13 数据仓库的设计与ETL开发
文章目录
- 13 数据仓库的设计与ETL开发
- 1.数据仓库的设计
-
- 一、维度建模的基本概念
- 二、维度建模的三种方式
- 三、本项目中数据仓库的设计
-
- 事实表设计
- 维度表设计
- 2.数据仓库ETL开发
-
- 1、ods层建表语句
- 2、ods数据导入
- 3、ods层明细宽表
- 4、统计分析指标
-
- 1.流量分析
-
- 1.1按照来访维度统计pv
- 1.2统计pv总量最大的来源TOPN
- 1.3人均浏览页数
- 2.受访分析
-
- 2.1 各页面pv
- 2.2热门页面统计
- 2.3统计每日最热门页面的top10
- 3.访客分析
- 4.访客visit分析
- 5.hive级联求和
- 6.路径转换(漏斗模型)
13 数据仓库的设计与ETL开发
1.数据仓库的设计
一、维度建模的基本概念
维度表:
时间的维度:昨天
地点:星巴克
金钱的维度:两百块
维度表看到的事情比较狭窄,仅仅从某一个方面来看,只能看得到某一块的东西
事实表:
昨天我去星巴克喝了一杯咖啡,花了两百块
(没发生的东西,一定不是事实,事实一定是建立在已经发生过的事情上面)
二、维度建模的三种方式
星型模型:以事实表为依据,周围很多维度表
订单的分析:用户 货运id 商品id
雪花模型:以事实表为依据 ,很多维度表围绕其中,然后维度表还可能有很多子维度
星座模式:多个事实表有可能会公用一些维度表,最常见的就是我们的省市区的公用
三、本项目中数据仓库的设计
事实表设计
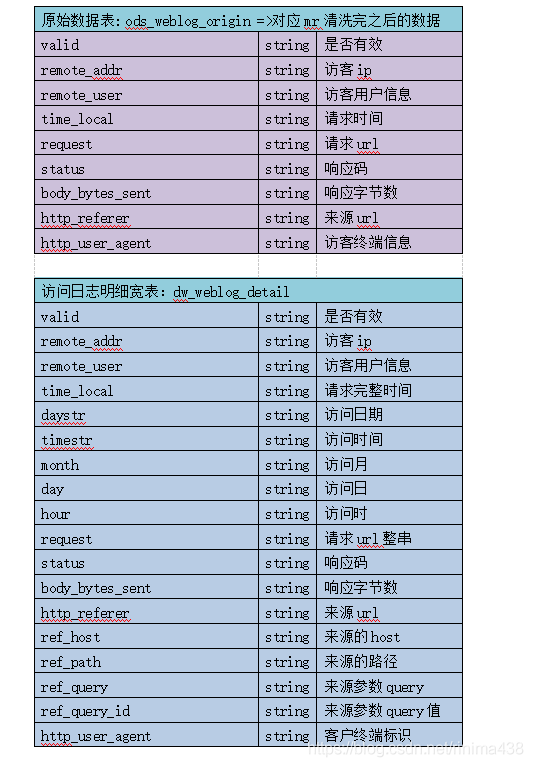
求统计 15:00:00 16:00:00访问了多少个页面
select count(1) from ods_weblog_origin where time_local >= 15:00:00 and time_local <= 16:00:00
union all
select count(1) from ods_weblog_origin where time_local >= 16:00:00 and time_local <= 17:00:00
第一步:按照小时进行分组 15 16 17
第二步:分组之后,统计每组里面有多少天记录
select count(1) from ods_weblog_origin group by hour
为了方便我们的统计,将我们的日期字段给拆成这样的几个字段
将我们的ods_weblog_origin 这个表给拆开,拆我们的时间字段
daystr
timestr
month
day
hour
http_referer http://www.baidu.com/hello.action?username=zhangsan http://www.google.com?address=北京 http://www.sougou.com?money=50
ref_host www.baidu.com
ref_path /hello.action
ref_query username
ref_query_id zhangsan
www.baidu.com
www.google.com
www.sougou.com
维度表设计

注意:
维度表的数据一般要结合业务情况自己写脚本按照规则生成,也可以使用工具生成,方便后续的关联分析。
比如一般会事前生成时间维度表中的数据,跨度从业务需要的日期到当前日期即可.具体根据你的
分析粒度,可以生成年,季,月,周,天,时等相关信息,用于分析。
2.数据仓库ETL开发
1、ods层建表语句
原始数据表:对应mr清洗完之后的数据,而不是原始日志数据
drop table if exists ods_weblog_origin;
create table ods_weblog_origin(
valid string,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
点击流pageview表
drop table if exists ods_click_pageviews;
create table ods_click_pageviews(
session string,
remote_addr string,
remote_user string,
time_local string,
request string,
visit_step string,
page_staylong string,
http_referer string,
http_user_agent string,
body_bytes_sent string,
status string)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
点击流visit表
drop table if exists ods_click_stream_visit;
create table ods_click_stream_visit(
session string,
remote_addr string,
inTime string,
outTime string,
inPage string,
outPage string,
referal string,
pageVisits int)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
2、ods数据导入
设置hive本地模式运行
set hive.exec.mode.local.auto=true;
导入清洗结果数据到贴源数据表ods_weblog_origin
load data local inpath '/export/hivedatas/weblog' overwrite into table ods_weblog_origin partition(datestr='20200918');
show partitions ods_weblog_origin;
select count(*) from ods_weblog_origin;
导入点击流模型pageviews数据到ods_click_pageviews表
load data local inpath '/export/hivedatas/pageview' overwrite into table ods_click_pageviews partition(datestr='20200918');
导入点击流模型visit数据到ods_click_stream_visit表
load data local inpath '/export/hivedatas/visit' overwrite into table ods_click_stream_visit partition(datestr='20200918');
3、ods层明细宽表
建表——明细宽表 ods_weblog_detail
drop table ods_weblog_detail;
create table ods_weblog_detail(
valid string, --有效标识
remote_addr string, --来源IP
remote_user string, --用户标识
time_local string, --访问完整时间
daystr string, --访问日期
timestr string, --访问时间
month string, --访问月
day string, --访问日
hour string, --访问时
request string, --请求的url
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源url
ref_host string, --来源的host
ref_path string, --来源的路径
ref_query string, --来源参数query
ref_query_id string, --来源参数query的值
http_user_agent string --客户终端标识
)
partitioned by(datestr string);
通过查询插入数据到明细宽表 ods_weblog_detail中
分步:
–抽取refer_url到中间表 t_ods_tmp_referurl
–也就是将来访url分离出host path query query id
drop table if exists t_ods_tmp_referurl;
create table t_ods_tmp_referurl as
SELECT a.*,b.*
FROM ods_weblog_origin a
LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id')
b as host, path, query, query_id;
–抽取转换time_local字段到中间表明细表 t_ods_tmp_detail
2013-09-18 06:49:18
drop table if exists t_ods_tmp_detail;
create table t_ods_tmp_detail as
select b.*,
substring(time_local,0,10) as daystr,
substring(time_local,12) as tmstr,
substring(time_local,6,2) as month,
substring(time_local,9,2) as day,
substring(time_local,12,2) as hour
From t_ods_tmp_referurl b;
以上语句可以改写成:
insert into table ods_weblog_detail partition(datestr='20200918')
select c.valid,c.remote_addr,c.remote_user,c.time_local,
substring(c.time_local,0,10) as daystr,
substring(c.time_local,12) as tmstr,
substring(c.time_local,6,2) as month,
substring(c.time_local,9,2) as day,
substring(c.time_local,11,3) as hour,
c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent
from
(SELECT
a.valid,a.remote_addr,a.remote_user,a.time_local,
a.request,a.status,a.body_bytes_sent,a.http_referer,a.http_user_agent,b.ref_host,b.ref_path,b.ref_query,b.ref_query_id
FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as
ref_host, ref_path, ref_query, ref_query_id) c;
show partitions ods_weblog_detail;
4、统计分析指标
1.流量分析
统计每小时的pvs pageview的访问量
分析:
select month,day,hour,count(1) from ods_weblog_detail group by month,day,hour;
实现:
drop table if exists dw_pvs_everyhour_oneday;
create table if not exists dw_pvs_everyhour_oneday(month string,day string,hour string,pvs bigint) partitioned by(datestr string);
insert into table dw_pvs_everyhour_oneday partition(datestr='20200918')
select a.month as month,a.day as day,a.hour as hour,count(*) as pvs from ods_weblog_detail a
where a.datestr='20200918' group by a.month,a.day,a.hour;
统计每天的pvs pageview的访问量
分析:
select month,day,count(1) from ods_weblog_detail group by month,day;
实现:
drop table if exists dw_pvs_everyday;
create table if not exists dw_pvs_everyday(pvs bigint,month string,day string);
insert into table dw_pvs_everyday
select count(*) as pvs,a.month as month,a.day as day from ods_weblog_detail a
group by a.month,a.day;
1.1按照来访维度统计pv
统计每小时各来访url产生的pv量
分析:
select http_referer,ref_host,month,day,hour,count(1) as pv_referer_cnt
from ods_weblog_detail
group by http_referer,ref_host,month,day,hour
实现:
drop table if exists dw_pvs_referer_everyhour;
create table if not exists dw_pvs_referer_everyhour
(referer_url string,referer_host string,month string,day string,
hour string,pv_referer_cnt bigint) partitioned by(datestr string);
insert into table dw_pvs_referer_everyhour partition(datestr='20200918')
select http_referer,ref_host,month,day,hour,count(1) as pv_referer_cnt
from ods_weblog_detail
group by http_referer,ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,pv_referer_cnt desc;
统计每小时各来访host的产生的pv数并排序
drop table dw_pvs_refererhost_everyhour;
create table dw_pvs_refererhost_everyhour(ref_host string,month string,day string,hour string,ref_host_cnts bigint) partitioned by(datestr string);
insert into table dw_pvs_refererhost_everyhour partition(datestr='20200918')
select ref_host,month,day,hour,count(1) as ref_host_cnts
from ods_weblog_detail
group by ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,ref_host_cnts desc;
1.2统计pv总量最大的来源TOPN
–需求:按照时间维度,统计一天内各小时产生最多pvs的来源topN
分组求topN,先分组,再求每组内的topN
hive当中的窗口函数,适用于分组解决topN
分析:
https://www.cnblogs.com/wujin/p/6051768.html
id name sal
1 a 10
2 a 12
3 b 13
4 b 12
5 a 14
6 a 15
7 a 13
8 b 11
9 a 16
10 b 17
11 a 14
orderRank
9 a 16 1 1 1
6 a 15 2 2 2
5 a 14 3 3 3
11 a 14 4 3 3
7 a 13 5 4 5
2 a 12 6 5 6
1 a 10 7 6 7
10 b 17 1
3 b 13 2
4 b 12 3
8 b 11 4
使用hive的开窗函数可以解决标号的问题
rank over
dese_rank over
row_number over
select id,
name,
sal,
rank()over(partition by name order by sal desc ) rp,
dense_rank() over(partition by name order by sal desc ) drp,
row_number()over(partition by name order by sal desc) rmp
from f_test
rp drp rmp
10 b 17 1 1 1
3 b 13 2 2 2
4 b 12 3 3 3
8 b 11 4 4 4
9 a 16 1 1 1
6 a 15 2 2 2
11 a 14 3 3 3
5 a 14 3 3 4
7 a 13 5 4 5
2 a 12 6 5 6
1 a 10 7 6 7
rank over 如果有相同的数据,标号一样 标号根据数据的条数,网上涨
dense_rank over 如果有相同的数,标号一样,标号顺序网上涨
row_number over 如果有相同的数据,标号顺序往上涨
partition by 后面只能跟一个字段
partition by 表示我们要按照哪个字段进行分组 类似于 group by
partition by name order by sal desc ===== group by name order by sal desc
统计一天内每小各来访的host的url的topN
分析:
select ref_host,ref_host_cnts,concat(month,day,hour),
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od
from dw_pvs_refererhost_everyhour;
实现:
drop table dw_pvs_refhost_topn_everyhour;
create table dw_pvs_refhost_topn_everyhour(
hour string,
toporder string,
ref_host string,
ref_host_cnts string
)partitioned by(datestr string);
insert into table dw_pvs_refhost_topn_everyhour partition(datestr='20200918')
select t.hour,t.od,t.ref_host,t.ref_host_cnts from(
select ref_host,ref_host_cnts,concat(month,day,hour) as hour,
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc
) as od
from dw_pvs_refererhost_everyhour
) t where od<=3;
1.3人均浏览页数
计算平均一个人看了多少个页面
第一步:求多少个人 用ip来代表我们每一个人 人数需要去重 1027
分析:
select count(distinct(remote_addr)) from ods_weblog_detail
select count(1) from (
select count(1) from ods_weblog_detail group by remote_addr
) temp_table
实现:
drop table dw_avgpv_user_everyday;
create table dw_avgpv_user_everyday(
day string,
avgpv string);
insert into table dw_avgpv_user_everyday
select '20200918',sum(b.pvs)/count(b.remote_addr)
from
(
select remote_addr,count(1) as pvs from ods_weblog_detail where datestr='20200918'
group by remote_addr
) b;
2.受访分析
网站受到了访问,侧重研究是我们网站的访问的情况
2.1 各页面pv
每个页面,受到了多少次访问
使用request字段来代表我们访问的页面
分析:
select
request,count(1)
from ods_weblog_detail
group by request having request is not null ;
select request as request,count(1) as request_counts from
ods_weblog_detail group by request having request is not null order by
request_counts desc limit 20;
2.2热门页面统计
统计20200918这个分区里面的受访页面的top10
drop table dw_hotpages_everyday;
create table dw_hotpages_everyday(day string,url string,pvs string);
insert into table dw_hotpages_everyday
select '20200918',a.request,a.request_counts from
(
select request as request,count(request) as request_counts
from ods_weblog_detail
where datestr='20200918'
group by request
having request is not null
) a
order by a.request_counts desc limit 10;
2.3统计每日最热门页面的top10
注意如果有很多天的数据,那么就涉及到分组求topN
20200918
法1:
select month,day,request,count(1) as total_result
from ods_weblog_detail where datestr = '20200918' group by month,day,request
order by total_result desc limit 10;
法2:
select a.month,a.day,a.request ,concat(a.month,a.day),a.total_request
from (
select month,day, request,count(1) as total_request
from ods_weblog_detail
where datestr = '20130918'
group by request ,month ,day
having request is not null
order by total_request desc limit 10
) a
3.访客分析
对我们的用户进行分析
1、-- 独立访客
–需求:按照时间维度来统计独立访客及其产生的pv量
分析:
时间维度 加上独立访客ip 产生的pv量
select month,day,hour,remote_addr,
count(1)
from ods_weblog_detail
group by month,day,hour ,remote_addr;
按照天的维度,统计独立访客及其产生的PV量
select month,day,hour,remote_addr,
count(1)
from ods_weblog_detail
group by month,day ,remote_addr;
实现:
drop table dw_user_dstc_ip_h;
create table dw_user_dstc_ip_h(
remote_addr string,
pvs bigint,
hour string);
insert into table dw_user_dstc_ip_h
select remote_addr,count(1) as pvs,concat(month,day,hour) as hour
from ods_weblog_detail
Where datestr='20200918'
group by concat(month,day,hour),remote_addr;
2、–每日新访客
– 需求:将每天的新访客统计出来。

–历史去重访客累积表
drop table dw_user_dsct_history;
create table dw_user_dsct_history(
day string,
ip string)
partitioned by(datestr string);
–每日新访客表
drop table dw_user_new_d;
create table dw_user_new_d (
day string,
ip string)
partitioned by(datestr string);
分析:
select a.remote_addr ,a.day
from (
select remote_addr,'20200918' as day
from ods_weblog_detail newIp
where datestr ='20200918'
group by remote_addr
) a
left join dw_user_dsct_history hist
on a.remote_addr = hist.ip
where hist.ip is null;
–每日新用户插入新访客表
insert into table dw_user_new_d partition(datestr='20200918')
select tmp.day as day,tmp.today_addr as new_ip
from
(
select today.day as day,today.remote_addr as today_addr,old.ip as old_addr
from
(
select distinct remote_addr as remote_addr,"20200918" as day
from ods_weblog_detail where datestr="20200918"
) today
left outer join
dw_user_dsct_history old
on today.remote_addr=old.ip
) tmp
where tmp.old_addr is null;
–每日新用户追加到历史累计表
insert into table dw_user_dsct_history partition(datestr='20200918')
select day,ip from dw_user_new_d where datestr='20200918';
4.访客visit分析
分析的是我们一天之内访问了多少次session
1、-- 回头/单次访客统计
单次访客的统计
如果ip访问的次数,大于1 说明在多个session里面都出现了这个ip,说明是回头访客
分析:
select remote_addr ,count(remote_addr) ipcount
from ods_click_stream_visit
group by remote_addr
having ipcount > 1
实现:
drop table dw_user_returning;
create table dw_user_returning(
day string,
remote_addr string,
acc_cnt string)
partitioned by (datestr string);
insert overwrite table dw_user_returning partition(datestr='20200918')
select tmp.day,tmp.remote_addr,tmp.acc_cnt
from
(select '20200918' as day,remote_addr,count(session) as acc_cnt from ods_click_stream_visit
group by remote_addr) tmp
where tmp.acc_cnt>1;
2、–人均访问频次,
平均一个人,访问了多少次
求人数
select count(1) from ods_click_stream_visit/ select count(distinct(remote_addr)) from ods_click_stream_visit
select count(session)/count(distinct remote_addr) from ods_click_stream_visit where datestr='20200918';
求访问的次数:使用所有的独立访问的人,即独立的session个数除以所有的去重IP即可
3、-- 人均页面浏览量
所有的页面点击次数累加除以所有的独立去重IP总和即可
select sum(pagevisits)/count(distinct (remote_addr))
from ods_click_stream_visit;
pagevisits 这个字段记录了我们这次会话里面访问了多少个页面
10 每个会话访问 10 个页面
50 个会话
5.hive级联求和
create table t_salary_detail(username string,month string,salary int)
row format delimited fields terminated by ',';
load data local inpath '/export/servers/hivedatas/accumulate/t_salary_detail.dat' into table t_salary_detail;
用户 时间 收到小费金额
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,7
A,2015-03,9
B,2015-03,11
B,2015-03,6
select username,month, sum(salary)
from t_salary_detail
group by username,month
需求:统计每个用户每个月总共获得多少小费
select t.month,t.username,sum(salary) as salSum
from t_salary_detail t
group by t.username,t.month;
+----------+-------------+---------+--+
| t.month | t.username | salsum |
+----------+-------------+---------+--+
| 2015-01 | A | 33 |
| 2015-02 | A | 10 |
| 2015-03 | A | 16 |
| 2015-01 | B | 30 |
| 2015-02 | B | 15 |
| 2015-03 | B | 17 |
+----------+-------------+---------+--+
需求:统计每个用户累计小费
累计求和其实就是使用到了inner join通过自己连接自己来实现
使用inner join 实现自己关联自己
select
a.* ,b.*
from (
select username,month, sum(salary)
from t_salary_detail
group by username,month
) a inner join (
select username,month, sum(salary)
from t_salary_detail
group by username,month
) b on a.username = b.username
+-------------+----------+--------+-------------+----------+--------+--+
| a.username | a.month | a._c2 | b.username | b.month | b._c2 |
+-------------+----------+--------+-------------+----------+--------+--+
| A | 2015-01 | 33 | A | 2015-01 | 33 | 33
1 1
| A | 2015-02 | 10 | A | 2015-01 | 33 | 43
| A | 2015-02 | 10 | A | 2015-02 | 10 |
2 1 2
| A | 2015-03 | 16 | A | 2015-01 | 33 | 59
| A | 2015-03 | 16 | A | 2015-02 | 10 |
| A | 2015-03 | 16 | A | 2015-03 | 16 |
3 1 2 3
| B | 2015-01 | 30 | B | 2015-01 | 30 |
| B | 2015-01 | 30 | B | 2015-02 | 15 |
| B | 2015-01 | 30 | B | 2015-03 | 17 |
| B | 2015-02 | 15 | B | 2015-01 | 30 |
| B | 2015-02 | 15 | B | 2015-02 | 15 |
| B | 2015-02 | 15 | B | 2015-03 | 17 |
| B | 2015-03 | 17 | B | 2015-01 | 30 |
| B | 2015-03 | 17 | B | 2015-02 | 15 |
| B | 2015-03 | 17 | B | 2015-03 | 17 |
+-------------+----------+--------+-------------+----------+--------+--+
select sum (bSalsum) from(
select
A.month as amonth ,A.username as aUsername ,A.salsum as aSalsum ,B.month as bmonth ,b.username as bUsername ,b.salsum as bSalsum
from
(select t.month,t.username,sum(salary) as salSum
from t_salary_detail t
group by t.username,t.month) A
inner join
(select t.month,t.username,sum(salary) as salSum
from t_salary_detail t
group by t.username,t.month) B
on A.username = B.username
where B.month <= A.month
) t group by aUsername, amonth;
6.路径转换(漏斗模型)
求两个指标:
第一个指标:每一步相对于第一步的转化率
第二个指标:每一步相对于上一步的转化率
# 使用模型生成的数据,可以满足我们的转化率的求取
load data inpath '/weblog/clickstream/pageviews/click-part-r-00000' overwrite into table ods_click_pageviews partition(datestr='20130920');
---1、查询每一个步骤的总访问人数
Step1、 /item 1000 相对上一步 相对第一步 1000
Step2、 /category 800 0.8 0.8 1800
Step3、 /index 500 0.625 0.5 2300
Step4、 /order 100 0.2 0.1 2400
create table dw_oute_numbs as
select 'step1' as step,count(distinct remote_addr) as numbs from ods_click_pageviews
where datestr='20130920'
and request like '/item%'
union all
select 'step2' as step,count(distinct remote_addr) as numbs from ods_click_pageviews
where datestr='20130920'
and request like '/category%'
union all
select 'step3' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920'
and request like '/order%'
union all
select 'step4' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920'
and request like '/index%';
+---------------------+----------------------+--+
| dw_oute_numbs.step | dw_oute_numbs.numbs |
+---------------------+----------------------+--+
| step1 | 1029 |
| step2 | 1029 |
| step3 | 1028 |
| step4 | 1018 |
+---------------------+----------------------+--+
--2、查询每一步骤相对于路径起点人数的比例
--级联查询,自己跟自己join
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn
inner join
dw_oute_numbs rr;
产生笛卡尔积之后,加条件限制 b.step='step1'
+---------+----------+---------+----------+--+
| rnstep | rnnumbs | rrstep | rrnumbs |
+---------+----------+---------+----------+--+
| step1 | 1029 | step1 | 1029 |
| step2 | 1029 | step1 | 1029 |
| step3 | 1028 | step1 | 1029 |
| step4 | 1018 | step1 | 1029 |
| step1 | 1029 | step2 | 1029 |
| step2 | 1029 | step2 | 1029 |
| step3 | 1028 | step2 | 1029 |
| step4 | 1018 | step2 | 1029 |
| step1 | 1029 | step3 | 1028 |
| step2 | 1029 | step3 | 1028 |
| step3 | 1028 | step3 | 1028 |
| step4 | 1018 | step3 | 1028 |
| step1 | 1029 | step4 | 1018 |
| step2 | 1029 | step4 | 1018 |
| step3 | 1028 | step4 | 1018 |
| step4 | 1018 | step4 | 1018 |
+---------+----------+---------+----------+--+
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn
inner join
dw_oute_numbs rr where rr.step='step1';
+---------+----------+---------+----------+--+
| rnstep | rnnumbs | rrstep | rrnumbs |
+---------+----------+---------+----------+--+
| step1 | 1029 | step1 | 1029 |
| step2 | 1029 | step1 | 1029 |
| step3 | 1028 | step1 | 1029 |
| step4 | 1018 | step1 | 1029 |
+---------+----------+---------+----------+--+
select t.rnnumbs/t.rrnumbs from(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn
inner join
dw_oute_numbs rr where rr.step='step1'
) t ;
+---------------------+--+
| _c0 |
+---------------------+--+
| 1.0 |
| 1.0 |
| 0.9990281827016521 |
| 0.989310009718173 |
+---------------------+--+
再求取每一步相对于上一步的转化率
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn
inner join
dw_oute_numbs rr
where cast(substr(rn.step,5,1) as int)=cast(substr(rr.step,5,1) as int)-1;
+---------+----------+---------+----------+--+
| rnstep | rnnumbs | rrstep | rrnumbs |
+---------+----------+---------+----------+--+
| step1 | 1029 | step2 | 1029 |
| step2 | 1029 | step3 | 1028 |
| step3 | 1028 | step4 | 1018 |
+---------+----------+---------+----------+--+
select t.rrnumbs/t.rnnumbs
from(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn
inner join
dw_oute_numbs rr
where cast(substr(rn.step,5,1) as int)=cast(substr(rr.step,5,1) as int)-1
) t;
+---------------------+--+
| _c0 |
+---------------------+--+
| 1.0 |
| 0.9990281827016521 |
| 0.9902723735408561 |
+---------------------+--+
汇总每一步相对于上一步与每一步相对于第一步
select abs.step,abs.numbs,abs.rate as abs_ratio,rel.rate as leakage_rate
from
(
select tmp.rnstep as step,tmp.rnnumbs as numbs,tmp.rnnumbs/tmp.rrnumbs as rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where tmp.rrstep='step1'
) abs
left outer join
(
select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1
) rel
on abs.step=rel.step;