应用机器学习分类算法的五个步骤
- 选择特征
- 选择一个性能指标
- 选择一个分类器和一个优化算法
- 评价模型的性能
- 优化算法
选择 scikit-learn
构建一个基于scikit-learn 的 perceptron
读取数据 - iris
分配训练集和测试集
标准化特征值
训练感知器模型
用训练好的模型进行预测
计算性能指标
描绘分类界面
# encoding:utf-8
__author__ = 'Matter'
# 读取数据
from sklearn import datasets
import numpy as np
iris = datasets.load_iris()
X = iris.data[:,[2,3]]
y = iris.target
# 训练数据和测试数据分为7:3
from sklearn.cross_validation import train_test_split
x_train,x_test,y_train,y_test =train_test_split(X,y,test_size=0.3,random_state=0)
# 标准化数据
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(x_train)
x_train_std = sc.transform(x_train)
x_test_std = sc.transform(x_test)
# 引入sklearn的Perceptron并进行训练
from sklearn.linear_model import Perceptron
ppn = Perceptron(n_iter=40,eta0=0.01,random_state=0)
ppn.fit(x_train_std,y_train)
y_pred = ppn.predict(x_test_std)
print('错误分类数: %d' % (y_test != y_pred).sum())
# 错误分类数:4
from sklearn.metrics import accuracy_score
print('准确率: %.2f' % accuracy_score(y_test, y_pred))
# 准确率: 0.91
# 绘制决策边界
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
import warnings
def versiontuple(v):
return tuple(map(int, (v.split("."))))
def plot_decision_regions(X,y,classifier,test_idx=None,resolution=0.02):
# 设置标记点和颜色
markers = ('s','x','o','^','v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# 绘制决策面
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
# 高粱所有的数据点
if test_idx:
# 绘制所有数据点
if not versiontuple(np.__version__) >= versiontuple('1.9.0'):
X_test, y_test = X[list(test_idx), :], y[list(test_idx)]
warnings.warn('Please update to NumPy 1.9.0 or newer')
else:
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0], X_test[:, 1], c='',
alpha=1.0, linewidth=1, marker='o',
s=55, label='test set')
def plot_result():
X_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X=X_combined_std, y=y_combined,
classifier=ppn, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
plot_result()
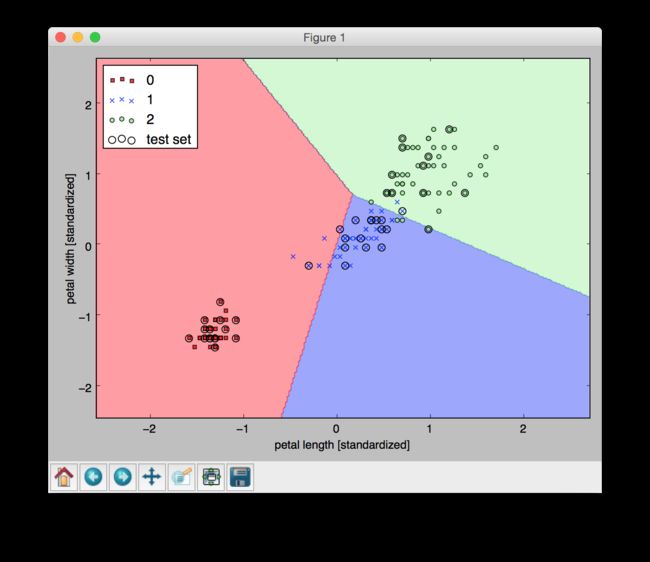
绘制决策边界