在 - -爬虫数据分析学习交流 - 微信群里有位朋友Jacky提到爬取中国银行遇到的问题,一时兴起便做了尝试。

-
首先还原问题,我们禁用js,在chrome浏览器中新建标签页,F12 > F1 >打开设置在右下角找到禁用js并勾选

- 打开中国人民银行条法司网页发现如下的页面显示
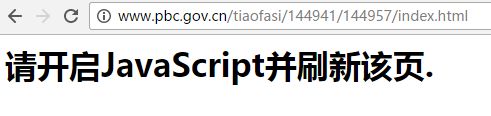
-
然后F12关闭开发者控制台,刷新页面,显示正常

- 利用chrome插件,EditThisCookie,在控制台中查看cookie如下,同时禁用js再次打开网页却发现显示正常,而清空cookie(禁用js)后打开又出现问题显示。

- 这是因为该网页首先传给你的html文件中包含cookie设置和动态跳转网址的js代码,js代码运行后会自动设置cookie并跳转链接,到达正常页面。
-
我们查看问题页面的源码,Ctrl-U
 Paste_Image.png
Paste_Image.png - 源码很乱,以我的菜鸡水平根本看不出来什么东西,这时需要优秀工具的帮助,http://jsbeautifier.org/ 是一款优秀js代码美化和解析工具,我们将代码放上去解析,终端curl网页得到的js代码和解析后的代码对比鲜明

-
与一般的代码美化工具比较(下图),不仅格式化了代码,并且可读化了代码,这样以我的水平就可以分析代码了。

-
首先两次请求该网址,将两次美化后的代码进行对比,我们可以看到不仅在js全局变量上有改变,在其中一个加密函数里也有小改动。


- 某一个请求里的js代码,留存参考,阅读可先跳过:
var dynamicurl = "/L3RpYW9mYXNpLzE0NDk0MS8xNDQ5NTcvaW5kZXguaHRtbA==";
var wzwschallenge = "RANDOMSTR14925";
var wzwschallengex = "STRRANDOM14925";
var template = 4;
var encoderchars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
function KTKY2RBD9NHPBCIHV9ZMEQQDARSLVFDU(str) {
var out, i, len;
var c1, c2, c3;
len = str.length;
i = 0;
out = "";
while (i < len) {
c1 = str.charCodeAt(i++) & 0xff;
if (i == len) {
out += encoderchars.charAt(c1 >> 2);
out += encoderchars.charAt((c1 & 0x3) << 4);
out += "==";
break;
}
c2 = str.charCodeAt(i++);
if (i == len) {
out += encoderchars.charAt(c1 >> 2);
out += encoderchars.charAt(((c1 & 0x3) << 4) | ((c2 & 0xf0) >> 4));
out += encoderchars.charAt((c2 & 0xf) << 2);
out += "=";
break;
}
c3 = str.charCodeAt(i++);
out += encoderchars.charAt(c1 >> 2);
out += encoderchars.charAt(((c1 & 0x3) << 4) | ((c2 & 0xf0) >> 4));
out += encoderchars.charAt(((c2 & 0xf) << 2) | ((c3 & 0xc0) >> 6));
out += encoderchars.charAt(c3 & 0x3f);
}
return out;
}
function findDimensions() {
var w = window.innerWidth || document.documentElement.clientWidth || document.body.clientWidth;
var h = window.innerHeight || document.documentElement.clientHeight || document.body.clientHeight;
if (w * h <= 120000) {
return true;
}
var x = window.screenX;
var y = window.screenY;
if (x + w <= 0 || y + h <= 0 || x >= window.screen.width || y >= window.screen.height) {
return true;
}
return false;
}
function QWERTASDFGXYSF() {
var tmp = wzwschallenge + wzwschallengex;
var hash = 0;
var i = 0;
for (i = 0; i < tmp.length; i++) {
hash += tmp.charCodeAt(i);
}
hash *= 11;
hash += 111111;
return "WZWS_CONFIRM_PREFIX_LABEL4" + hash;
}
function HXXTTKKLLPPP5() {
if (findDimensions()) {} else {
var cookieString = "";
cookieString = "wzwstemplate=" + KTKY2RBD9NHPBCIHV9ZMEQQDARSLVFDU(template.toString()) + "; path=/";
document.cookie = cookieString;
var confirm = QWERTASDFGXYSF();
cookieString = "wzwschallenge=" + KTKY2RBD9NHPBCIHV9ZMEQQDARSLVFDU(confirm.toString()) + "; path=/";
document.cookie = cookieString;
window.location = dynamicurl;
}
}
HXXTTKKLLPPP5();
- 这种程度的js代码(美化后)并不难理解,很明显可以看出最后的函数调用中利用document.cookie设置了两个cookie,并利用window.location设置了跳转网址,静下心去分析也能用python写出相应的加密程序,用正则取配到变量,生成我们想要的信息,但是有没有更快的方法呢。这时我们又有一个强大的工具,Js2Py,利用它我们可以解析js代码变为python中的可执行代码。如下官方简单示例:

- 下面的思路就清晰了,先利用js美化工具的python库jsbeautifier(pip安装)美化代码,然后不管js代码中关于dom操作的内容(如window.xx),取出js全局变量和加密函数,利用js2py生成可执行的python函数,以js代码中的主干逻辑在python里执行获得cookies,在requests.session中更新cookies并访问js变量中的动态网址,就可以成功到达内容页,开始爬取解析了。
- 以下为python代码,可以看到最后成功验证我们爬取到了有效信息。
import requests
import re
import jsbeautifier
import js2py
host_url = 'http://www.pbc.gov.cn/'
dest_url = 'http://www.pbc.gov.cn/tiaofasi/144941/144957/index.html'
# 利用session保存cookie信息,第一次请求会设置cookie类似{'wzwsconfirm': 'ab3039756ba3ee041f7e68f634d28882', 'wzwsvtime': '1488938461'},与js解析得到的cookie合起来才能通过验证
r = requests.session()
content = r.get(dest_url).content
# 获取页面脚本内容
re_script = re.search(r'', content.decode('utf-8'), flags=re.DOTALL)
# 用点匹配所有字符,用(?P...)获取:https://docs.python.org/3/howto/regex.html#regex-howto
# cheatsheet:https://github.com/tartley/python-regex-cheatsheet/blob/master/cheatsheet.rst
script = re_script.group('script')
script = script.replace('\r\n', '')
# 在美化之前,去掉\r\n之类的字符才有更好的效果
res = jsbeautifier.beautify(script)
# 美化并一定程度解析js代码:https://github.com/beautify-web/js-beautify
with open('x.js','w') as f:
f.write(res)
# 写入文档进行查看分析
jscode_list = res.split('function')
var_ = jscode_list[0]
var_list = var_.split('\n')
template_js = var_list[3] # 依顺序获取,亦可用正则
template_py = js2py.eval_js(template_js)
# 将所有全局变量插入第一个函数变为局部变量并计算
function1_js = 'function' + jscode_list[1]
position = function1_js.index('{') +1
function1_js = function1_js[:position]+ var_ +function1_js[position:]
function1_py = js2py.eval_js(function1_js)
cookie1 = function1_py(str(template_py)) # 结果类似'NA=='
# 保存得到的第一个cookie
cookies = {}
cookies['wzwstemplate'] = cookie1
# 对第三个函数做类似操作
function3_js = 'function' + jscode_list[3]
position = function3_js.index('{') +1
function3_js = function3_js[:position]+ var_ +function3_js[position:]
function3_py = js2py.eval_js(function3_js)
middle_var = function3_py() # 是一个str变量,结果类似'WZWS_CONFIRM_PREFIX_LABEL4132209'
cookie2 = function1_py(middle_var)
cookies['wzwschallenge'] = cookie2
# 关于js代码中的document.cookie参见 https://developer.mozilla.org/zh-CN/docs/Web/API/Document/cookie
dynamicurl = js2py.eval_js(var_list[0])
# 利用新的cookie对提供的动态网址进行访问即是我们要达到的内容页面了
r.cookies.update(cookies)
content = r.get(host_url+dynamicurl).content
# 最后验证是否爬取到有效信息
if u'银行卡清算机构管理办法' in content.decode('utf-8'):
print('success')
