《信息与编码》考试复习笔记2----第二章离散信息源
系列文章链接目录
一、《信息与编码》考试复习笔记1----第一章概论
二、《信息与编码》考试复习笔记2----第二章离散信息源
文章目录
- 系列文章链接目录
- 前言
- 一、基本概念
- 二、离散信源熵的基本概念和性质
-
- 2.1单符号离散信源数学模型
- 2.2自信息量
-
- 2.2.1自信息量的定义
- 2.2.2联合自信息量
- 2.2.3条件自信息量
- 2.2.4自信息量、条件自信息量和联合自信息量之间的关系
- 三、信源熵及其性质
-
- 3.1信源熵的定义
-
- 3.1.1信源熵的三种物理含义
- 3.1.2条件熵
- 3.1.3联合熵
- 3.2信息熵的基本性质和定理
- 3.3多符号离散平稳信源熵
-
- 3.3.1多符号离散平稳信源
- 3.3.2离散平稳无记忆信源熵
- 3.3.3离散平稳无记忆信源熵例题及解答
- 3.3.4离散平稳有记忆信源
- 3.3.5离散平稳有记忆信源的极限熵
- 3.3.6马尔可夫信源
- 四、相关例题
- 总结
前言
这门课复习的时候有点学不进去,打算以此记录复习过程,也算加深一下印象,与大家一起学习。
本章的复习重点主要在离散信源熵的含义与相关的计算。
一、基本概念
信源的统计特性:
⮚ 信源是产生消息(符号)的来源。
⮚ 从数学上看,由于消息的不确定性,因此,信源是产生随机变量、随机序列和随机过程的源。
⮚ 信源的统计特性指客观信源具有随机不确定性。
信源的分类讨论:
⮚ 首先讨论单符号离散信源。它是最简单的信源,是组成实际信源的最基本单元。
⮚ 其次讨论实际信源。实际的离散信源发送的是一组符号串,即多符号离散信源 ;对连续信源则是一随机过程(连续信源) 。
二、离散信源熵的基本概念和性质
2.1单符号离散信源数学模型
单符号离散信源的数学模型就是离散型的概率空间:


X代表随机变量,指的是信源整体。
xi代表随机事件的某一结果或信源的某个元素
p(xi)=P(X=xi),表示随机事件X发生某一结果xi的概率。
n是有限正整数或可无限大。
2.2自信息量
2.2.1自信息量的定义
一个随机事件发生某一结果后所带来的信息量称为自信息量。

值得强调的一点是,自信息量的单位与所用对数有关。常用的对数底为2,信息量的单位为比特(bit)。自然对数e对应的信息量单位为奈特(nat)。以10位对数底对应的信息量单位为笛特(Det)或哈特(Hart)。这三个信息量单位之间的转换如下:

2.2.2联合自信息量

2.2.3条件自信息量

2.2.4自信息量、条件自信息量和联合自信息量之间的关系

三、信源熵及其性质
3.1信源熵的定义
我们定义信源各个离散消息的自信息量的数学期望为信源的平均信息量,一般称为信源的信息熵,也叫信源熵或香农熵。

信息熵的单位:一般以2为底,单位为比特/符号(bit/symbol)。
信息熵的意义:信源的信息熵H是从整个信源的统计特性来考虑的。它是从平均意义上来表征信源的总体特性的。对于某特定的信源,不同的信源因统计特性不同,其熵也不同。
3.1.1信源熵的三种物理含义
信源熵有以下三种物理含义:
⮚信源熵H(X)是表示信源输出后每个消息/符号所提供的平均信息量;
⮚信源熵H(X)是表示信源输出前,信源的平均不确定性;
⮚用信源熵H(X)来表征变量X的随机性(如下例)

3.1.2条件熵

3.1.3联合熵

3.2信息熵的基本性质和定理
共有八个:(1) 非负性(2) 对称性(3) 最大离散熵定理(4) 扩展性(5) 确定性(6) 可加性(7) 极值性(8) 上凸性。具体解释如下:
(1) 非负性:H(X)≥0。
(2) 对称性:
当变量p(x1),p(x2),…,p(xn) 的顺序任意互换时,熵函数的值不变,即![]()
该性质说明熵只与随机变量的总体结构有关,与信源的总体统计特性有关。如果某些信源的统计特性相同(含有的符号数和概率分布相同),那么这些信源的熵就相同。
(3) 最大离散熵定理:
该定理可以说明一个重要结论:
当信源X中各个离散消息以等概率出现时,可得到最大信源熵:Hmax(X)=log2n
(4) 扩展性:
本性质说明,信源的取值增多时,若这些取值对应的概率很小(接近于零),则信源的熵不变。
虽然概率很小的事件出现后,给予收信者较多的信息。但从总体来考虑时,因为这种概率很小的事件几乎不会出现,所以它在熵的计算中占的比重很小。这也是熵的总体平均性的一种体现。
(5) 确定性:意味着只要有一个p(ai)是1,则熵函数一定是0。也就是说这是一个确知信源,不确定性为0.
(6) 可加性: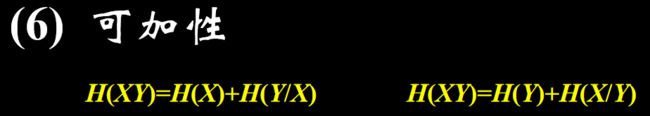
(7) 极值性:任一概率分布p(xi),它对其它概率分布p(yi)的自信息:![]() 取数学期望时,必大于p(xi)本身的熵。
取数学期望时,必大于p(xi)本身的熵。
(8) 上凸性:

3.3多符号离散平稳信源熵
实际的信源输出的消息是时间或空间上离散的一系列随机变量。这类信源每次输出的不是一个单个的符号,而是一个符号序列。在信源输出的序列中,每一位出现哪个符号都是随机的,而且一般前后符号的出现是有统计依赖关系的。这种信源称为多符号离散信源。多符号离散信源可用随机矢量/随机变量序列描述,即 X=X1,X2,X3,…
3.3.1多符号离散平稳信源
为了便于研究,假定随机矢量X中随机变量的各维联合概率分布均不随时间的推移变化。或者说,信源所发符号序列的概率分布与时间的起点无关,这种信源称为多符号离散平稳信源。
3.3.2离散平稳无记忆信源熵
为了方便,假定随机变量序列的长度是有限的,如果信源输出的消息序列中符号之间是无相互依赖关系/统计独立,则称这类信源为离散平稳无记忆信源/离散平稳无记忆信源的扩展。
离散平稳无记忆信源的数学模型:
根据信息熵的定义,N次扩展信源的熵:
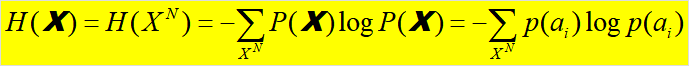
可以证明:离散无记忆信源X的N次扩展信源的熵等于离散信源X的熵的N倍,即:

3.3.3离散平稳无记忆信源熵例题及解答


3.3.4离散平稳有记忆信源


3.3.5离散平稳有记忆信源的极限熵

3.3.6马尔可夫信源
定义:马尔可夫信源,输出的符号序列中符号之间的依赖关系是有限的,即任何时刻信源符号发生的概率只与前面已经发出的若干个符号有关,而与更前面发出的符号无关。
四、相关例题
这里还涉及到后面几个章节的知识点,即第四问和第五问。
