集成学习Task12 Blending集成学习算法
文章目录
- 1. 引言
- 2. Blending 集成学习算法
- 3. 代码实现
- 4. 使用iris数据完成blending
参考来源:https://github.com/datawhalechina/team-learning-data-mining/tree/master/EnsembleLearning
1. 引言
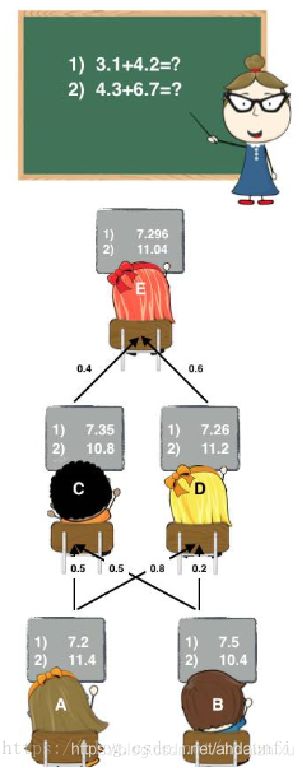
先引用大佬的一个例子来简单介绍一下blending的思想。这是一个上课的例子,学生E不会做题,于是同学们都来帮忙。如图可以看到,首先是A和B同学进行计算,他俩计算的结果其实和真实值有一些差距。之后他们将自己的计算结果告诉C和D。这时,可以看到,C和D接受两个结果的权值不同,所以C和D也得到了两个不同答案。最后,E再参考C和D的答案,根据自己的判断决定谁的答案权重大一些,谁的小一些,综合起来,告诉老师自己最后的答案。虽然,E的这个答案,和真实答案还是有些差距,但是和之前的ABCD比起来,已经精确了不少。
Blending的思想和这个类似,通过很多个不同同学的“帮忙”,学习他们的经验,最后得出自己的答案。其实该例子最相似的一点还是Blending也是分成了两层进行计算。
2. Blending 集成学习算法
这里先引用一下别人的说法:https://blog.csdn.net/sinat_35821976/article/details/83622594
Blending流程大致分为以下几步:
- 将数据划分为训练集和测试集(test_set),其中训练集需要再次划分为训练集(train_set)和验证集(val_set);
- 创建第一层的多个模型,这些模型可以使同质的也可以是异质的;
- 使用train_set训练步骤2中的多个模型,然后用训练好的模型预测val_set和test_set得到val_predict, test_predict1;
- 创建第二层的模型,使用val_predict作为训练集训练第二层的模型;
- 使用第二层训练好的模型对第二层测试集test_predict1进行预测,该结果为整个测试集的结果
图解Blending

理解了吗?没有?好的,其实这些说法我一开始也不太好理解,下面详细说说。
首先,我们要对Blending有一个整体性的把握。在引言中说到,Blending其实有两层模型,所有的输入数据都是输入第一层模型,第二层模型的输入其实是第一层模型的输出。
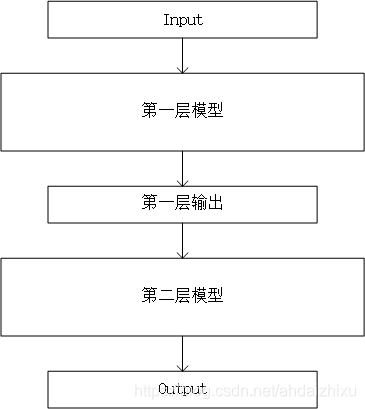
首先,所有数据都会输入第一层模型,但是这个数据会进行一定的处理。
对于所有的输入数据,我们将输入数据划分为训练集训练集和测试集(test_set),其中训练集需要再次划分为训练集(train_set)和验证集(val_set)。比如,首先按照80%训练集和20%测试集(test_set)的比例进行第一次划分,然后在这80%的训练集中,再按照70%训练集(train_set)和30%验证集(val_set)划分。因此拆分后的数据集由三部分组成:训练集80%* 70% 、测试集20%、验证集80%* 30% 。
第2步,创建多个模型,它们可以是同质的,也可以是异质的,都属于第一层模型。
第3步,使用train_set对模型进行训练,训练完成后,用训练好的模型预测val_set和test_set得到val_predict, test_predict1。这里我们将val_predict记作 A 1 , . . . , A K A_1,...,A_K A1,...,AK,test_predict1记作 B 1 , . . . , B K B_1,...,B_K B1,...,BK。
第4步,从这里开始,进入第二层模型的计算。
我们使用验证集结果 A 1 , . . . , A K A_1,...,A_K A1,...,AK作为第二层分类器的特征,验证集的标签为因变量,对第二层模型进行训练。
第5步,使用训练好的模型预测test_predict1,得到test_predict,即为最终预测结果。
3. 代码实现
首先,使用自己创建的数据集来实现一下blending,看看blending的流程。
# 加载相关工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
import seaborn as sns
# 创建数据
from sklearn import datasets
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
#make_blobs:生成高斯聚类数据
data, target = make_blobs(n_samples=10000, centers=2, random_state=1, cluster_std=1.0 )
# 划分训练集与测试集,其中,两两为一组划分数据,比如在如下代码中,x_train1和X_test划分data,y_train1和y_test划分target
# 将其写在一起的作用是x_train1对data的划分和y_train1对target的划分是一一对应的。
X_train1,X_test,y_train1,y_test = train_test_split(data, target, test_size=0.2, random_state=1)
# 将训练集再次划分为训练集与验证集
X_train,X_val,y_train,y_val = train_test_split(X_train1, y_train1, test_size=0.3, random_state=1)
## 查看一下我们生成的数据
print("The shape of training X:",X_train.shape)
print("The shape of training y:",y_train.shape)
print("The shape of test X:",X_test.shape)
print("The shape of test y:",y_test.shape)
print("The shape of validation X:",X_val.shape)
print("The shape of validation y:",y_val.shape)
print(X_train[0:5])
print(y_train[0:5])
print(X_test[0:5])
print(y_test[0:5])
print(X_val[0:5])
print(y_val[0:5])

下面来设置分类器:
# 设置第一层分类器
# 第一层分类器使用svm,随机森林和KNN
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
clfs = [SVC(probability = True),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),KNeighborsClassifier()]
# 设置第二层分类器
# 第二层分类器使用逻辑回归
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
# 输出第一层的验证集结果与测试集结果
# np.zeros返回来一个给定形状和类型的用0填充的数组;
val_features = np.zeros((X_val.shape[0],len(clfs))) # 初始化验证集结果
test_features = np.zeros((X_test.shape[0],len(clfs))) # 初始化测试集结果
#enumerate() 函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
#使用训练数据集对第一层模型的每一个模型进行训练,每一个模型的训练数据相同
for i,clf in enumerate(clfs):
clf.fit(X_train,y_train)
val_feature = clf.predict_proba(X_val)[:, 1]
test_feature = clf.predict_proba(X_test)[:,1]
val_features[:,i] = val_feature
test_features[:,i] = test_feature
# 将第一层的验证集的结果输入第二层训练第二层分类器
lr.fit(val_features,y_val)
# 使用交叉验证对预测结果进行评分
from sklearn.model_selection import cross_val_score
cross_val_score(lr,test_features,y_test,cv=5)
![]()
4. 使用iris数据完成blending
#导入iris数据
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
features = iris.feature_names
iris_data = pd.DataFrame(X,columns=features)
iris_data['target'] = y
iris_data.head(10)
# 数据预处理
# 仅仅考虑0,1类鸢尾花
iris_data = iris_data.loc[iris_data.target.isin([0, 2])]
y = iris_data['target'].values
X = iris_data[['sepal length (cm)', 'sepal width (cm)']].values
# 将分类标签变成二进制编码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# 划分训练集、验证集、测试集
X_train1,X_test,y_train1,y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 将训练集再次划分为训练集与验证集
X_train,X_val,y_train,y_val = train_test_split(X_train1, y_train1, test_size=0.3, random_state=1)
val_features1 = np.zeros((X_val.shape[0],len(clfs))) # 初始化验证集结果
test_features1 = np.zeros((X_test.shape[0],len(clfs))) # 初始化测试集结果
for i,clf in enumerate(clfs):
#先使用训练集训练模型
clf.fit(X_train,y_train)
#分别将验证集和测试集数据输入模型,得出每一行数据预测为1的概率
val_feature = clf.predict_proba(X_val)[:,1]
test_feature = clf.predict_proba(X_test)[:,1]
#将第一层模型的每个模型的结果合并,作为第二层模型的训练和测试数据
val_features1[:,i] = val_feature
test_features1[:,i] = test_feature
# 将第一层的验证集的结果输入第二层训练第二层分类器
lr.fit(val_features1,y_val)
# 输出预测的结果
# 使用五折交叉验证进行验证
from sklearn.model_selection import cross_val_score
cross_val_score(lr,test_features1,y_test,cv=5)
