下再区分版本号
操作系统:操作系统层次划分,先区分类型,例如 Windows 和 Linux ,同一类型下再区分版本号
服务基线用户预测服务方法维度指标
服务方法:一个服务的某个方法,如 getBookingPage 或 getReportPage
在数据库服务中,不同的服务方法表示不同的 SQL 语句,比如 (call verify_location(?) select booking0_.id from Booking booking0_ where booking0_.user_name<>?)
针对预定义的组别、静态请求和动态请求可以计算额外的基线阈值,比如分别计算预定义组别 insert、update 和 select 多维组合数据会分别计算所属组合的动态基线,下面这个案例描述了来自纽约和北京的用户指标阈值:
bash `USA - New York – Chrome – Reference response time : 2sek, error rate: 0%, load: 2 actions/min`
bash `China – Bejing - QQ Browser - Reference response time : 4sek, error rate: 1%, load: 1 actions/min
Dynatrace 通过 OneAgent 来收集数据,并且需要两个小时的历史数据以计算动态基线,因此,你可以在你的应用接入 OneAgent 两小时后,开始添加多维数据集进行检测。Dynatrace 每天都会重新计算一次基线,以便自适应流量的变化。
为了避免过度报警并降低通知噪音,自动异常检测模式不会对波动应用或服务(每周运行时间小于20%)发送通知。
Dynatrace 的流量异常检测基于如下假设:大多数业务流量遵循可预测的天/周流量模式。流量报警会在一周后开始启用,因为流量基线需要一周的历史数据来进行学习。
经过一周的学习后,Dynatrace 可以预测下一周的流量,并将实际流量与预测值进行比较,如果检测到超出预测值合理统计区间的偏差点,Dynatrace 就会创建一个Unexpected low traffic 或 Unexpected high traffic 问题。
动态基线的优点:
开箱即用,无需手动配置阈值
无需手动设置地理位置,浏览器等特定阈值
自适应流量模型的变化
动态基线的缺点:
需要经历一段学习期,来学习正常流量模式
总结
基线通过 5分钟和15分钟的滑动时间窗口进行评估
自动检测响应时间、错误率和负载的参考值
应用有4个维度组合,服务只有一个维度
多维数据集的基线计算需要在初次延迟两小时,之后每天会自动执行
应用或服务每周至少要运行20%的时间,才会对其发送报警
应用至少需要运行一周,才会进行流量模型的检测与报警
减速(响应慢)事件需要同时检测中位值与90线
静态阈值
Dynatrace 的基础设施监控基于大量的内置、预定义静态阈值。这些阈值涉及资源争用,比如 CPU 尖峰,内存和磁盘使用率等。基线阈值和内置阈值都支持用户进行覆盖修改。
静态阈值优点:
无需学习期,可以立即进行告警
静态阈值缺点:
需要大量的人工操作
为动态的服务设置固定阈值非常难
无法自适应环境的变化
总结
基础设施监控基于许多指标的预定义静态阈值。
静态阈值无需学习期,可以立即开启检测与告警