Pandas 秘籍
原文:Pandas Cookbook
译者:飞龙
协议:CC BY-NC-SA 4.0
第一章
import pandas as pd
pd.set_option('display.mpl_style', 'default') # 使图表漂亮一些
figsize(15, 5)
1.1 从 CSV 文件中读取数据
您可以使用read_csv函数从CSV文件读取数据。 默认情况下,它假定字段以逗号分隔。
我们将从蒙特利尔(Montréal)寻找一些骑自行车的数据。 这是原始页面(法语),但它已经包含在此仓库中。 我们使用的是 2012 年的数据。
这个数据集是一个列表,蒙特利尔的 7 个不同的自行车道上每天有多少人。
broken_df = pd.read_csv('../data/bikes.csv')
In [3]:
# 查看前三行
broken_df[:3]
| Date;Berri 1;Br?beuf (donn?es non disponibles);C?te-Sainte-Catherine;Maisonneuve 1;Maisonneuve 2;du Parc;Pierre-Dupuy;Rachel1;St-Urbain (donn?es non disponibles) | |
|---|---|
| 0 | 01/01/2012;35;;0;38;51;26;10;16; |
| 1 | 02/01/2012;83;;1;68;153;53;6;43; |
| 2 | 03/01/2012;135;;2;104;248;89;3;58; |
你可以看到这完全损坏了。read_csv拥有一堆选项能够让我们修复它,在这里我们:
- 将列分隔符改成
; - 将编码改为
latin1(默认为utf-8) - 解析
Date列中的日期 - 告诉它我们的日期将日放在前面,而不是月
- 将索引设置为
Date
fixed_df = pd.read_csv('../data/bikes.csv', sep=';', encoding='latin1', parse_dates=['Date'], dayfirst=True, index_col='Date')
fixed_df[:3]
| Berri 1 | Brébeuf (données non disponibles) | C?te-Sainte-Catherine | Maisonneuve 1 | Maisonneuve 2 | du Parc | Pierre-Dupuy | Rachel1 | St-Urbain (données non disponibles) | |
|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||
| 2012-01-01 | 35 | NaN | 0 | 38 | 51 | 26 | 10 | 16 | NaN |
| 2012-01-02 | 83 | NaN | 1 | 68 | 153 | 53 | 6 | 43 | NaN |
| 2012-01-03 | 135 | NaN | 2 | 104 | 248 | 89 | 3 | 58 | NaN |
1.2 选择一列
当你读取 CSV 时,你会得到一种称为DataFrame的对象,它由行和列组成。 您从数据框架中获取列的方式与从字典中获取元素的方式相同。
这里有一个例子:
fixed_df['Berri 1']
Date
2012-01-01 35
2012-01-02 83
2012-01-03 135
2012-01-04 144
2012-01-05 197
2012-01-06 146
2012-01-07 98
2012-01-08 95
2012-01-09 244
2012-01-10 397
2012-01-11 273
2012-01-12 157
2012-01-13 75
2012-01-14 32
2012-01-15 54
...
2012-10-22 3650
2012-10-23 4177
2012-10-24 3744
2012-10-25 3735
2012-10-26 4290
2012-10-27 1857
2012-10-28 1310
2012-10-29 2919
2012-10-30 2887
2012-10-31 2634
2012-11-01 2405
2012-11-02 1582
2012-11-03 844
2012-11-04 966
2012-11-05 2247
Name: Berri 1, Length: 310, dtype: int64
1.3 绘制一列
只需要在末尾添加.plot(),再容易不过了。
我们可以看到,没有什么意外,一月、二月和三月没有什么人骑自行车。
fixed_df['Berri 1'].plot()
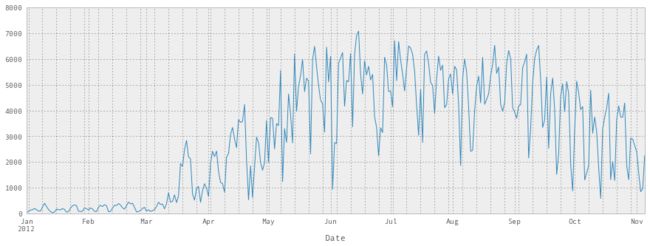
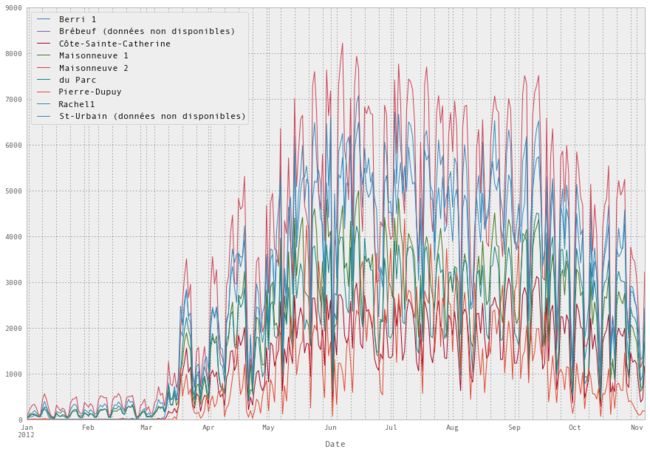
我们也可以很容易地绘制所有的列。 我们会让它更大一点。 你可以看到它挤在一起,但所有的自行车道基本表现相同 - 如果对骑自行车的人来说是一个糟糕的一天,任意地方都是糟糕的一天。
fixed_df.plot(figsize=(15, 10))
1.4 将它们放到一起
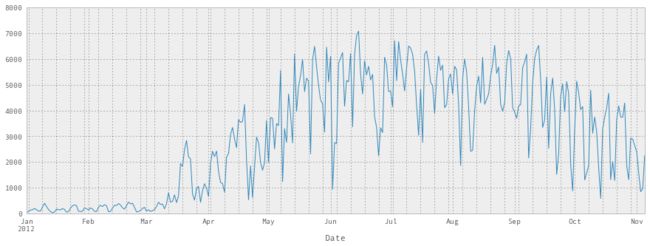
下面是我们的所有代码,我们编写它来绘制图表:
df = pd.read_csv('../data/bikes.csv', sep=';', encoding='latin1', parse_dates=['Date'], dayfirst=True, index_col='Date')
df['Berri 1'].plot()
第二章
# 通常的开头
import pandas as pd
# 使图表更大更漂亮
pd.set_option('display.mpl_style', 'default')
pd.set_option('display.line_width', 5000)
pd.set_option('display.max_columns', 60)
figsize(15, 5)
我们将在这里使用一个新的数据集,来演示如何处理更大的数据集。 这是来自 NYC Open Data 的 311 个服务请求的子集。
complaints = pd.read_csv('../data/311-service-requests.csv')
2.1 里面究竟有什么?(总结)
当你查看一个大型数据框架,而不是显示数据框架的内容,它会显示一个摘要。 这包括所有列,以及每列中有多少非空值。
complaints
Int64Index: 111069 entries, 0 to 111068
Data columns (total 52 columns):
Unique Key 111069 non-null values
Created Date 111069 non-null values
Closed Date 60270 non-null values
Agency 111069 non-null values
Agency Name 111069 non-null values
Complaint Type 111069 non-null values
Descriptor 111068 non-null values
Location Type 79048 non-null values
Incident Zip 98813 non-null values
Incident Address 84441 non-null values
Street Name 84438 non-null values
Cross Street 1 84728 non-null values
Cross Street 2 84005 non-null values
Intersection Street 1 19364 non-null values
Intersection Street 2 19366 non-null values
Address Type 102247 non-null values
City 98860 non-null values
Landmark 95 non-null values
Facility Type 110938 non-null values
Status 111069 non-null values
Due Date 39239 non-null values
Resolution Action Updated Date 96507 non-null values
Community Board 111069 non-null values
Borough 111069 non-null values
X Coordinate (State Plane) 98143 non-null values
Y Coordinate (State Plane) 98143 non-null values
Park Facility Name 111069 non-null values
Park Borough 111069 non-null values
School Name 111069 non-null values
School Number 111052 non-null values
School Region 110524 non-null values
School Code 110524 non-null values
School Phone Number 111069 non-null values
School Address 111069 non-null values
School City 111069 non-null values
School State 111069 non-null values
School Zip 111069 non-null values
School Not Found 38984 non-null values
School or Citywide Complaint 0 non-null values
Vehicle Type 99 non-null values
Taxi Company Borough 117 non-null values
Taxi Pick Up Location 1059 non-null values
Bridge Highway Name 185 non-null values
Bridge Highway Direction 185 non-null values
Road Ramp 184 non-null values
Bridge Highway Segment 223 non-null values
Garage Lot Name 49 non-null values
Ferry Direction 37 non-null values
Ferry Terminal Name 336 non-null values
Latitude 98143 non-null values
Longitude 98143 non-null values
Location 98143 non-null values
dtypes: float64(5), int64(1), object(46)
2.2 选择列和行
为了选择一列,使用列名称作为索引,像这样:
complaints['Complaint Type']
0 Noise - Street/Sidewalk
1 Illegal Parking
2 Noise - Commercial
3 Noise - Vehicle
4 Rodent
5 Noise - Commercial
6 Blocked Driveway
7 Noise - Commercial
8 Noise - Commercial
9 Noise - Commercial
10 Noise - House of Worship
11 Noise - Commercial
12 Illegal Parking
13 Noise - Vehicle
14 Rodent
...
111054 Noise - Street/Sidewalk
111055 Noise - Commercial
111056 Street Sign - Missing
111057 Noise
111058 Noise - Commercial
111059 Noise - Street/Sidewalk
111060 Noise
111061 Noise - Commercial
111062 Water System
111063 Water System
111064 Maintenance or Facility
111065 Illegal Parking
111066 Noise - Street/Sidewalk
111067 Noise - Commercial
111068 Blocked Driveway
Name: Complaint Type, Length: 111069, dtype: object
要获得DataFrame的前 5 行,我们可以使用切片:df [:5]。
这是一个了解数据框架中存在什么信息的很好方式 - 花一点时间来查看内容并获得此数据集的感觉。
complaints[:5]
| | Unique Key | Created Date | Closed Date | Agency | Agency Name | Complaint Type | Descriptor | Location Type | Incident Zip | Incident Address | Street Name | Cross Street 1 | Cross Street 2 | Intersection Street 1 | Intersection Street 2 | Address Type | City | Landmark | Facility Type | Status | Due Date | Resolution Action Updated Date | Community Board | Borough | X Coordinate (State Plane) | Y Coordinate (State Plane) | Park Facility Name | Park Borough | School Name | School Number | School Region | School Code | School Phone Number | School Address | School City | School State | School Zip | School Not Found | School or Citywide Complaint | Vehicle Type | Taxi Company Borough | Taxi Pick Up Location | Bridge Highway Name | Bridge Highway Direction | Road Ramp | Bridge Highway Segment | Garage Lot Name | Ferry Direction | Ferry Terminal Name | Latitude | Longitude | Location |
| --- | --- |
| 0 | 26589651 | 10/31/2013 02:08:41 AM | NaN | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Talking | Street/Sidewalk | 11432 | 90-03 169 STREET | 169 STREET | 90 AVENUE | 91 AVENUE | NaN | NaN | ADDRESS | JAMAICA | NaN | Precinct | Assigned | 10/31/2013 10:08:41 AM | 10/31/2013 02:35:17 AM | 12 QUEENS | QUEENS | 1042027 | 197389 | Unspecified | QUEENS | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.708275 | -73.791604 | (40.70827532593202, -73.79160395779721) |
| 1 | 26593698 | 10/31/2013 02:01:04 AM | NaN | NYPD | New York City Police Department | Illegal Parking | Commercial Overnight Parking | Street/Sidewalk | 11378 | 58 AVENUE | 58 AVENUE | 58 PLACE | 59 STREET | NaN | NaN | BLOCKFACE | MASPETH | NaN | Precinct | Open | 10/31/2013 10:01:04 AM | NaN | 05 QUEENS | QUEENS | 1009349 | 201984 | Unspecified | QUEENS | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.721041 | -73.909453 | (40.721040535628305, -73.90945306791765) |
| 2 | 26594139 | 10/31/2013 02:00:24 AM | 10/31/2013 02:40:32 AM | NYPD | New York City Police Department | Noise - Commercial | Loud Music/Party | Club/Bar/Restaurant | 10032 | 4060 BROADWAY | BROADWAY | WEST 171 STREET | WEST 172 STREET | NaN | NaN | ADDRESS | NEW YORK | NaN | Precinct | Closed | 10/31/2013 10:00:24 AM | 10/31/2013 02:39:42 AM | 12 MANHATTAN | MANHATTAN | 1001088 | 246531 | Unspecified | MANHATTAN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.843330 | -73.939144 | (40.84332975466513, -73.93914371913482) |
| 3 | 26595721 | 10/31/2013 01:56:23 AM | 10/31/2013 02:21:48 AM | NYPD | New York City Police Department | Noise - Vehicle | Car/Truck Horn | Street/Sidewalk | 10023 | WEST 72 STREET | WEST 72 STREET | COLUMBUS AVENUE | AMSTERDAM AVENUE | NaN | NaN | BLOCKFACE | NEW YORK | NaN | Precinct | Closed | 10/31/2013 09:56:23 AM | 10/31/2013 02:21:10 AM | 07 MANHATTAN | MANHATTAN | 989730 | 222727 | Unspecified | MANHATTAN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.778009 | -73.980213 | (40.7780087446372, -73.98021349023975) |
| 4 | 26590930 | 10/31/2013 01:53:44 AM | NaN | DOHMH | Department of Health and Mental Hygiene | Rodent | Condition Attracting Rodents | Vacant Lot | 10027 | WEST 124 STREET | WEST 124 STREET | LENOX AVENUE | ADAM CLAYTON POWELL JR BOULEVARD | NaN | NaN | BLOCKFACE | NEW YORK | NaN | N/A | Pending | 11/30/2013 01:53:44 AM | 10/31/2013 01:59:54 AM | 10 MANHATTAN | MANHATTAN | 998815 | 233545 | Unspecified | MANHATTAN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.807691 | -73.947387 | (40.80769092704951, |
我们可以组合它们来获得一列的前五行。
complaints['Complaint Type'][:5]
0 Noise - Street/Sidewalk
1 Illegal Parking
2 Noise - Commercial
3 Noise - Vehicle
4 Rodent
Name: Complaint Type, dtype: object
并且无论我们以什么方向:
complaints[:5]['Complaint Type']
0 Noise - Street/Sidewalk
1 Illegal Parking
2 Noise - Commercial
3 Noise - Vehicle
4 Rodent
Name: Complaint Type, dtype: object
2.3 选择多列
如果我们只关心投诉类型和区,但不关心其余的信息怎么办? Pandas 使它很容易选择列的一个子集:只需将所需列的列表用作索引。
complaints[['Complaint Type', 'Borough']]
Int64Index: 111069 entries, 0 to 111068
Data columns (total 2 columns):
Complaint Type 111069 non-null values
Borough 111069 non-null values
dtypes: object(2)
这会向我们展示总结,我们可以获取前 10 列:
complaints[['Complaint Type', 'Borough']][:10]
| Complaint Type | Borough | |
|---|---|---|
| 0 | Noise - Street/Sidewalk | QUEENS |
| 1 | Illegal Parking | QUEENS |
| 2 | Noise - Commercial | MANHATTAN |
| 3 | Noise - Vehicle | MANHATTAN |
| 4 | Rodent | MANHATTAN |
| 5 | Noise - Commercial | QUEENS |
| 6 | Blocked Driveway | QUEENS |
| 7 | Noise - Commercial | QUEENS |
| 8 | Noise - Commercial | MANHATTAN |
| 9 | Noise - Commercial | BROOKLYN |
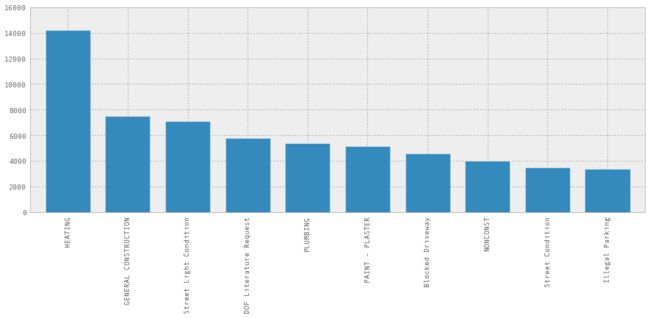
2.4 什么是最常见的投诉类型?
这是个易于回答的问题,我们可以调用.value_counts()方法:
complaints['Complaint Type'].value_counts()
HEATING 14200
GENERAL CONSTRUCTION 7471
Street Light Condition 7117
DOF Literature Request 5797
PLUMBING 5373
PAINT - PLASTER 5149
Blocked Driveway 4590
NONCONST 3998
Street Condition 3473
Illegal Parking 3343
Noise 3321
Traffic Signal Condition 3145
Dirty Conditions 2653
Water System 2636
Noise - Commercial 2578
...
Opinion for the Mayor 2
Window Guard 2
DFTA Literature Request 2
Legal Services Provider Complaint 2
Open Flame Permit 1
Snow 1
Municipal Parking Facility 1
X-Ray Machine/Equipment 1
Stalled Sites 1
DHS Income Savings Requirement 1
Tunnel Condition 1
Highway Sign - Damaged 1
Ferry Permit 1
Trans Fat 1
DWD 1
Length: 165, dtype: int64
如果我们想要最常见的 10 个投诉类型,我们可以这样:
complaint_counts = complaints['Complaint Type'].value_counts()
complaint_counts[:10]
HEATING 14200
GENERAL CONSTRUCTION 7471
Street Light Condition 7117
DOF Literature Request 5797
PLUMBING 5373
PAINT - PLASTER 5149
Blocked Driveway 4590
NONCONST 3998
Street Condition 3473
Illegal Parking 3343
dtype: int64
但是还可以更好,我们可以绘制出来!
complaint_counts[:10].plot(kind='bar')
第三章
# 通常的开头
import pandas as pd
# 使图表更大更漂亮
pd.set_option('display.mpl_style', 'default')
figsize(15, 5)
# 始终展示所有列
pd.set_option('display.line_width', 5000)
pd.set_option('display.max_columns', 60)
让我们继续 NYC 311 服务请求的例子。
complaints = pd.read_csv('../data/311-service-requests.csv')
3.1 仅仅选择噪音投诉
我想知道哪个区有最多的噪音投诉。 首先,我们来看看数据,看看它是什么样子:
complaints[:5]
| | Unique Key | Created Date | Closed Date | Agency | Agency Name | Complaint Type | Descriptor | Location Type | Incident Zip | Incident Address | Street Name | Cross Street 1 | Cross Street 2 | Intersection Street 1 | Intersection Street 2 | Address Type | City | Landmark | Facility Type | Status | Due Date | Resolution Action Updated Date | Community Board | Borough | X Coordinate (State Plane) | Y Coordinate (State Plane) | Park Facility Name | Park Borough | School Name | School Number | School Region | School Code | School Phone Number | School Address | School City | School State | School Zip | School Not Found | School or Citywide Complaint | Vehicle Type | Taxi Company Borough | Taxi Pick Up Location | Bridge Highway Name | Bridge Highway Direction | Road Ramp | Bridge Highway Segment | Garage Lot Name | Ferry Direction | Ferry Terminal Name | Latitude | Longitude | Location |
| --- | --- |
| 0 | 26589651 | 10/31/2013 02:08:41 AM | NaN | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Talking | Street/Sidewalk | 11432 | 90-03 169 STREET | 169 STREET | 90 AVENUE | 91 AVENUE | NaN | NaN | ADDRESS | JAMAICA | NaN | Precinct | Assigned | 10/31/2013 10:08:41 AM | 10/31/2013 02:35:17 AM | 12 QUEENS | QUEENS | 1042027 | 197389 | Unspecified | QUEENS | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.708275 | -73.791604 | (40.70827532593202, -73.79160395779721) |
| 1 | 26593698 | 10/31/2013 02:01:04 AM | NaN | NYPD | New York City Police Department | Illegal Parking | Commercial Overnight Parking | Street/Sidewalk | 11378 | 58 AVENUE | 58 AVENUE | 58 PLACE | 59 STREET | NaN | NaN | BLOCKFACE | MASPETH | NaN | Precinct | Open | 10/31/2013 10:01:04 AM | NaN | 05 QUEENS | QUEENS | 1009349 | 201984 | Unspecified | QUEENS | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.721041 | -73.909453 | (40.721040535628305, -73.90945306791765) |
| 2 | 26594139 | 10/31/2013 02:00:24 AM | 10/31/2013 02:40:32 AM | NYPD | New York City Police Department | Noise - Commercial | Loud Music/Party | Club/Bar/Restaurant | 10032 | 4060 BROADWAY | BROADWAY | WEST 171 STREET | WEST 172 STREET | NaN | NaN | ADDRESS | NEW YORK | NaN | Precinct | Closed | 10/31/2013 10:00:24 AM | 10/31/2013 02:39:42 AM | 12 MANHATTAN | MANHATTAN | 1001088 | 246531 | Unspecified | MANHATTAN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.843330 | -73.939144 | (40.84332975466513, -73.93914371913482) |
| 3 | 26595721 | 10/31/2013 01:56:23 AM | 10/31/2013 02:21:48 AM | NYPD | New York City Police Department | Noise - Vehicle | Car/Truck Horn | Street/Sidewalk | 10023 | WEST 72 STREET | WEST 72 STREET | COLUMBUS AVENUE | AMSTERDAM AVENUE | NaN | NaN | BLOCKFACE | NEW YORK | NaN | Precinct | Closed | 10/31/2013 09:56:23 AM | 10/31/2013 02:21:10 AM | 07 MANHATTAN | MANHATTAN | 989730 | 222727 | Unspecified | MANHATTAN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.778009 | -73.980213 | (40.7780087446372, -73.98021349023975) |
| 4 | 26590930 | 10/31/2013 01:53:44 AM | NaN | DOHMH | Department of Health and Mental Hygiene | Rodent | Condition Attracting Rodents | Vacant Lot | 10027 | WEST 124 STREET | WEST 124 STREET | LENOX AVENUE | ADAM CLAYTON POWELL JR BOULEVARD | NaN | NaN | BLOCKFACE | NEW YORK | NaN | N/A | Pending | 11/30/2013 01:53:44 AM | 10/31/2013 01:59:54 AM | 10 MANHATTAN | MANHATTAN | 998815 | 233545 | Unspecified | MANHATTAN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.807691 | -73.947387 | (40.80769092704951, -73.94738703491433) |
为了得到噪音投诉,我们需要找到Complaint Type列为Noise - Street/Sidewalk的行。 我会告诉你如何做,然后解释发生了什么。
noise_complaints = complaints[complaints['Complaint Type'] == "Noise - Street/Sidewalk"]
noise_complaints[:3]
| | Unique Key | Created Date | Closed Date | Agency | Agency Name | Complaint Type | Descriptor | Location Type | Incident Zip | Incident Address | Street Name | Cross Street 1 | Cross Street 2 | Intersection Street 1 | Intersection Street 2 | Address Type | City | Landmark | Facility Type | Status | Due Date | Resolution Action Updated Date | Community Board | Borough | X Coordinate (State Plane) | Y Coordinate (State Plane) | Park Facility Name | Park Borough | School Name | School Number | School Region | School Code | School Phone Number | School Address | School City | School State | School Zip | School Not Found | School or Citywide Complaint | Vehicle Type | Taxi Company Borough | Taxi Pick Up Location | Bridge Highway Name | Bridge Highway Direction | Road Ramp | Bridge Highway Segment | Garage Lot Name | Ferry Direction | Ferry Terminal Name | Latitude | Longitude | Location |
| --- | --- |
| 0 | 26589651 | 10/31/2013 02:08:41 AM | NaN | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Talking | Street/Sidewalk | 11432 | 90-03 169 STREET | 169 STREET | 90 AVENUE | 91 AVENUE | NaN | NaN | ADDRESS | JAMAICA | NaN | Precinct | Assigned | 10/31/2013 10:08:41 AM | 10/31/2013 02:35:17 AM | 12 QUEENS | QUEENS | 1042027 | 197389 | Unspecified | QUEENS | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.708275 | -73.791604 | (40.70827532593202, -73.79160395779721) |
| 16 | 26594086 | 10/31/2013 12:54:03 AM | 10/31/2013 02:16:39 AM | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Music/Party | Street/Sidewalk | 10310 | 173 CAMPBELL AVENUE | CAMPBELL AVENUE | HENDERSON AVENUE | WINEGAR LANE | NaN | NaN | ADDRESS | STATEN ISLAND | NaN | Precinct | Closed | 10/31/2013 08:54:03 AM | 10/31/2013 02:07:14 AM | 01 STATEN ISLAND | STATEN ISLAND | 952013 | 171076 | Unspecified | STATEN ISLAND | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.636182 | -74.116150 | (40.63618202176914, -74.1161500428337) |
| 25 | 26591573 | 10/31/2013 12:35:18 AM | 10/31/2013 02:41:35 AM | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Talking | Street/Sidewalk | 10312 | 24 PRINCETON LANE | PRINCETON LANE | HAMPTON GREEN | DEAD END | NaN | NaN | ADDRESS | STATEN ISLAND | NaN | Precinct | Closed | 10/31/2013 08:35:18 AM | 10/31/2013 01:45:17 AM | 03 STATEN ISLAND | STATEN ISLAND | 929577 | 140964 | Unspecified | STATEN ISLAND | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.553421 | -74.196743 | (40.55342078716953, -74.19674315017886) |
如果你查看noise_complaints,你会看到它生效了,它只包含带有正确的投诉类型的投诉。 但是这是如何工作的? 让我们把它解构成两部分
complaints['Complaint Type'] == "Noise - Street/Sidewalk"
0 True
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 False
12 False
13 False
14 False
...
111054 True
111055 False
111056 False
111057 False
111058 False
111059 True
111060 False
111061 False
111062 False
111063 False
111064 False
111065 False
111066 True
111067 False
111068 False
Name: Complaint Type, Length: 111069, dtype: bool
这是一个True和False的大数组,对应DataFrame中的每一行。 当我们用这个数组索引我们的DataFrame时,我们只得到其中为True行。
您还可以将多个条件与&运算符组合,如下所示:
is_noise = complaints['Complaint Type'] == "Noise - Street/Sidewalk"
in_brooklyn = complaints['Borough'] == "BROOKLYN"
complaints[is_noise & in_brooklyn][:5]
| | Unique Key | Created Date | Closed Date | Agency | Agency Name | Complaint Type | Descriptor | Location Type | Incident Zip | Incident Address | Street Name | Cross Street 1 | Cross Street 2 | Intersection Street 1 | Intersection Street 2 | Address Type | City | Landmark | Facility Type | Status | Due Date | Resolution Action Updated Date | Community Board | Borough | X Coordinate (State Plane) | Y Coordinate (State Plane) | Park Facility Name | Park Borough | School Name | School Number | School Region | School Code | School Phone Number | School Address | School City | School State | School Zip | School Not Found | School or Citywide Complaint | Vehicle Type | Taxi Company Borough | Taxi Pick Up Location | Bridge Highway Name | Bridge Highway Direction | Road Ramp | Bridge Highway Segment | Garage Lot Name | Ferry Direction | Ferry Terminal Name | Latitude | Longitude | Location |
| --- | --- |
| 31 | 26595564 | 10/31/2013 12:30:36 AM | NaN | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Music/Party | Street/Sidewalk | 11236 | AVENUE J | AVENUE J | EAST 80 STREET | EAST 81 STREET | NaN | NaN | BLOCKFACE | BROOKLYN | NaN | Precinct | Open | 10/31/2013 08:30:36 AM | NaN | 18 BROOKLYN | BROOKLYN | 1008937 | 170310 | Unspecified | BROOKLYN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.634104 | -73.911055 | (40.634103775951736, -73.91105541883589) |
| 49 | 26595553 | 10/31/2013 12:05:10 AM | 10/31/2013 02:43:43 AM | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Talking | Street/Sidewalk | 11225 | 25 LEFFERTS AVENUE | LEFFERTS AVENUE | WASHINGTON AVENUE | BEDFORD AVENUE | NaN | NaN | ADDRESS | BROOKLYN | NaN | Precinct | Closed | 10/31/2013 08:05:10 AM | 10/31/2013 01:29:29 AM | 09 BROOKLYN | BROOKLYN | 995366 | 180388 | Unspecified | BROOKLYN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.661793 | -73.959934 | (40.6617931276793, -73.95993363978067) |
| 109 | 26594653 | 10/30/2013 11:26:32 PM | 10/31/2013 12:18:54 AM | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Music/Party | Street/Sidewalk | 11222 | NaN | NaN | NaN | NaN | DOBBIN STREET | NORMAN STREET | INTERSECTION | BROOKLYN | NaN | Precinct | Closed | 10/31/2013 07:26:32 AM | 10/31/2013 12:18:54 AM | 01 BROOKLYN | BROOKLYN | 996925 | 203271 | Unspecified | BROOKLYN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.724600 | -73.954271 | (40.724599563793525, -73.95427134534344) |
| 236 | 26591992 | 10/30/2013 10:02:58 PM | 10/30/2013 10:23:20 PM | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Talking | Street/Sidewalk | 11218 | DITMAS AVENUE | DITMAS AVENUE | NaN | NaN | NaN | NaN | LATLONG | BROOKLYN | NaN | Precinct | Closed | 10/31/2013 06:02:58 AM | 10/30/2013 10:23:20 PM | 01 BROOKLYN | BROOKLYN | 991895 | 171051 | Unspecified | BROOKLYN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.636169 | -73.972455 | (40.63616876563881, -73.97245504682485) |
| 370 | 26594167 | 10/30/2013 08:38:25 PM | 10/30/2013 10:26:28 PM | NYPD | New York City Police Department | Noise - Street/Sidewalk | Loud Music/Party | Street/Sidewalk | 11218 | 126 BEVERLY ROAD | BEVERLY ROAD | CHURCH AVENUE | EAST 2 STREET | NaN | NaN | ADDRESS | BROOKLYN | NaN | Precinct | Closed | 10/31/2013 04:38:25 AM | 10/30/2013 10:26:28 PM | 12 BROOKLYN | BROOKLYN | 990144 | 173511 | Unspecified | BROOKLYN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 40.642922 | -73.978762 | (40.6429222774404, -73.97876175474585) |
或者如果我们只需要几列:
complaints[is_noise & in_brooklyn][['Complaint Type', 'Borough', 'Created Date', 'Descriptor']][:10]
| | Complaint Type | Borough | Created Date | Descriptor |
| --- | --- |
| 31 | Noise - Street/Sidewalk | BROOKLYN | 10/31/2013 12:30:36 AM | Loud Music/Party |
| 49 | Noise - Street/Sidewalk | BROOKLYN | 10/31/2013 12:05:10 AM | Loud Talking |
| 109 | Noise - Street/Sidewalk | BROOKLYN | 10/30/2013 11:26:32 PM | Loud Music/Party |
| 236 | Noise - Street/Sidewalk | BROOKLYN | 10/30/2013 10:02:58 PM | Loud Talking |
| 370 | Noise - Street/Sidewalk | BROOKLYN | 10/30/2013 08:38:25 PM | Loud Music/Party |
| 378 | Noise - Street/Sidewalk | BROOKLYN | 10/30/2013 08:32:13 PM | Loud Talking |
| 656 | Noise - Street/Sidewalk | BROOKLYN | 10/30/2013 06:07:39 PM | Loud Music/Party |
| 1251 | Noise - Street/Sidewalk | BROOKLYN | 10/30/2013 03:04:51 PM | Loud Talking |
| 5416 | Noise - Street/Sidewalk | BROOKLYN | 10/29/2013 10:07:02 PM | Loud Talking |
| 5584 | Noise - Street/Sidewalk | BROOKLYN | 10/29/2013 08:15:59 PM | Loud Music/Party |
3.2 numpy 数组的注解
在内部,列的类型是pd.Series。
pd.Series([1,2,3])
0 1
1 2
2 3
dtype: int64
而且pandas.Series的内部是 numpy 数组。 如果将.values添加到任何Series的末尾,你将得到它的内部 numpy 数组。
np.array([1,2,3])
array([1, 2, 3])
pd.Series([1,2,3]).values
array([1, 2, 3])
所以这个二进制数组选择的操作,实际上适用于任何 NumPy 数组:
arr = np.array([1,2,3])
arr != 2
array([ True, False, True], dtype=bool)
arr[arr != 2]
array([1, 3])
3.3 所以,哪个区的噪音投诉最多?
is_noise = complaints['Complaint Type'] == "Noise - Street/Sidewalk"
noise_complaints = complaints[is_noise]
noise_complaints['Borough'].value_counts()
MANHATTAN 917
BROOKLYN 456
BRONX 292
QUEENS 226
STATEN ISLAND 36
Unspecified 1
dtype: int64
这是曼哈顿! 但是,如果我们想要除以总投诉数量,以使它有点更有意义? 这也很容易:
noise_complaint_counts = noise_complaints['Borough'].value_counts()
complaint_counts = complaints['Borough'].value_counts()
noise_complaint_counts / complaint_counts
BRONX 0
BROOKLYN 0
MANHATTAN 0
QUEENS 0
STATEN ISLAND 0
Unspecified 0
dtype: int64
糟糕,为什么是零?这是因为 Python 2 中的整数除法。让我们通过将complaints_counts转换为浮点数组来解决它。
noise_complaint_counts / complaint_counts.astype(float)
BRONX 0.014833
BROOKLYN 0.013864
MANHATTAN 0.037755
QUEENS 0.010143
STATEN ISLAND 0.007474
Unspecified 0.000141
dtype: float64
(noise_complaint_counts / complaint_counts.astype(float)).plot(kind='bar')
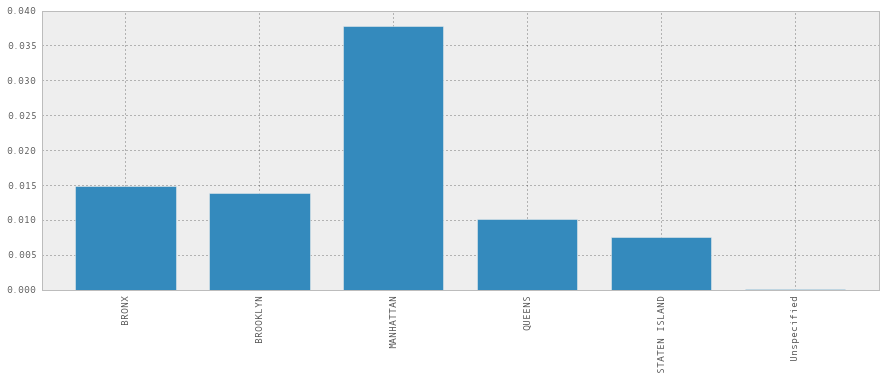
所以曼哈顿的噪音投诉比其他区要多。
第四章
import pandas as pd
pd.set_option('display.mpl_style', 'default') # 使图表漂亮一些
figsize(15, 5)
好的! 我们将在这里回顾我们的自行车道数据集。 我住在蒙特利尔,我很好奇我们是一个通勤城市,还是以骑自行车为乐趣的城市 - 人们在周末还是工作日骑自行车?
4.1 向我们的DataFrame中刚添加weekday列
首先我们需要加载数据,我们之前已经做过了。
bikes = pd.read_csv('../data/bikes.csv', sep=';', encoding='latin1', parse_dates=['Date'], dayfirst=True, index_col='Date')
bikes['Berri 1'].plot()
接下来,我们只是看看 Berri 自行车道。 Berri 是蒙特利尔的一条街道,是一个相当重要的自行车道。 现在我习惯走这条路去图书馆,但我在旧蒙特利尔工作时,我习惯于走这条路去上班。
所以我们要创建一个只有 Berri 自行车道的DataFrame。
berri_bikes = bikes[['Berri 1']]
berri_bikes[:5]
| Berri 1 | |
|---|---|
| Date | |
| 2012-01-01 | 35 |
| 2012-01-02 | 83 |
| 2012-01-03 | 135 |
| 2012-01-04 | 144 |
| 2012-01-05 | 197 |
接下来,我们需要添加一列weekday。 首先,我们可以从索引得到星期。 我们还没有谈到索引,但索引在上面的DataFrame中是左边的东西,在Date下面。 它基本上是一年中的所有日子。
berri_bikes.index
[2012-01-01 00:00:00, ..., 2012-11-05 00:00:00]
Length: 310, Freq: None, Timezone: None
你可以看到,实际上缺少一些日期 - 实际上只有一年的 310 天。 天知道为什么。
Pandas 有一堆非常棒的时间序列功能,所以如果我们想得到每一行的月份中的日期,我们可以这样做:
berri_bikes.index.day
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 1, 2, 3,
4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 1, 2, 3, 4, 5, 6, 7, 8,
9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28,
29, 30, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 1,
2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 1, 2, 3, 4, 5,
6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 29, 30, 31, 1, 2, 3, 4, 5, 6, 7, 8,
9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28,
29, 30, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 1,
2, 3, 4, 5], dtype=int32)
我们实际上想要星期:
berri_bikes.index.weekday
array([6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0,
1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2,
3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4,
5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6,
0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1,
2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3,
4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5,
6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0,
1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2,
3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4,
5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6,
0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1,
2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3,
4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0], dtype=int32)
这是周中的日期,其中 0 是星期一。我通过查询日历得到 0 是星期一。
现在我们知道了如何获取星期,我们可以将其添加到我们的DataFrame中作为一列:
berri_bikes['weekday'] = berri_bikes.index.weekday
berri_bikes[:5]
| | Berri 1 | weekday |
| --- | --- |
| Date | | |
| 2012-01-01 | 35 | 6 |
| 2012-01-02 | 83 | 0 |
| 2012-01-03 | 135 | 1 |
| 2012-01-04 | 144 | 2 |
| 2012-01-05 | 197 | 3 |
4.2 按星期统计骑手
这很易于实现!
Dataframe有一个类似于 SQLgroupby的.groupby()方法,如果你熟悉的话。 我现在不打算解释更多 - 如果你想知道更多,请见文档。
在这种情况下,berri_bikes.groupby('weekday').aggregate(sum)`意味着“按星期对行分组,然后将星期相同的所有值相加”。
weekday_counts = berri_bikes.groupby('weekday').aggregate(sum)
weekday_counts
| Berri 1 | |
|---|---|
| weekday | |
| 0 | 134298 |
| 1 | 135305 |
| 2 | 152972 |
| 3 | 160131 |
| 4 | 141771 |
| 5 | 101578 |
| 6 | 99310 |
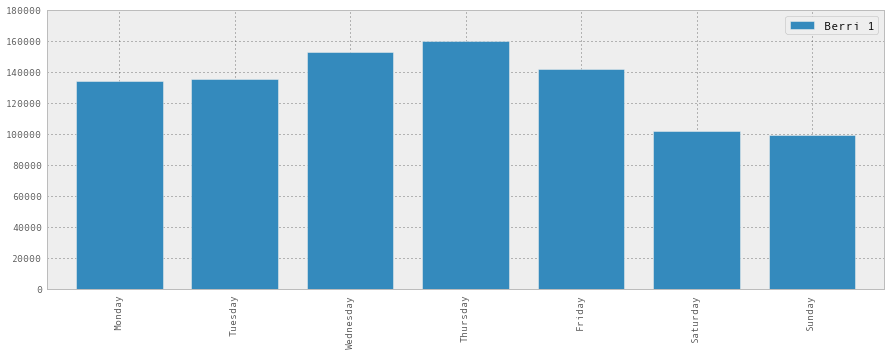
很难记住0, 1, 2, 3, 4, 5, 6是什么,所以让我们修复它并绘制出来:
weekday_counts.index = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_counts
| Berri 1 | |
|---|---|
| Monday | 134298 |
| Tuesday | 135305 |
| Wednesday | 152972 |
| Thursday | 160131 |
| Friday | 141771 |
| Saturday | 101578 |
| Sunday | 99310 |
weekday_counts.plot(kind='bar')
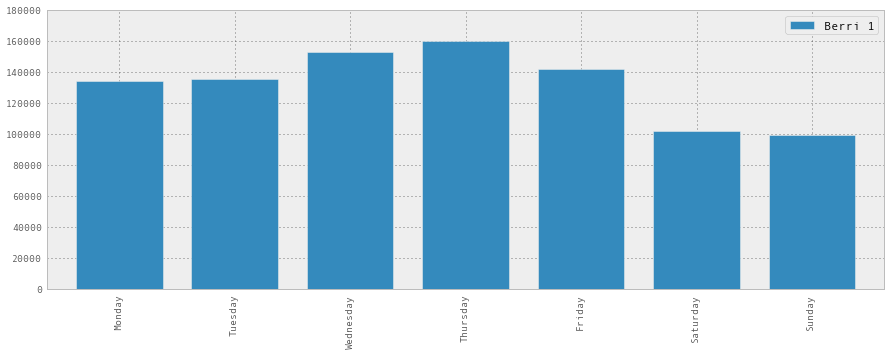
所以看起来蒙特利尔是通勤骑自行车的人 - 他们在工作日骑自行车更多。
4.3 放到一起
让我们把所有的一起,证明它是多么容易。 6 行的神奇 Pandas!
如果你想玩一玩,尝试将sum变为max,np.median,或任何你喜欢的其他函数。
bikes = pd.read_csv('../data/bikes.csv',
sep=';', encoding='latin1',
parse_dates=['Date'], dayfirst=True,
index_col='Date')
# 添加 weekday 列
berri_bikes = bikes[['Berri 1']]
berri_bikes['weekday'] = berri_bikes.index.weekday
# 按照星期累计骑手,并绘制出来
weekday_counts = berri_bikes.groupby('weekday').aggregate(sum)
weekday_counts.index = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekday_counts.plot(kind='bar')
第五章
5.1 下载一个月的天气数据
在处理自行车数据时,我需要温度和降水数据,来弄清楚人们下雨时是否喜欢骑自行车。 所以我访问了加拿大历史天气数据的网站,并想出如何自动获得它们。
这里我们将获取 201 年 3 月的数据,并清理它们。
以下是可用于在蒙特利尔获取数据的网址模板。
url_template = "http://climate.weather.gc.ca/climateData/bulkdata_e.html?format=csv&stationID=5415&Year={year}&Month={month}&timeframe=1&submit=Download+Data"
我们获取 2013 年三月的数据,我们需要以month=3, year=2012对它格式化:
url = url_template.format(month=3, year=2012)
weather_mar2012 = pd.read_csv(url, skiprows=16, index_col='Date/Time', parse_dates=True, encoding='latin1')
这非常不错! 我们可以使用和以前一样的read_csv函数,并且只是给它一个 URL 作为文件名。 真棒。
在这个 CSV 的顶部有 16 行元数据,但是 Pandas 知道 CSV 很奇怪,所以有一个skiprows选项。 我们再次解析日期,并将Date/Time设置为索引列。 这是产生的DataFrame。
weather_mar2012
DatetimeIndex: 744 entries, 2012-03-01 00:00:00 to 2012-03-31 23:00:00
Data columns (total 24 columns):
Year 744 non-null values
Month 744 non-null values
Day 744 non-null values
Time 744 non-null values
Data Quality 744 non-null values
Temp (°C) 744 non-null values
Temp Flag 0 non-null values
Dew Point Temp (°C) 744 non-null values
Dew Point Temp Flag 0 non-null values
Rel Hum (%) 744 non-null values
Rel Hum Flag 0 non-null values
Wind Dir (10s deg) 715 non-null values
Wind Dir Flag 0 non-null values
Wind Spd (km/h) 744 non-null values
Wind Spd Flag 3 non-null values
Visibility (km) 744 non-null values
Visibility Flag 0 non-null values
Stn Press (kPa) 744 non-null values
Stn Press Flag 0 non-null values
Hmdx 12 non-null values
Hmdx Flag 0 non-null values
Wind Chill 242 non-null values
Wind Chill Flag 1 non-null values
Weather 744 non-null values
dtypes: float64(14), int64(5), object(5)
让我们绘制它吧!
weather_mar2012[u"Temp (\xb0C)"].plot(figsize=(15, 5))
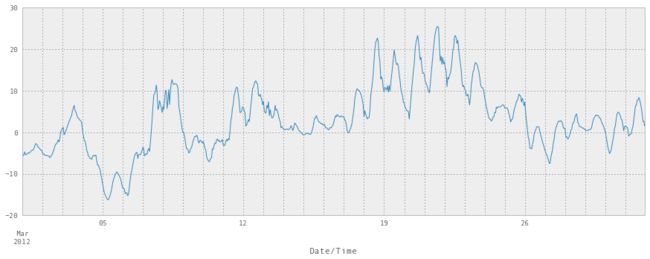
注意它在中间升高到25°C。这是一个大问题。 这是三月,人们在外面穿着短裤。
我出城了,而且错过了。真是伤心啊。
我需要将度数字符°写为'\xb0'。 让我们去掉它,让它更容易键入。
weather_mar2012.columns = [s.replace(u'\xb0', '') for s in weather_mar2012.columns]
你会注意到在上面的摘要中,有几个列完全是空的,或其中只有几个值。 让我们使用dropna去掉它们。
dropna中的axis=1意味着“删除列,而不是行”,以及how ='any'意味着“如果任何值为空,则删除列”。
现在更好了 - 我们只有带有真实数据的列。
| | Year | Month | Day | Time | Data Quality | Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather |
| --- | --- |
| Date/Time | | | | | | | | | | | | |
| 2012-03-01 00:00:00 | 2012 | 3 | 1 | 00:00 | | -5.5 | -9.7 | 72 | 24 | 4.0 | 100.97 | Snow |
| 2012-03-01 01:00:00 | 2012 | 3 | 1 | 01:00 | | -5.7 | -8.7 | 79 | 26 | 2.4 | 100.87 | Snow |
| 2012-03-01 02:00:00 | 2012 | 3 | 1 | 02:00 | | -5.4 | -8.3 | 80 | 28 | 4.8 | 100.80 | Snow |
| 2012-03-01 03:00:00 | 2012 | 3 | 1 | 03:00 | | -4.7 | -7.7 | 79 | 28 | 4.0 | 100.69 | Snow |
| 2012-03-01 04:00:00 | 2012 | 3 | 1 | 04:00 | | -5.4 | -7.8 | 83 | 35 | 1.6 | 100.62 | Snow |
Year/Month/Day/Time列是冗余的,但Data Quality列看起来不太有用。 让我们去掉他们。
axis = 1参数意味着“删除列”,像以前一样。 dropna和drop等操作的默认值总是对行进行操作。
weather_mar2012 = weather_mar2012.drop(['Year', 'Month', 'Day', 'Time', 'Data Quality'], axis=1)
weather_mar2012[:5]
| | Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather |
| --- | --- |
| Date/Time | | | | | | | |
| 2012-03-01 00:00:00 | -5.5 | -9.7 | 72 | 24 | 4.0 | 100.97 | Snow |
| 2012-03-01 01:00:00 | -5.7 | -8.7 | 79 | 26 | 2.4 | 100.87 | Snow |
| 2012-03-01 02:00:00 | -5.4 | -8.3 | 80 | 28 | 4.8 | 100.80 | Snow |
| 2012-03-01 03:00:00 | -4.7 | -7.7 | 79 | 28 | 4.0 | 100.69 | Snow |
| 2012-03-01 04:00:00 | -5.4 | -7.8 | 83 | 35 | 1.6 | 100.62 | Snow |
5.2 按一天中的小时绘制温度
这只是为了好玩 - 我们以前已经做过,使用groupby和aggregate! 我们将了解它是否在夜间变冷。 好吧,这是显然的。 但是让我们这样做。
temperatures = weather_mar2012[[u'Temp (C)']]
temperatures['Hour'] = weather_mar2012.index.hour
temperatures.groupby('Hour').aggregate(np.median).plot()
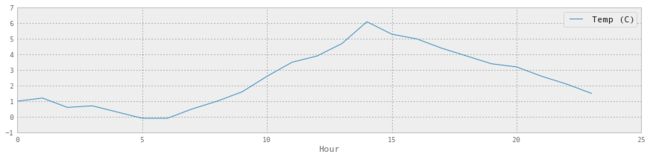
所以温度中位数在 2pm 时达到峰值。
5.3 获取整年的数据
好吧,那么如果我们想要全年的数据呢? 理想情况下 API 会让我们下载,但我不能找出一种方法来实现它。
首先,让我们将上面的成果放到一个函数中,函数按照给定月份获取天气。
我注意到有一个烦人的 bug,当我请求一月时,它给我上一年的数据,所以我们要解决这个问题。 【真的是这样。你可以检查一下 =)】
def download_weather_month(year, month):
if month == 1:
year += 1
url = url_template.format(year=year, month=month)
weather_data = pd.read_csv(url, skiprows=16, index_col='Date/Time', parse_dates=True)
weather_data = weather_data.dropna(axis=1)
weather_data.columns = [col.replace('\xb0', '') for col in weather_data.columns]
weather_data = weather_data.drop(['Year', 'Day', 'Month', 'Time', 'Data Quality'], axis=1)
return weather_data
我们可以测试这个函数是否行为正确:
download_weather_month(2012, 1)[:5]
| | Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather |
| --- | --- |
| Date/Time | | | | | | | |
| 2012-01-01 00:00:00 | -1.8 | -3.9 | 86 | 4 | 8.0 | 101.24 | Fog |
| 2012-01-01 01:00:00 | -1.8 | -3.7 | 87 | 4 | 8.0 | 101.24 | Fog |
| 2012-01-01 02:00:00 | -1.8 | -3.4 | 89 | 7 | 4.0 | 101.26 | Freezing Drizzle,Fog |
| 2012-01-01 03:00:00 | -1.5 | -3.2 | 88 | 6 | 4.0 | 101.27 | Freezing Drizzle,Fog |
| 2012-01-01 04:00:00 | -1.5 | -3.3 | 88 | 7 | 4.8 | 101.23 | Fog |
现在我们一次性获取了所有月份,需要一些时间来运行。
data_by_month = [download_weather_month(2012, i) for i in range(1, 13)]
一旦我们完成之后,可以轻易使用pd.concat将所有DataFrame连接成一个大DataFrame。 现在我们有整年的数据了!
weather_2012 = pd.concat(data_by_month)
weather_2012
DatetimeIndex: 8784 entries, 2012-01-01 00:00:00 to 2012-12-31 23:00:00
Data columns (total 7 columns):
Temp (C) 8784 non-null values
Dew Point Temp (C) 8784 non-null values
Rel Hum (%) 8784 non-null values
Wind Spd (km/h) 8784 non-null values
Visibility (km) 8784 non-null values
Stn Press (kPa) 8784 non-null values
Weather 8784 non-null values
dtypes: float64(4), int64(2), object(1)
5.4 保存到 CSV
每次下载数据会非常慢,所以让我们保存DataFrame:
weather_2012.to_csv('../data/weather_2012.csv')
这就完成了!
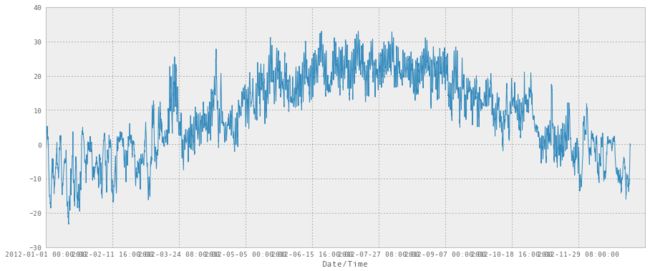
5.5 总结
在这一章末尾,我们下载了加拿大 2012 年的所有天气数据,并保存到了 CSV 中。
我们通过一次下载一个月份,之后组合所有月份来实现。
这里是 2012 年每一个小时的天气数据!
weather_2012_final = pd.read_csv('../data/weather_2012.csv', index_col='Date/Time')
weather_2012_final['Temp (C)'].plot(figsize=(15, 6))
第六章
import pandas as pd
pd.set_option('display.mpl_style', 'default')
figsize(15, 3)
我们前面看到,Pandas 真的很善于处理日期。 它也善于处理字符串! 我们从第 5 章回顾我们的天气数据。
weather_2012 = pd.read_csv('../data/weather_2012.csv', parse_dates=True, index_col='Date/Time')
weather_2012[:5]
| | Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather |
| --- | --- |
| Date/Time | | | | | | | |
| 2012-01-01 00:00:00 | -1.8 | -3.9 | 86 | 4 | 8.0 | 101.24 | Fog |
| 2012-01-01 01:00:00 | -1.8 | -3.7 | 87 | 4 | 8.0 | 101.24 | Fog |
| 2012-01-01 02:00:00 | -1.8 | -3.4 | 89 | 7 | 4.0 | 101.26 | Freezing Drizzle,Fog |
| 2012-01-01 03:00:00 | -1.5 | -3.2 | 88 | 6 | 4.0 | 101.27 | Freezing Drizzle,Fog |
| 2012-01-01 04:00:00 | -1.5 | -3.3 | 88 | 7 | 4.8 | 101.23 | Fog |
6.1 字符串操作
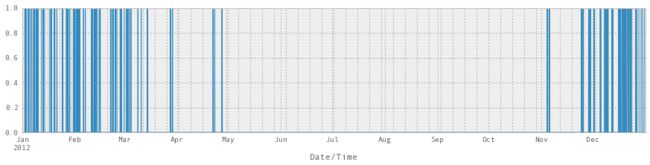
您会看到Weather列会显示每小时发生的天气的文字说明。 如果文本描述包含Snow,我们将假设它是下雪的。
pandas 提供了向量化的字符串函数,以便于对包含文本的列进行操作。 文档中有一些很好的例子。
weather_description = weather_2012['Weather']
is_snowing = weather_description.str.contains('Snow')
这会给我们一个二进制向量,很难看出里面的东西,所以我们绘制它:
# Not super useful
is_snowing[:5]
Date/Time
2012-01-01 00:00:00 False
2012-01-01 01:00:00 False
2012-01-01 02:00:00 False
2012-01-01 03:00:00 False
2012-01-01 04:00:00 False
Name: Weather, dtype: bool
# More useful!
is_snowing.plot()
6.2 使用resample找到下雪最多的月份
如果我们想要每个月的温度中值,我们可以使用resample()方法,如下所示:
weather_2012['Temp (C)'].resample('M', how=np.median).plot(kind='bar')
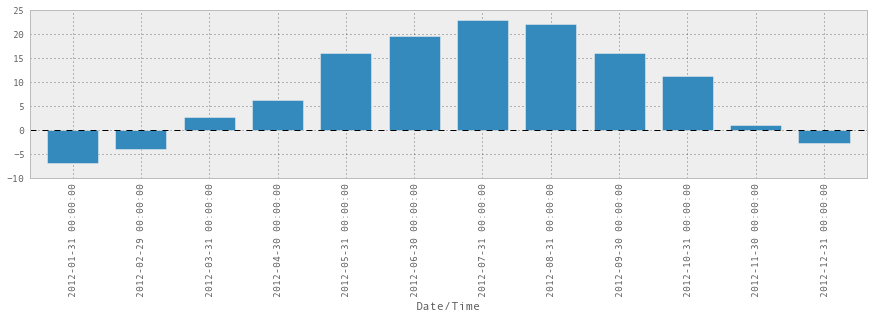
毫无奇怪,七月和八月是最暖和的。
所以我们可以将is_snowing转化为一堆 0 和 1,而不是True和False。
Date/Time
2012-01-01 00:00:00 0
2012-01-01 01:00:00 0
2012-01-01 02:00:00 0
2012-01-01 03:00:00 0
2012-01-01 04:00:00 0
2012-01-01 05:00:00 0
2012-01-01 06:00:00 0
2012-01-01 07:00:00 0
2012-01-01 08:00:00 0
2012-01-01 09:00:00 0
Name: Weather, dtype: float64
然后使用resample寻找每个月下雪的时间比例。
is_snowing.astype(float).resample('M', how=np.mean)
Date/Time
2012-01-31 0.240591
2012-02-29 0.162356
2012-03-31 0.087366
2012-04-30 0.015278
2012-05-31 0.000000
2012-06-30 0.000000
2012-07-31 0.000000
2012-08-31 0.000000
2012-09-30 0.000000
2012-10-31 0.000000
2012-11-30 0.038889
2012-12-31 0.251344
Freq: M, dtype: float64
is_snowing.astype(float).resample('M', how=np.mean).plot(kind='bar')
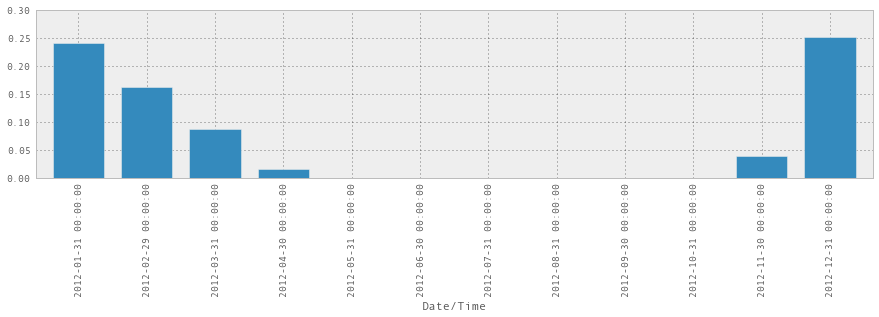
所以现在我们知道了! 2012 年 12 月是下雪最多的一个月。 此外,这个图表暗示着我感觉到的东西 - 11 月突然开始下雪,然后慢慢变慢,需要很长时间停止,最后下雪的月份通常在 4 月或 5 月。
6.3 将温度和降雪绘制在一起
我们还可以将这两个统计(温度和降雪)合并为一个DataFrame,并将它们绘制在一起:
temperature = weather_2012['Temp (C)'].resample('M', how=np.median)
is_snowing = weather_2012['Weather'].str.contains('Snow')
snowiness = is_snowing.astype(float).resample('M', how=np.mean)
# Name the columns
temperature.name = "Temperature"
snowiness.name = "Snowiness"
我们再次使用concat,将两个统计连接为一个DataFrame。
stats = pd.concat([temperature, snowiness], axis=1)
stats
| Temperature | Snowiness | |
|---|---|---|
| Date/Time | ||
| 2012-01-31 | -7.05 | 0.240591 |
| 2012-02-29 | -4.10 | 0.162356 |
| 2012-03-31 | 2.60 | 0.087366 |
| 2012-04-30 | 6.30 | 0.015278 |
| 2012-05-31 | 16.05 | 0.000000 |
| 2012-06-30 | 19.60 | 0.000000 |
| 2012-07-31 | 22.90 | 0.000000 |
| 2012-08-31 | 22.20 | 0.000000 |
| 2012-09-30 | 16.10 | 0.000000 |
| 2012-10-31 | 11.30 | 0.000000 |
| 2012-11-30 | 1.05 | 0.038889 |
| 2012-12-31 | -2.85 | 0.251344 |
stats.plot(kind='bar')
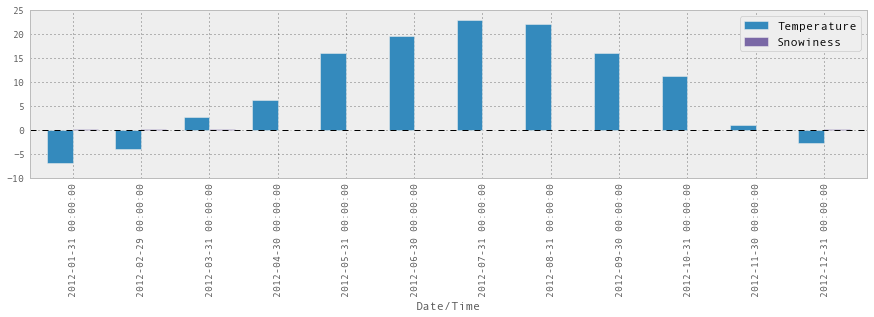
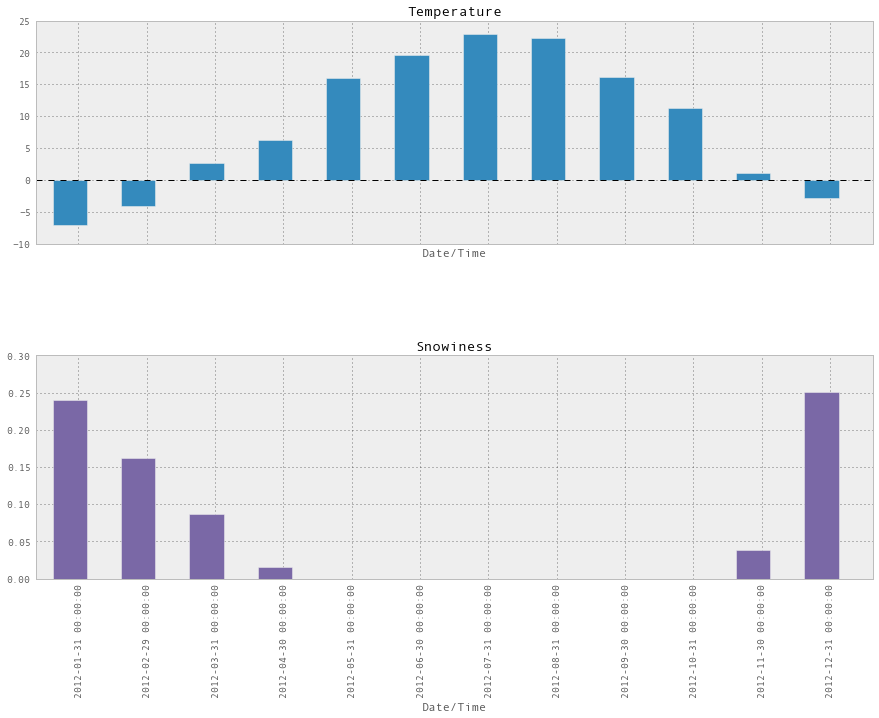
这并不能正常工作,因为比例不对,我们可以在两个图表中分别绘制它们,这样会更好:
stats.plot(kind='bar', subplots=True, figsize=(15, 10))
array([,
], dtype=object)
第七章
# 通常的开头
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 使图表更大更漂亮
pd.set_option('display.mpl_style', 'default')
plt.rcParams['figure.figsize'] = (15, 5)
plt.rcParams['font.family'] = 'sans-serif'
# 在 Pandas 0.12 中需要展示大量的列
# 在 Pandas 0.13 中不需要
pd.set_option('display.width', 5000)
pd.set_option('display.max_columns', 60)
杂乱数据的主要问题之一是:你怎么知道它是否杂乱呢?
我们将在这里使用 NYC 311 服务请求数据集,因为它很大,有点不方便。
requests = pd.read_csv('../data/311-service-requests.csv')
7.1 我怎么知道它是否杂乱?
我们在这里查看几列。 我知道邮政编码有一些问题,所以让我们先看看它。
要了解列是否有问题,我通常使用.unique()来查看所有的值。 如果它是一列数字,我将绘制一个直方图来获得分布的感觉。
当我们看看Incident Zip中的唯一值时,很快就会清楚这是一个混乱。
一些问题:
- 一些已经解析为字符串,一些是浮点
- 存在
nan - 部分邮政编码为
29616-0759或83 - 有一些 Pandas 无法识别的 N/A 值 ,如
'N/A'和'NO CLUE'
我们可以做的事情:
- 将
N/A和NO CLUE规格化为nan值 - 看看 83 处发生了什么,并决定做什么
- 将一切转化为字符串
requests['Incident Zip'].unique()
array([11432.0, 11378.0, 10032.0, 10023.0, 10027.0, 11372.0, 11419.0,
11417.0, 10011.0, 11225.0, 11218.0, 10003.0, 10029.0, 10466.0,
11219.0, 10025.0, 10310.0, 11236.0, nan, 10033.0, 11216.0, 10016.0,
10305.0, 10312.0, 10026.0, 10309.0, 10036.0, 11433.0, 11235.0,
11213.0, 11379.0, 11101.0, 10014.0, 11231.0, 11234.0, 10457.0,
10459.0, 10465.0, 11207.0, 10002.0, 10034.0, 11233.0, 10453.0,
10456.0, 10469.0, 11374.0, 11221.0, 11421.0, 11215.0, 10007.0,
10019.0, 11205.0, 11418.0, 11369.0, 11249.0, 10005.0, 10009.0,
11211.0, 11412.0, 10458.0, 11229.0, 10065.0, 10030.0, 11222.0,
10024.0, 10013.0, 11420.0, 11365.0, 10012.0, 11214.0, 11212.0,
10022.0, 11232.0, 11040.0, 11226.0, 10281.0, 11102.0, 11208.0,
10001.0, 10472.0, 11414.0, 11223.0, 10040.0, 11220.0, 11373.0,
11203.0, 11691.0, 11356.0, 10017.0, 10452.0, 10280.0, 11217.0,
10031.0, 11201.0, 11358.0, 10128.0, 11423.0, 10039.0, 10010.0,
11209.0, 10021.0, 10037.0, 11413.0, 11375.0, 11238.0, 10473.0,
11103.0, 11354.0, 11361.0, 11106.0, 11385.0, 10463.0, 10467.0,
11204.0, 11237.0, 11377.0, 11364.0, 11434.0, 11435.0, 11210.0,
11228.0, 11368.0, 11694.0, 10464.0, 11415.0, 10314.0, 10301.0,
10018.0, 10038.0, 11105.0, 11230.0, 10468.0, 11104.0, 10471.0,
11416.0, 10075.0, 11422.0, 11355.0, 10028.0, 10462.0, 10306.0,
10461.0, 11224.0, 11429.0, 10035.0, 11366.0, 11362.0, 11206.0,
10460.0, 10304.0, 11360.0, 11411.0, 10455.0, 10475.0, 10069.0,
10303.0, 10308.0, 10302.0, 11357.0, 10470.0, 11367.0, 11370.0,
10454.0, 10451.0, 11436.0, 11426.0, 10153.0, 11004.0, 11428.0,
11427.0, 11001.0, 11363.0, 10004.0, 10474.0, 11430.0, 10000.0,
10307.0, 11239.0, 10119.0, 10006.0, 10048.0, 11697.0, 11692.0,
11693.0, 10573.0, 83.0, 11559.0, 10020.0, 77056.0, 11776.0, 70711.0,
10282.0, 11109.0, 10044.0, '10452', '11233', '10468', '10310',
'11105', '10462', '10029', '10301', '10457', '10467', '10469',
'11225', '10035', '10031', '11226', '10454', '11221', '10025',
'11229', '11235', '11422', '10472', '11208', '11102', '10032',
'11216', '10473', '10463', '11213', '10040', '10302', '11231',
'10470', '11204', '11104', '11212', '10466', '11416', '11214',
'10009', '11692', '11385', '11423', '11201', '10024', '11435',
'10312', '10030', '11106', '10033', '10303', '11215', '11222',
'11354', '10016', '10034', '11420', '10304', '10019', '11237',
'11249', '11230', '11372', '11207', '11378', '11419', '11361',
'10011', '11357', '10012', '11358', '10003', '10002', '11374',
'10007', '11234', '10065', '11369', '11434', '11205', '11206',
'11415', '11236', '11218', '11413', '10458', '11101', '10306',
'11355', '10023', '11368', '10314', '11421', '10010', '10018',
'11223', '10455', '11377', '11433', '11375', '10037', '11209',
'10459', '10128', '10014', '10282', '11373', '10451', '11238',
'11211', '10038', '11694', '11203', '11691', '11232', '10305',
'10021', '11228', '10036', '10001', '10017', '11217', '11219',
'10308', '10465', '11379', '11414', '10460', '11417', '11220',
'11366', '10027', '11370', '10309', '11412', '11356', '10456',
'11432', '10022', '10013', '11367', '11040', '10026', '10475',
'11210', '11364', '11426', '10471', '10119', '11224', '11418',
'11429', '11365', '10461', '11239', '10039', '00083', '11411',
'10075', '11004', '11360', '10453', '10028', '11430', '10307',
'11103', '10004', '10069', '10005', '10474', '11428', '11436',
'10020', '11001', '11362', '11693', '10464', '11427', '10044',
'11363', '10006', '10000', '02061', '77092-2016', '10280', '11109',
'14225', '55164-0737', '19711', '07306', '000000', 'NO CLUE',
'90010', '10281', '11747', '23541', '11776', '11697', '11788',
'07604', 10112.0, 11788.0, 11563.0, 11580.0, 7087.0, 11042.0,
7093.0, 11501.0, 92123.0, 0.0, 11575.0, 7109.0, 11797.0, '10803',
'11716', '11722', '11549-3650', '10162', '92123', '23502', '11518',
'07020', '08807', '11577', '07114', '11003', '07201', '11563',
'61702', '10103', '29616-0759', '35209-3114', '11520', '11735',
'10129', '11005', '41042', '11590', 6901.0, 7208.0, 11530.0,
13221.0, 10954.0, 11735.0, 10103.0, 7114.0, 11111.0, 10107.0], dtype=object)
7.3 修复nan值和字符串/浮点混淆
我们可以将na_values选项传递到pd.read_csv来清理它们。 我们还可以指定Incident Zip的类型是字符串,而不是浮点。
na_values = ['NO CLUE', 'N/A', '0']
requests = pd.read_csv('../data/311-service-requests.csv', na_values=na_values, dtype={'Incident Zip': str})
requests['Incident Zip'].unique()
array(['11432', '11378', '10032', '10023', '10027', '11372', '11419',
'11417', '10011', '11225', '11218', '10003', '10029', '10466',
'11219', '10025', '10310', '11236', nan, '10033', '11216', '10016',
'10305', '10312', '10026', '10309', '10036', '11433', '11235',
'11213', '11379', '11101', '10014', '11231', '11234', '10457',
'10459', '10465', '11207', '10002', '10034', '11233', '10453',
'10456', '10469', '11374', '11221', '11421', '11215', '10007',
'10019', '11205', '11418', '11369', '11249', '10005', '10009',
'11211', '11412', '10458', '11229', '10065', '10030', '11222',
'10024', '10013', '11420', '11365', '10012', '11214', '11212',
'10022', '11232', '11040', '11226', '10281', '11102', '11208',
'10001', '10472', '11414', '11223', '10040', '11220', '11373',
'11203', '11691', '11356', '10017', '10452', '10280', '11217',
'10031', '11201', '11358', '10128', '11423', '10039', '10010',
'11209', '10021', '10037', '11413', '11375', '11238', '10473',
'11103', '11354', '11361', '11106', '11385', '10463', '10467',
'11204', '11237', '11377', '11364', '11434', '11435', '11210',
'11228', '11368', '11694', '10464', '11415', '10314', '10301',
'10018', '10038', '11105', '11230', '10468', '11104', '10471',
'11416', '10075', '11422', '11355', '10028', '10462', '10306',
'10461', '11224', '11429', '10035', '11366', '11362', '11206',
'10460', '10304', '11360', '11411', '10455', '10475', '10069',
'10303', '10308', '10302', '11357', '10470', '11367', '11370',
'10454', '10451', '11436', '11426', '10153', '11004', '11428',
'11427', '11001', '11363', '10004', '10474', '11430', '10000',
'10307', '11239', '10119', '10006', '10048', '11697', '11692',
'11693', '10573', '00083', '11559', '10020', '77056', '11776',
'70711', '10282', '11109', '10044', '02061', '77092-2016', '14225',
'55164-0737', '19711', '07306', '000000', '90010', '11747', '23541',
'11788', '07604', '10112', '11563', '11580', '07087', '11042',
'07093', '11501', '92123', '00000', '11575', '07109', '11797',
'10803', '11716', '11722', '11549-3650', '10162', '23502', '11518',
'07020', '08807', '11577', '07114', '11003', '07201', '61702',
'10103', '29616-0759', '35209-3114', '11520', '11735', '10129',
'11005', '41042', '11590', '06901', '07208', '11530', '13221',
'10954', '11111', '10107'], dtype=object)
7.4 短横线处发生了什么
rows_with_dashes = requests['Incident Zip'].str.contains('-').fillna(False)
len(requests[rows_with_dashes])
5
requests[rows_with_dashes]
| | Unique Key | Created Date | Closed Date | Agency | Agency Name | Complaint Type | Descriptor | Location Type | Incident Zip | Incident Address | Street Name | Cross Street 1 | Cross Street 2 | Intersection Street 1 | Intersection Street 2 | Address Type | City | Landmark | Facility Type | Status | Due Date | Resolution Action Updated Date | Community Board | Borough | X Coordinate (State Plane) | Y Coordinate (State Plane) | Park Facility Name | Park Borough | School Name | School Number | School Region | School Code | School Phone Number | School Address | School City | School State | School Zip | School Not Found | School or Citywide Complaint | Vehicle Type | Taxi Company Borough | Taxi Pick Up Location | Bridge Highway Name | Bridge Highway Direction | Road Ramp | Bridge Highway Segment | Garage Lot Name | Ferry Direction | Ferry Terminal Name | Latitude | Longitude | Location |
| --- | --- |
| 29136 | 26550551 | 10/24/2013 06:16:34 PM | NaN | DCA | Department of Consumer Affairs | Consumer Complaint | False Advertising | NaN | 77092-2016 | 2700 EAST SELTICE WAY | EAST SELTICE WAY | NaN | NaN | NaN | NaN | NaN | HOUSTON | NaN | NaN | Assigned | 11/13/2013 11:15:20 AM | 10/29/2013 11:16:16 AM | 0 Unspecified | Unspecified | NaN | NaN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 30939 | 26548831 | 10/24/2013 09:35:10 AM | NaN | DCA | Department of Consumer Affairs | Consumer Complaint | Harassment | NaN | 55164-0737 | P.O. BOX 64437 | 64437 | NaN | NaN | NaN | NaN | NaN | ST. PAUL | NaN | NaN | Assigned | 11/13/2013 02:30:21 PM | 10/29/2013 02:31:06 PM | 0 Unspecified | Unspecified | NaN | NaN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 70539 | 26488417 | 10/15/2013 03:40:33 PM | NaN | TLC | Taxi and Limousine Commission | Taxi Complaint | Driver Complaint | Street | 11549-3650 | 365 HOFSTRA UNIVERSITY | HOFSTRA UNIVERSITY | NaN | NaN | NaN | NaN | NaN | HEMSTEAD | NaN | NaN | Assigned | 11/30/2013 01:20:33 PM | 10/16/2013 01:21:39 PM | 0 Unspecified | Unspecified | NaN | NaN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | La Guardia Airport | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 85821 | 26468296 | 10/10/2013 12:36:43 PM | 10/26/2013 01:07:07 AM | DCA | Department of Consumer Affairs | Consumer Complaint | Debt Not Owed | NaN | 29616-0759 | PO BOX 25759 | BOX 25759 | NaN | NaN | NaN | NaN | NaN | GREENVILLE | NaN | NaN | Closed | 10/26/2013 09:20:28 AM | 10/26/2013 01:07:07 AM | 0 Unspecified | Unspecified | NaN | NaN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 89304 | 26461137 | 10/09/2013 05:23:46 PM | 10/25/2013 01:06:41 AM | DCA | Department of Consumer Affairs | Consumer Complaint | Harassment | NaN | 35209-3114 | 600 BEACON PKWY | BEACON PKWY | NaN | NaN | NaN | NaN | NaN | BIRMINGHAM | NaN | NaN | Closed | 10/25/2013 02:43:42 PM | 10/25/2013 01:06:41 AM | 0 Unspecified | Unspecified | NaN | NaN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
我认为这些都是缺失的数据,像这样删除它们:
requests['Incident Zip'][rows_with_dashes] = np.nan
但是我的朋友 Dave 指出,9 位邮政编码是正常的。 让我们看看所有超过 5 位数的邮政编码,确保它们没问题,然后截断它们。
long_zip_codes = requests['Incident Zip'].str.len() > 5
requests['Incident Zip'][long_zip_codes].unique()
array(['77092-2016', '55164-0737', '000000', '11549-3650', '29616-0759',
'35209-3114'], dtype=object)
这些看起来可以截断:
requests['Incident Zip'] = requests['Incident Zip'].str.slice(0, 5)
就可以了。
早些时候我认为 00083 是一个损坏的邮政编码,但事实证明中央公园的邮政编码是 00083! 显示我知道的吧。 我仍然关心 00000 邮政编码,但是:让我们看看。
requests[requests['Incident Zip'] == '00000']
| | Unique Key | Created Date | Closed Date | Agency | Agency Name | Complaint Type | Descriptor | Location Type | Incident Zip | Incident Address | Street Name | Cross Street 1 | Cross Street 2 | Intersection Street 1 | Intersection Street 2 | Address Type | City | Landmark | Facility Type | Status | Due Date | Resolution Action Updated Date | Community Board | Borough | X Coordinate (State Plane) | Y Coordinate (State Plane) | Park Facility Name | Park Borough | School Name | School Number | School Region | School Code | School Phone Number | School Address | School City | School State | School Zip | School Not Found | School or Citywide Complaint | Vehicle Type | Taxi Company Borough | Taxi Pick Up Location | Bridge Highway Name | Bridge Highway Direction | Road Ramp | Bridge Highway Segment | Garage Lot Name | Ferry Direction | Ferry Terminal Name | Latitude | Longitude | Location |
| --- | --- |
| 42600 | 26529313 | 10/22/2013 02:51:06 PM | NaN | TLC | Taxi and Limousine Commission | Taxi Complaint | Driver Complaint | NaN | 00000 | EWR EWR | EWR | NaN | NaN | NaN | NaN | NaN | NEWARK | NaN | NaN | Assigned | 12/07/2013 09:53:51 AM | 10/23/2013 09:54:43 AM | 0 Unspecified | Unspecified | NaN | NaN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | Other | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 60843 | 26507389 | 10/17/2013 05:48:44 PM | NaN | TLC | Taxi and Limousine Commission | Taxi Complaint | Driver Complaint | Street | 00000 | 1 NEWARK AIRPORT | NEWARK AIRPORT | NaN | NaN | NaN | NaN | NaN | NEWARK | NaN | NaN | Assigned | 12/02/2013 11:59:46 AM | 10/18/2013 12:01:08 PM | 0 Unspecified | Unspecified | NaN | NaN | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | Unspecified | N | NaN | NaN | NaN | Other | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
这看起来对我来说很糟糕,让我将它们设为NaN。
zero_zips = requests['Incident Zip'] == '00000'
requests.loc[zero_zips, 'Incident Zip'] = np.nan
太棒了,让我们看看现在在哪里。
unique_zips = requests['Incident Zip'].unique()
unique_zips.sort()
unique_zips
array([nan, '00083', '02061', '06901', '07020', '07087', '07093', '07109',
'07114', '07201', '07208', '07306', '07604', '08807', '10000',
'10001', '10002', '10003', '10004', '10005', '10006', '10007',
'10009', '10010', '10011', '10012', '10013', '10014', '10016',
'10017', '10018', '10019', '10020', '10021', '10022', '10023',
'10024', '10025', '10026', '10027', '10028', '10029', '10030',
'10031', '10032', '10033', '10034', '10035', '10036', '10037',
'10038', '10039', '10040', '10044', '10048', '10065', '10069',
'10075', '10103', '10107', '10112', '10119', '10128', '10129',
'10153', '10162', '10280', '10281', '10282', '10301', '10302',
'10303', '10304', '10305', '10306', '10307', '10308', '10309',
'10310', '10312', '10314', '10451', '10452', '10453', '10454',
'10455', '10456', '10457', '10458', '10459', '10460', '10461',
'10462', '10463', '10464', '10465', '10466', '10467', '10468',
'10469', '10470', '10471', '10472', '10473', '10474', '10475',
'10573', '10803', '10954', '11001', '11003', '11004', '11005',
'11040', '11042', '11101', '11102', '11103', '11104', '11105',
'11106', '11109', '11111', '11201', '11203', '11204', '11205',
'11206', '11207', '11208', '11209', '11210', '11211', '11212',
'11213', '11214', '11215', '11216', '11217', '11218', '11219',
'11220', '11221', '11222', '11223', '11224', '11225', '11226',
'11228', '11229', '11230', '11231', '11232', '11233', '11234',
'11235', '11236', '11237', '11238', '11239', '11249', '11354',
'11355', '11356', '11357', '11358', '11360', '11361', '11362',
'11363', '11364', '11365', '11366', '11367', '11368', '11369',
'11370', '11372', '11373', '11374', '11375', '11377', '11378',
'11379', '11385', '11411', '11412', '11413', '11414', '11415',
'11416', '11417', '11418', '11419', '11420', '11421', '11422',
'11423', '11426', '11427', '11428', '11429', '11430', '11432',
'11433', '11434', '11435', '11436', '11501', '11518', '11520',
'11530', '11549', '11559', '11563', '11575', '11577', '11580',
'11590', '11691', '11692', '11693', '11694', '11697', '11716',
'11722', '11735', '11747', '11776', '11788', '11797', '13221',
'14225', '19711', '23502', '23541', '29616', '35209', '41042',
'55164', '61702', '70711', '77056', '77092', '90010', '92123'], dtype=object)
太棒了! 这更加干净。 虽然这里有一些奇怪的东西 - 我在谷歌地图上查找 77056,这是在德克萨斯州。
让我们仔细看看:
zips = requests['Incident Zip']
# Let's say the zips starting with '0' and '1' are okay, for now. (this isn't actually true -- 13221 is in Syracuse, and why?)
is_close = zips.str.startswith('0') | zips.str.startswith('1')
# There are a bunch of NaNs, but we're not interested in them right now, so we'll say they're False
is_far = ~(is_close) & zips.notnull()
zips[is_far]
12102 77056
13450 70711
29136 77092
30939 55164
44008 90010
47048 23541
57636 92123
71001 92123
71834 23502
80573 61702
85821 29616
89304 35209
94201 41042
Name: Incident Zip, dtype: object
requests[is_far][['Incident Zip', 'Descriptor', 'City']].sort('Incident Zip')
| | Incident Zip | Descriptor | City |
| --- | --- |
| 71834 | 23502 | Harassment | NORFOLK |
| 47048 | 23541 | Harassment | NORFOLK |
| 85821 | 29616 | Debt Not Owed | GREENVILLE |
| 89304 | 35209 | Harassment | BIRMINGHAM |
| 94201 | 41042 | Harassment | FLORENCE |
| 30939 | 55164 | Harassment | ST. PAUL |
| 80573 | 61702 | Billing Dispute | BLOOMIGTON |
| 13450 | 70711 | Contract Dispute | CLIFTON |
| 12102 | 77056 | Debt Not Owed | HOUSTON |
| 29136 | 77092 | False Advertising | HOUSTON |
| 44008 | 90010 | Billing Dispute | LOS ANGELES |
| 57636 | 92123 | Harassment | SAN DIEGO |
| 71001 | 92123 | Billing Dispute | SAN DIEGO |
好吧,真的有来自 LA 和休斯敦的请求! 很高兴知道它们。 按邮政编码过滤可能是处理它的一个糟糕的方式 - 我们真的应该看着城市。
requests['City'].str.upper().value_counts()
BROOKLYN 31662
NEW YORK 22664
BRONX 18438
STATEN ISLAND 4766
JAMAICA 2246
FLUSHING 1803
ASTORIA 1568
RIDGEWOOD 1073
CORONA 707
OZONE PARK 693
LONG ISLAND CITY 678
FAR ROCKAWAY 652
ELMHURST 647
WOODSIDE 609
EAST ELMHURST 562
...
MELVILLE 1
PORT JEFFERSON STATION 1
NORWELL 1
EAST ROCKAWAY 1
BIRMINGHAM 1
ROSLYN 1
LOS ANGELES 1
MINEOLA 1
JERSEY CITY 1
ST. PAUL 1
CLIFTON 1
COL.ANVURES 1
EDGEWATER 1
ROSELYN 1
CENTRAL ISLIP 1
Length: 100, dtype: int64
看起来这些是合法的投诉,所以我们只是把它们放在一边。
7.5 把它们放到一起
这里是我们最后所做的事情,用于清理我们的邮政编码,都在一起:
na_values = ['NO CLUE', 'N/A', '0']
requests = pd.read_csv('../data/311-service-requests.csv',
na_values=na_values,
dtype={'Incident Zip': str})
def fix_zip_codes(zips):
# Truncate everything to length 5
zips = zips.str.slice(0, 5)
# Set 00000 zip codes to nan
zero_zips = zips == '00000'
zips[zero_zips] = np.nan
return zips
requests['Incident Zip'] = fix_zip_codes(requests['Incident Zip'])
requests['Incident Zip'].unique()
array(['11432', '11378', '10032', '10023', '10027', '11372', '11419',
'11417', '10011', '11225', '11218', '10003', '10029', '10466',
'11219', '10025', '10310', '11236', nan, '10033', '11216', '10016',
'10305', '10312', '10026', '10309', '10036', '11433', '11235',
'11213', '11379', '11101', '10014', '11231', '11234', '10457',
'10459', '10465', '11207', '10002', '10034', '11233', '10453',
'10456', '10469', '11374', '11221', '11421', '11215', '10007',
'10019', '11205', '11418', '11369', '11249', '10005', '10009',
'11211', '11412', '10458', '11229', '10065', '10030', '11222',
'10024', '10013', '11420', '11365', '10012', '11214', '11212',
'10022', '11232', '11040', '11226', '10281', '11102', '11208',
'10001', '10472', '11414', '11223', '10040', '11220', '11373',
'11203', '11691', '11356', '10017', '10452', '10280', '11217',
'10031', '11201', '11358', '10128', '11423', '10039', '10010',
'11209', '10021', '10037', '11413', '11375', '11238', '10473',
'11103', '11354', '11361', '11106', '11385', '10463', '10467',
'11204', '11237', '11377', '11364', '11434', '11435', '11210',
'11228', '11368', '11694', '10464', '11415', '10314', '10301',
'10018', '10038', '11105', '11230', '10468', '11104', '10471',
'11416', '10075', '11422', '11355', '10028', '10462', '10306',
'10461', '11224', '11429', '10035', '11366', '11362', '11206',
'10460', '10304', '11360', '11411', '10455', '10475', '10069',
'10303', '10308', '10302', '11357', '10470', '11367', '11370',
'10454', '10451', '11436', '11426', '10153', '11004', '11428',
'11427', '11001', '11363', '10004', '10474', '11430', '10000',
'10307', '11239', '10119', '10006', '10048', '11697', '11692',
'11693', '10573', '00083', '11559', '10020', '77056', '11776',
'70711', '10282', '11109', '10044', '02061', '77092', '14225',
'55164', '19711', '07306', '90010', '11747', '23541', '11788',
'07604', '10112', '11563', '11580', '07087', '11042', '07093',
'11501', '92123', '11575', '07109', '11797', '10803', '11716',
'11722', '11549', '10162', '23502', '11518', '07020', '08807',
'11577', '07114', '11003', '07201', '61702', '10103', '29616',
'35209', '11520', '11735', '10129', '11005', '41042', '11590',
'06901', '07208', '11530', '13221', '10954', '11111', '10107'], dtype=object)
第八章
import pandas as pd
8.1 解析 Unix 时间戳
在 pandas 中处理 Unix 时间戳不是很容易 - 我花了相当长的时间来解决这个问题。 我们在这里使用的文件是一个软件包流行度文件,我在我的系统上的/var/log/popularity-contest找到的。
这里解释了这个文件是什么。
# Read it, and remove the last row
popcon = pd.read_csv('../data/popularity-contest', sep=' ', )[:-1]
popcon.columns = ['atime', 'ctime', 'package-name', 'mru-program', 'tag']
列是访问时间,创建时间,包名称最近使用的程序,以及标签。
popcon[:5]
| | atime | ctime | package-name | mru-program | tag |
| --- | --- |
| 0 | 1387295797 | 1367633260 | perl-base | /usr/bin/perl | NaN |
| 1 | 1387295796 | 1354370480 | login | /bin/su | NaN |
| 2 | 1387295743 | 1354341275 | libtalloc2 | /usr/lib/x86_64-linux-gnu/libtalloc.so.2.0.7 | NaN |
| 3 | 1387295743 | 1387224204 | libwbclient0 | /usr/lib/x86_64-linux-gnu/libwbclient.so.0 |
| 4 | 1387295742 | 1354341253 | libselinux1 | /lib/x86_64-linux-gnu/libselinux.so.1 | NaN |
pandas 中的时间戳解析的神奇部分是 numpy datetime已经存储为 Unix 时间戳。 所以我们需要做的是告诉 pandas 这些整数实际上是数据时间 - 它不需要做任何转换。
我们需要首先将这些转换为整数:
popcon['atime'] = popcon['atime'].astype(int)
popcon['ctime'] = popcon['ctime'].astype(int)
每个 numpy 数组和 pandas 序列都有一个dtype - 这通常是int64,float64或object。 一些可用的时间类型是datetime64[s],datetime64[ms]和datetime64[us]。 与之相似,也有timedelta类型。
我们可以使用pd.to_datetime函数将我们的整数时间戳转换为datetimes。 这是一个常量时间操作 - 我们实际上并不改变任何数据,只是改变了 Pandas 如何看待它。
popcon['atime'] = pd.to_datetime(popcon['atime'], unit='s')
popcon['ctime'] = pd.to_datetime(popcon['ctime'], unit='s')
如果我们现在查看dtype,它是M8是datetime64的简写。
popcon['atime'].dtype
dtype('所以现在我们将atime和ctime看做时间了。
popcon[:5]
| | atime | ctime | package-name | mru-program | tag |
| --- | --- |
| 0 | 2013-12-17 15:56:37 | 2013-05-04 02:07:40 | perl-base | /usr/bin/perl | NaN |
| 1 | 2013-12-17 15:56:36 | 2012-12-01 14:01:20 | login | /bin/su | NaN |
| 2 | 2013-12-17 15:55:43 | 2012-12-01 05:54:35 | libtalloc2 | /usr/lib/x86_64-linux-gnu/libtalloc.so.2.0.7 | NaN |
| 3 | 2013-12-17 15:55:43 | 2013-12-16 20:03:24 | libwbclient0 | /usr/lib/x86_64-linux-gnu/libwbclient.so.0 |
| 4 | 2013-12-17 15:55:42 | 2012-12-01 05:54:13 | libselinux1 | /lib/x86_64-linux-gnu/libselinux.so.1 | NaN |
现在假设我们要查看所有不是库的软件包。
首先,我想去掉一切带有时间戳 0 的东西。注意,我们可以在这个比较中使用一个字符串,即使它实际上在里面是一个时间戳。这是因为 Pandas 是非常厉害的。
popcon = popcon[popcon['atime'] > '1970-01-01']
现在我们可以使用 pandas 的魔法字符串功能来查看包名称不包含lib的行。
nonlibraries = popcon[~popcon['package-name'].str.contains('lib')]
nonlibraries.sort('ctime', ascending=False)[:10]
| | atime | ctime | package-name | mru-program | tag |
| --- | --- |
| 57 | 2013-12-17 04:55:39 | 2013-12-17 04:55:42 | ddd | /usr/bin/ddd |
| 450 | 2013-12-16 20:03:20 | 2013-12-16 20:05:13 | nodejs | /usr/bin/npm |
| 454 | 2013-12-16 20:03:20 | 2013-12-16 20:05:04 | switchboard-plug-keyboard | /usr/lib/plugs/pantheon/keyboard/options.txt |
| 445 | 2013-12-16 20:03:20 | 2013-12-16 20:05:04 | thunderbird-locale-en | /usr/lib/thunderbird-addons/extensions/langpac... |
| 396 | 2013-12-16 20:08:27 | 2013-12-16 20:05:03 | software-center | /usr/sbin/update-software-center |
| 449 | 2013-12-16 20:03:20 | 2013-12-16 20:05:00 | samba-common-bin | /usr/bin/net.samba3 |
| 397 | 2013-12-16 20:08:25 | 2013-12-16 20:04:59 | postgresql-client-9.1 | /usr/lib/postgresql/9.1/bin/psql |
| 398 | 2013-12-16 20:08:23 | 2013-12-16 20:04:58 | postgresql-9.1 | /usr/lib/postgresql/9.1/bin/postmaster |
| 452 | 2013-12-16 20:03:20 | 2013-12-16 20:04:55 | php5-dev | /usr/include/php5/main/snprintf.h |
| 440 | 2013-12-16 20:03:20 | 2013-12-16 20:04:54 | php-pear | /usr/share/php/XML/Util.php |
好吧,很酷,它说我最近安装了ddd。 和postgresql! 我记得安装这些东西。
这里的整个消息是,如果你有一个以秒或毫秒或纳秒为单位的时间戳,那么你可以“转换”到datetime64 [the-right-thing],并且 pandas/numpy 将处理其余的事情。
第九章
import pandas as pd
import sqlite3
到目前为止,我们只涉及从 CSV 文件中读取数据。 这是一个存储数据的常见方式,但有很多其它方式! Pandas 可以从 HTML,JSON,SQL,Excel(!!!),HDF5,Stata 和其他一些东西中读取数据。 在本章中,我们将讨论从 SQL 数据库读取数据。
您可以使用pd.read_sql函数从 SQL 数据库读取数据。 read_sql将自动将 SQL 列名转换为DataFrame列名。
read_sql需要 2 个参数:SELECT语句和数据库连接对象。 这是极好的,因为它意味着你可以从任何种类的 SQL 数据库读取 - 无论是 MySQL,SQLite,PostgreSQL 或其他东西。
此示例从 SQLite 数据库读取,但任何其他数据库将以相同的方式工作。
con = sqlite3.connect("../data/weather_2012.sqlite")
df = pd.read_sql("SELECT * from weather_2012 LIMIT 3", con)
df
| | id | date_time | temp |
| --- | --- |
| 0 | 1 | 2012-01-01 00:00:00 | -1.8 |
| 1 | 2 | 2012-01-01 01:00:00 | -1.8 |
| 2 | 3 | 2012-01-01 02:00:00 | -1.8 |
read_sql不会自动将主键(id)设置为DataFrame的索引。 你可以通过向read_sql添加一个index_col参数来实现。
如果你大量使用read_csv,你可能已经看到它有一个index_col参数。 这个行为是一样的。
df = pd.read_sql("SELECT * from weather_2012 LIMIT 3", con, index_col='id')
df
| | date_time | temp |
| --- | --- |
| id | | |
| 1 | 2012-01-01 00:00:00 | -1.8 |
| 2 | 2012-01-01 01:00:00 | -1.8 |
| 3 | 2012-01-01 02:00:00 | -1.8 |
如果希望DataFrame由多个列索引,可以将列的列表提供给index_col:
df = pd.read_sql("SELECT * from weather_2012 LIMIT 3", con,
index_col=['id', 'date_time'])
df
| | | temp |
| --- | --- |
| id | date_time | |
| 1 | 2012-01-01 00:00:00 | -1.8 |
| 2 | 2012-01-01 01:00:00 | -1.8 |
| 3 | 2012-01-01 02:00:00 | -1.8 |
9.2 写入 SQLite 数据库
Pandas 拥有write_frame函数,它从DataFrame创建一个数据库表。 现在这只适用于 SQLite 数据库。 让我们使用它,来将我们的 2012 天气数据转换为 SQL。
你会注意到这个函数在pd.io.sql中。 在pd.io中有很多有用的函数,用于读取和写入各种类型的数据,值得花一些时间来探索它们。 (请参阅文档!)
weather_df = pd.read_csv('../data/weather_2012.csv')
con = sqlite3.connect("../data/test_db.sqlite")
con.execute("DROP TABLE IF EXISTS weather_2012")
weather_df.to_sql("weather_2012", con)
我们现在可以从test_db.sqlite中的weather_2012表中读取数据,我们看到我们得到了相同的数据:
con = sqlite3.connect("../data/test_db.sqlite")
df = pd.read_sql("SELECT * from weather_2012 LIMIT 3", con)
df
| | index | Date/Time | Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather |
| --- | --- |
| 0 | 0 | 2012-01-01 00:00:00 | -1.8 | -3.9 | 86 | 4 | 8 | 101.24 | Fog |
| 1 | 1 | 2012-01-01 01:00:00 | -1.8 | -3.7 | 87 | 4 | 8 | 101.24 | Fog |
| 2 | 2 | 2012-01-01 02:00:00 | -1.8 | -3.4 | 89 | 7 | 4 | 101.26 | Freezing Drizzle,Fog |
在数据库中保存数据的好处在于,可以执行任意的 SQL 查询。 这非常酷,特别是如果你更熟悉 SQL 的情况下。 以下是Weather列排序的示例:
| | index | Date/Time | Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather |
| --- | --- |
| 0 | 67 | 2012-01-03 19:00:00 | -16.9 | -24.8 | 50 | 24 | 25 | 101.74 | Clear |
| 1 | 114 | 2012-01-05 18:00:00 | -7.1 | -14.4 | 56 | 11 | 25 | 100.71 | Clear |
| 2 | 115 | 2012-01-05 19:00:00 | -9.2 | -15.4 | 61 | 7 | 25 | 100.80 | Clear |
如果你有一个 PostgreSQL 数据库或 MySQL 数据库,从它读取的工作方式与从 SQLite 数据库读取完全相同。 使用psycopg2.connect()或MySQLdb.connect()创建连接,然后使用
pd.read_sql("SELECT whatever from your_table", con)
9.3 连接到其它类型的数据库
为了连接到 MySQL 数据库:
注:为了使其正常工作,你需要拥有 MySQL/PostgreSQL 数据库,并带有正确的localhost,数据库名称,以及其他。
import MySQLdb con = MySQLdb.connect(host="localhost", db="test")
为了连接到 PostgreSQL 数据库:
import psycopg2 con = psycopg2.connect(host="localhost")