大纲:
- 前言
- 日志系统架构是怎样的
- 游戏分析有什么内容
- 为什么要自己架一个系统
- FEN架构
- 架构图
- Fluentd
- ElasticSearch
- NodeJS
- pusher
- logger
- analyser
- 用户界面
- 总结
前言
最近我司需要做一个统一的游戏日志系统,要求有一定的通用性,能应对公司所有的游戏业务。接下来分享一下这次日志系统的项目经验。
日志系统架构是怎样的
目前流行的日志系统为ELK,由Beats、Logstash、Elasticsearch、Kibana等组件共同实现,但万变不离其宗,一个基本的日志系统架构类似如下:

游戏分析有什么内容
游戏分析,与其它服务系统不同的是,游戏内的系统可能是天马行空的,数据类型是多样的,甚至频繁变化的。我们要在变化中总结到不变的内容,例如系统经济产出,玩家物品消耗,商店购买等进行分析。所以这次的游戏日志系统要满足以下需求:
- 记录游戏日志,并随时检索日志;
- 分析玩家行为:玩家留存相关,玩家物品消耗,商店消耗等有一定复杂度的分析;
- 能建立一个统一的日志系统:一次性满足未来游戏运营多样性。
为什么要自己架一个系统
虽然ELK在安装配置方面不算困难,插件众多,例如Filebeat,读log文件,过滤格式,转发,但谁来生产这些log文件,没有提及。实际上,业务具有多样性,只要有日志文件的地方,它就可以用。例如多数会使用Nginx进行日志收集。我们也需要考虑到日志生产者的问题,责权分离,需要单独一台机子进行日志采集。
游戏是一种技术与艺术结合的产品,数据庞杂,形态各异,光日志埋点也花不少功夫复杂,但不能因此放弃治疗。好的游戏日志,还可以帮我们还原玩家玩家画像。游戏更新周期短,数据变化大,需要提供更实时参照报表,为非技术人员更好友的查询界面,才能更好的服务于游戏数据分析。ELK 在这方面,基本解决了采集和储存的问题,但实现分析方面还不能满足我们的需求。
经过一翻思索,我们可以用现有工具,粘合多个套件,所以,我们有了以下思路:
- 日志采集器:
利用Fluented作为日志文件采集器,生产者通过内网HTTP发送到采集器上,那每个生产者同一内网只要部署一个采集器即可,如果量特别大,可以多个,游戏的功能埋点可以统一; - 转发器:
利用NodeJS进行 HTTP 转发即可,前提是能按顺序和分段读取日志文件,结合Fluented间接实现; - 接收器与实时分析:
接收器可以用Koa实现,Redis进行缓存;同时用NodeJS另外一个进程分析和日志入库,分析行为,玩家画像,得出报表,这些非日志源的数据,可以放到MongoDB上,因为这些数据是修改性增长缓慢数据,占用空间不大; - 储存仓库:
ElasticSearch是个很好的选择,能集群,可热增减节点,扩容,还可以全文检索,分词; - 用户界面:
Kibana针对 ElasticSearch提供良好的分析,结合原有的管理后台系统,我们自己实现了一套用户界面。
FEN架构
这个框架主要使用到了Fluentd,ElasticSearch,以及NodeJS,我就称它为 FEN 架构吧,如下图。
架构图
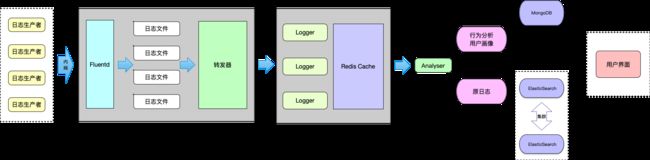
上图看出,这样的日志架构和第一个图基本没什么不同,只是多了后面的分析与分批入库处理,并且大量使用了NodeJS。
注:在这里不会介绍各组件的详细的安装配置方法,网上有太多了,怎样使用好每一个组件才是关键。
先介绍我们用到的工具:
Fluentd
Fluentd是一个完全开源免费的log信息收集软件,支持超过125个系统的log信息收集。Fluentd在收集源日志方面非常方便而且高性能,通过HTTP GET就可以,这类似于Nginx的日志记录行为。它的优点是,日志文件可以高度定制化,例如我们这里每5秒生成一个文件,这样每分钟有12个文件,每个文件体积非常小。为什么要这样做?下面会介绍。Fluentd还有非常多的插件,例如直接存入MongoDB,亚马逊云等,要是熟悉Ruby,也可以自己写插件。
ElasticSearch
有人使用MongoDB进行日志收集,是非常不明智的,只有几千万条还可以,如果半个月生产10亿条日志呢?日志文件需要保存一个月甚至更长,那么集群和硬盘维护就非常重要。使用便利性也很重要,例如分词检索,在客服回溯玩家日志,分析游戏 BUG 的时候非常有用。下文的 ES 也是该组件的简称。
NodeJS
NodeJS不适合做 CPU 密集型任务,但在网络应用方面还不错,并且是我们正好熟悉的。日志系统并不对实时性要求并不高,延时半小时以内都是允许的,事实上,正常情况延时也就10来秒。下面的读与转发日志的Pusher,收集日志的logger,分析日志并数据落袋为安的的analyser,都是由NodeJS实现的。
下面继续介绍用 NodeJS实现的每一个部分:
转发器Pusher
上面说到,为什么Fluentd使用分割成多个小文件的方式,因为NodeJS在大文件处理方面并不友好,并且要考虑到通过网络发送到另一台机,转发速度比读慢太多了,所以必须实现续传与断点记录功能。想想,如果读几百 M 的文件,出现中断后,需要永久记录上次位置,下次再从此处读起,这就增加了程序复杂度。NodeJS虽然有readline模块,但测过发现并不如文件流那样可控,访模块用于交互界面尚可。相反,如果日志分割成多个小文件,则读的速度非常高效,并且每5秒一个文件,哪怕有上万条记录,文件也大不到哪里去,内存也不会占用太多,在断点续传与出错重试方面都能自如应对。如果游戏日志增多,可以增加节点来缓解文件过大的压力。
为什么不直接让日志生产者直接发到Koa上?因为效率与带宽。NodeJS的适合做网站,但比专业的HTTP服务器要弱太多,4核心主机面对3000QPS就吃力,更多的关于NodeJS的性能问题,可以参考网络文章。在高并发量下,带宽是个很大的问题,尤其是需要做统一服务,面对的情况是日志机器与游戏并不在同一内网中。在10万日活下,带宽超过了50M,非常吓人,带宽可是很贵的,过高的带宽费用在这里性价比太低了。
Pusher的注意点:
- 批量转发:不要一条条日志发,采用批量发送。根据单条日志文件大小,如果是 JSON 数据,有10多个字段,那么每次请求发送50~100条发送都是没问题的,也就几十 KB;
- 串行序顺发送:从时间小的文件,从文件关开始发,等待上一次发送请求完成再执行下一次;
- 发送失败保存重试:如果某一次请求失败,则保存到另外一个文件目录,以时间戳作为文件名,下次重试,尽可能保证数据完整性;
- 每100毫秒读一次文件列表,检查有没有新的日志文件。虽然是每5秒产生一次日志文件,但有可能出现效率下降导致发送速度跟不上而产生文件积压,即使是空读也是允许的,这不基本不占什么CPU。第100毫秒的间隔不要使用setInterval,应该在上一次文件发送完毕再setTimeout来执行;
- 发送速度提供可变性,如果下面的logger效率低下,上面的100毫秒可以适当放缓一些。
日志收集器logger
这里我们使用Koa作为日志采集器。使用Koa,无论在性能还是开发效率上,都比expressJS高效。我们还用到了Redis作为缓存,而不是直接在这里做分析任务,是为了尽量提高与Pusher的对接效率,毕竟日志的生产速度是很快的,但网络传送是相对低效的。
logger的注意点:
- 使用缓存缓存数据,如Redis;
- 关注内存:logger与pusher是两台机子,当logger的缓存提升太快,也就是后面的分析与入库速度跟不上了,需要返回消息告知pusher放慢发送速度;
- 安全验证:简单的方式是pusher发送时可以进行md5验证,logger验签;
- 如果使用Redis,在Redis 4.0以下,使用list记录每条日志 ID,日志使用hash节省内存。在Redis 3.x不要使用Scan,它有BUG,就是Scan出的数量是无法确定的,就算明确指定了条数,但有可能出现一次读数万条,也有可能一次读几十条,这对后面的分析器非常不利;
- Redis记得开启 RDB,以及maxmemory设置,前者可以在出问题时还原状态,后者可以防止出现灾难时资源暴掉,搞崩其它服务;
- 无论是不是使用Redis,应该使用支持管道,或者批量的方法,如redisio,根据机器效率,如每次满500条就入缓存,不满就100毫秒入一次,减少缓存操作次数可以提高效率;
- logger可以用pm2的集群模式,提高效率。
注:pm2 3.2.2的集群可能出现集群内端口冲突的吊诡问题,建议用3.0.3
分析器analyser:
分析器读取Redis的内容,这里就是单进程的队列操作。到这一步,日志怎么分析,就可以很自由了。
分析器analyser的注意点:
- 单线程可以确保每个玩家的日志时间序列;
- Redis的读取使用管道,一次读取数千条进行分析。参考值:目前每次读3000条进行处理,在4核心中低配置云主机下单线程占用仅为35%左右;
- 日志存ES:源日志文件可以进行进一步分析或者格式优化,处理后的放ES,ES 就是为集群而生,通过加入子节点可以热扩容,硬盘便宜,所以先做3个节点的集群吧;
- 配置好ES的索引(mapping),仔细考虑各字段类型,凡是要与搜索条件有关的,例如要查元宝大于多少的,那么元宝字段必须有索引,否则将无法根据该字段查找日志。还有,想要分词的必须使用text类型。日志一般不会进行汇总,因为我们已经统计大部分内容了,所以可以适当减少doc_value,压缩率等,否则一千万条日志半小时内就吃掉1G硬盘。这需要你好好研究 ES 的索引配置了,后面还得研究 ES 的搜索,因为它比MongoDB的复杂得多,但这很值得;
- ES和MongoDB的入库,使用批量处理,根据机器性能和系统资源找到合适的批处理数量。参考值,4核下 ES 批量入库1000条效率300ms 左右;
- ES 配置好内存,默认是1G JVM内存,经常不够用就会崩溃。在配置文件同目录下有个jvm option文件,可以加大JVM,建议至少分配一半以上内存;
- ES 的写入效率:不要以为 ES 的输入速度很快,默认它是写一条更新一条索引,也就是必须等把数据更新到索引才会返回,无论使用批量处理还是单个,日志量大的时候,批处理仅100条也会超过500ms。设置durability为async,不要马上更新到索引;
- ES使用别名索引,好处是当你需要重建索引时,可以通过另外重新指向到新的索引,因为 ES 不能修改索引,只能重建;
- 在分析的时候,先还原玩家画像,对其它数据报表,组织好你的数据结构,数据量小、简单的可以同时放内存中进行计数,并定期条件清理,大的如玩家画像放redis中,定期更新入库。这些数据的缓存方式可以使用完整版本,简化问题,减少出现脏数据的可能;同时分析也要注意效率的问题,例如有Mongodb数据的读写,要务必配置到index,否则将引起灾难性效率下降。
用户界面
因为我们本身有后台管理系统,所以我们很方便的把用户画像与其它分析点接了入去,在查询玩家行为时,我们搜索ES,在查询分析报表时,我们查询MongoDB中的数据。当然我们也使用了Kibana来满足可能的需求。
总结
目前该日志系统运行1个半月,由纯MongoDB到结合 ES,走了不少弯路,还好现在终于稳定下来。目前在性能方面,logger 与 analyser都在同一台机,平均 CPU 为23%左右,高峰47%左右,说明还有更大的机器压榨空间。
内存方面,在高峰期5G 以内,总体非常平稳没多大波动,其中redis内存使用为800MB以内,但机器是16G,还有很大余量保障。
NodeJS 的脚本中,logger的CPU占用更小,3条进程,每条才3%,每条内存占用不到100MB。analyser 的 CPU 与内存占用多一点,这一点可以通过脚本内的参数调整,例如内存计数的内容清理得更快,使用pm2的话设置max_memory_restart : '4G' 都可以提高稳定性。
以上是我在游戏日志系统中的经验总结。
参考文献:
- 在Node.js中读写大文件 https://cnodejs.org/topic/55a73038f73c01466cf931f2