数据仓库简介
写于2014年秋
是什么
数据仓库是一个面向主题的、集成的、非易失的、随时间变化的用来支持管理人员决策的数据集合。
面向主题的(subject-oriented):
数据仓库围绕一些主题,如顾客、供应商、产品和销售组织。数据仓库关注决策者的数据建模与分析,而不是集中于组织机构的日常操作和事务处理。
集成的(integrated):
通常,构造数据仓库时将多个异种数据源,如关系数据库、一般文件和联机分析处理记录,集成在一起。使用数据清理和数据集成技术,确保命名约定、编码结构、属性度量等的一致性。
非易失的(Nonvolatile):
数据仓库中的数据通常以批量方式载入访问,但在数据仓库中并不进行数据更新。当产生变化时,一个新的快照记录就会写入数据仓库。
随时间变化的(Time-Variant):
数据仓库中的每个数据单元只是在某一时间是准确的。在一些情况下,记录加有时间戳,而在另外一些情况下记录则包含一个事务的时间。记录都包含某种形式的时间标志用以说明数据在那一时间是准确的。
历史
1.1981年NCR公司(national cash register corporation)为Wal mart 建立了第一个数据仓库,总容量超过101TB
2.商务智能的瓶颈是从数据到知识的转换。1983年,该teradata公司利用并行处理技术为美国富国银行(Wells Fargo Bank)建立了第一个决策支持系统。
3. 1988年,为解决企业集成问题,IBM公司的研究员Barry Devlin和Paul Murphy创造性的提出了一个新的术语:数据仓库(Data Warehouse)
4. 1992年,比尔·恩门(Bill Inmon)出版了《Building the Data Warehouse》一书,第一次给出了数据仓库的清晰定义和操作性极强的指导意见,真正拉开了数据仓库得以大规模应用的序幕。
5.1993年,毕业于斯坦福计算机系的博士拉尔夫·金博尔,也出版了一本书:《The Data Warehouse Toolkit》,他在书里认同了比尔·恩门对于数据仓库的定义,但却在具体的构建方法上和他分庭抗礼。最终拉尔夫金博尔尔由下而上,从部门到企业的数据仓库建立方式迎合人们从易到难的心理,得到了长足的发展。
早期的数据库主要是一些独立的数据库,应用于企业数据处理的各个方面--从事务处理到批处理,再到分析型处理。将操作型数据库和分析型数据库分离开,主要是出于以下原因:
1、服务于操作型需求的数据在物理上不同于分析型需求的数据
2、操作型数据的用户群体不同于分析型数据所支持的用户群体
3、操作型环境的处理特点与分析型环境的处理特点从根本上不同
与OLTP区别
特征 OLTP OLAP
特征 操作处理 信息处理
面向 事务 分析
用户 办事员、数据库专业人员 知识工人(经理、主管、分析员)
功能 日常操作 长期信息需求、决策支持
DB设计 基于E-R,面向应用 星型、雪花,面向主题
数据 当前的 历史的
汇总 原始的,高度详细 汇总的,统一的
视图 详细,一般关系 复杂查询
存取 读、写 基本为读
关注 数据进入 信息输出
操作 主关键字上索引/散列 大量扫描
访问记录数 数十个 数千万
用户数 数千 数百
DB数量 GB 100GB到TB
优先 高性能、高可靠性 高灵活性,端点用户自治
度量 事务吞吐量 查询吞吐量,响应时间
设计要点
事实表
事实表存储了从机构业务活动或者事件中提炼出来的性能度量
粒度
粒度越细,越可以支撑多样的需求;粒度越粗,对特定需求性能支持越好。
维表
事实表仅有键和数值型度量所组成,与事实表不同,维度表不具有健壮性和完整性,它们当中充满了“大而笨重”的描述字段。
缓慢变化维
纵表与横表
纵表灵活,性能需特别关注;横表性能好,需特别关注灵活性。
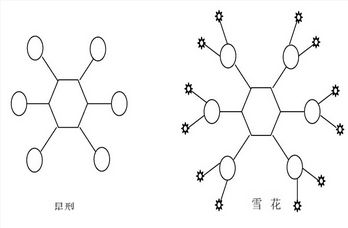 星型模型是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成。所有维表都直接连接到“ 事实表”。
星型模型是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成。所有维表都直接连接到“ 事实表”。
雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 ” 层次 ” 区域,这些被分解的表都连接到主维度表而不是事实表
技术要点
特点
数据量大
弱事务,写少读多
完整性和一致性需求弱
应对
批处理
Mpp数据库
多维数据库
Hadoop等分布式框架
列式存储
多种存储介质
压缩
分区
Load
Bitmap索引
无主外键
不记日志(弱日志)
预统计(inforbright knowledge grid)
DW2.0

ETL
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转置(transform)、加载(load)至目的端的过程。
ETL作为数据仓库的核心和灵魂,能够按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。
1、ETL工具的典型代表有:Informatica、Datastage、Oracle ODI、Kettle。
DataStage(以下简称DS)的基础组件被称为Stage,它所实现的功能,大多是通过在图形界面上拖拉实现的。DS的基础Stage分为两类:Active Stage就是完成数据的转换加载等动作,Passive Stage就是与数据库或者文件进行连接,然后让Active Stage完成其他操作。
Passive Stage可以与文本文件,XML文件,几乎所有的数据库,Web Services, WebSphere MQ和主要的企业级应用如SAP、Siebel、Oracle 以及PeopleSoft进行联接。
Active Stage几乎可以完成SQL所能完成的所有工作,如关联,过滤,去重。
Job Sequence可以将基础JOB联接起来,实现JOB间的依赖,互斥等操作。
加上DS自带的Basic语言,可以实现各种定制Function,也可以在DS Job Job Crontrol中,除可以对JOB进行灵活多样的控制外,也可以完成大多数语言实现的功能。
DS也可以调用其他语言,如Shell(或DOS),TCL,可以完成DS本身难以完成的任务。
当然,调度自然不可少,它支持相对不复杂的以时间为主的调度。以及相关的源数据的管理,备份恢复,调试等功能。
2、ETL自己实现,调度程序+SQL(sp)
调度
调度是ETL的灵魂。ETL调度的设计,决定了ETL所能实现的功能以及灵活性,也决定了其他ETL部分工作量的大小。
调度涉及到的问题主要有优先级,顺序乱序执行,出错处理,重传处理,调度监控,出错、超时报警等。
优先级就是任务之间执行的先后紧急顺序,将Job分为几个优先级,同一优先级或者不同优先级的JOB间有依赖、互斥等关系。
顺序乱序执行,顺序就是同一JOB按照时间的先后顺序执行,而乱序则可以不按照时间顺序执行,主要是一些高频率JOB,异常情况不适合人工处理。
出错处理、重传处理,就是要求整个ETL支持重做。
调度监控,对ETL的处理结果和重要步骤有一个记录,出错或者超时时发邮件或者短信通知相关负责人。监控主是通过TASK日志、JOB日志或者调度日志实现。
Extract
就是从数据源获取数据。在数据抽取时,尽量将没用的数据,错误的数据在抽取时过滤,格式等不符合的转换掉。如果源系统对自己的性能、稳定性要求比较高,则用对源系统打扰尽量少的方式获取,如db2的export,oracle的exp、或者在备机上抽取等方式,然后再做处理。
涉及到的功能主要有:
数据范围过滤,抽取表中所有数据或者根据时间抽取相应数据
字段过滤,只抽取需要的字段,不需要的就不用管
条件过滤,根据抽取条件抽取数据
去除回车换行,如果已抽取成文件,字段中的回车换行将很难去掉
格式转换,特别是时间格式,最好是做成统一格式
赋缺省值,对于空的部分数据,根据需要赋一个缺省值
类型变换,如将number类型转换为varchar类型
代码转换,就是将在不同源系统中同一含义不同的编码表示转换成统一的编码表示,如将代表性别“男”的’N’,’0’转换成’M’
数值转换,就是度量单位的转换
Transform
就是将抽取的数据,进行一定的处理,生成目标表所需要的格式,内容。
涉及到的处理主要有:
字段合并、拆分:字段合并就是将多个字段合并成一个字段;拆分就是将一个字段拆成多个字段
数据翻译,就是不同的数据集进行关联,从另一个数据集中得到所需要的部分数据
数据聚合,就是做一些sum,max等操作
数据合并,相当于数据库中的merge
行列转换,需要将某些数据转换成行,或者是将行转换成列
参照完整性检查,对于数据中的参照完整性,入库前需要进行关联等方式检查其参照完整性
唯一性检查,对数据进行去重操作
Load
就是将数据入库,如果前面的处理都做了,就可以直接入库了。入库的时候需要考滤:
更新入库,对数据库中的记录进行更新
插入,就是将数据直接入库
刷新,将表中的数据清空,然后入库
部分刷新,将表中的部分数据清除,然后入库
由于性能等方面的需要,入库前后,可能需要做一些处理,如索引临时失效,主外键约束临时失效、数据库表不记日志等
数据集市
独立型数据集市
独立型数据集市是为满足特定用户(一般是部门级别的)的需求而建立的一种分析型环境,它能够快速地解决某些具体的问题,而且投资规模也比数据仓库小很多。
从属型数据集市
数据集市就是企业级数据仓库的一个子集,他主要面向部门级业务,并且只面向某个特定的主题。为了解决灵活性和性能之间的矛盾,数据集市就是数据仓库体系结构中增加的一种小型的部门或工作组级别的数据仓库。数据集市存储为特定用户预先计算好的数据,从而满足用户对性能的需求。数据集市可以在一定程度上缓解访问数据仓库的瓶颈。

应用
数据仓库常规使用方式包括常见的报表,即席查询,数据挖掘,BI。
报表是数据仓库中最常见的使用方式,一般都是在晚上提前计算好,使用时,前端报表工具直接根据维度进行查询,然后在前端展现。报表数据比明细数据小很多,具体小多少取决于维度的多少及每个维度维值的多少。报表部分的挑战在于需求非常多样,而且善变,计算量非常大。
即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的固定报表查询是定制开发的,而即席查询是由用户自定义查询条件的。所以即席查询基本不能提前全部计算好,只能计算好一部分。
BI(Business Intelligence)即商务智能,它是一套完整的解决方案,用来将企业中现有的数据进行有效的整合,快速准确的提供报表并提出决策依据,帮助企业做出明智的业务经营决策。数据仓库的一个很大特点是需求的不明确,很多时候是用户看到已经实现部分,才知道下一步该如何做,这此步骤需要反复验证的很多;数据从不同的维度,或者某一维度维值特定时,看其他的数据才有意义。这些特点靠固定报表所需的时间太长,而且修改的太频繁,BI工具部分满足了这些需求。但是BI工具大部分都是针对特定数据库有接口,或者实现了ODBC、JDBC等通用接口,可以跟数据源很好的集成。
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。数据挖掘的实现方式多种多样,总体一个特点就是对数据的高频使用,需要大量的计算,而且经过多次试验后才能确定一个比较好的方案。数据挖掘基于的数据可以是汇总数据,但是大部分需要从明细数据中计算才能发掘比较大的价值。
实时数据仓库
以上都是传统的数据仓库,一般是一周一次、或者一月一次刷新数据。而实时数据仓库要求在极短的时间内,或者实时捕获数据源中发生的变化,并且根据预先设置的规则做出决策。
研究重点
1、数据集成研究问题
实时数据的主动变化捕捉
支持数据一致性和完整性的实时数据分发
实时、高效的连续数据加载
2、数据的组织与管理
RTADW中的数据建模
实时数据的查询一致性维护
实时数据的查询冲突解决
实时数据与历史数据的“无缝”集成
3、主动决策服务
RTADW中事件的主动探查
支持主动决策的分析规则技术
传统数据仓库与实时数据仓库的区别
传统数据仓库 实时数据仓库
仅支持战略决策 支持战略决策和战术决策
数据传输是单向的 数据传输是双向的
返回高度汇总指标 返回日常运营指标
以天周月为周期获取 只包含当前明细数据,可以为分钟为获取
数据,并做预先聚合计算 明细数据
中等规模用户 多用户并发
高度限制的报表,适合 灵活的即席查询、数据挖掘
预处理的聚合或数据集市
高级用户、分析员和内部用户 操作员,外部用户
参考资料
数据仓库 (第四版) W.H.Inmon
数据仓库生命周期工具箱(第二版) Ralph Kimball
DW2.0 下一代数据仓库的架构 W.H.Inmon Derek Strauss Genia Neushloss
数据挖掘 概念与技术 Jiawei Han Micheline Kamber
W.H.Inmon http://www.inmoncif.com/home/
Ralph Kimball http://www.kimballgroup.com/
数据仓库之路 http://www.dwway.com/
中国商业智能网 http://www.chinabi.net/
加州理工学院公开课:机器学习与数据挖掘
http://v.163.com/special/opencourse/learningfromdata.html