决策树:
ID3:其核心是在决策树的各级节点上,实用信息增益(information gain)作为属性的选择标准,来帮助确定生成每个节点是所应采用的合适属性。ID3只是用于处理离散的描述属性。
C4.5: 相对于ID3的改进是使用信息增益率来选择节点属性。C4.5技能处理离散的描述属性,也能处理连续的描述属性。
CART:是一种十分有效的非参数分类和回归方法,通过构建树、修剪树、评估树来构建二叉树。当终结点是连续变量时,该树为回归树;当终结点是分类变量时,该树为分类树。
ID3:基于信息增益选择最佳属性,构造一棵信息熵值下降最快的树,树不断构建的过程也就是熵不断下降的过程。
信息熵:H(X) 描述X携带的信息量。 信息量越大(值变化越多,把事情搞清楚所需要的信息量就越多),则越不确定,越不容易被预测。表示随机变量的不确定性。
条件熵:在一个条件下,随机变量的不确定性。
信息增益IG(Y|X): 衡量一个属性(x)区分样本(y)的能力;在一个条件下,信息不确定性减少的程度。 当新增一个属性(x)时,信息熵H(Y)的变化大小即为信息增益。 IG(Y|X)越大表示x越重要。
信息增益例子:明天下雨例如信息熵是2,条件熵(下雨|阴天)是0.01(因为如果是阴天就下雨的概率很大,信息就少了),这样相减后为1.99,在获得阴天这个信息后,下雨信息不确定性减少了1.99!是很多的!所以信息增益大!也就是说,阴天这个信息对下雨来说是很重要的!
采用划分后样本集的不确定性来作为衡量划分好坏的标准,用信息增益值度量不确定性:信息增益越大,不确定性就越小。ID3在每个非叶节点选择信息增益最大的属性作为测试属性,这样可以得到当前情况下最纯(最极端的情况是每个叶子节点只有一个样本)的拆分,从而得到较小的决策树。
定义:特征A对训练集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差:
可以转化得到:
建模步骤:
1. 对当前样本集合,计算所有属性的信息增益
2. 选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本化为同一个样本集
3. 若子样本集的类别墅型只有单个属性,则为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本集本算法
C4.5: 基于信息增益率(gain ratio)的ID3改进版。ID3不足在于选择具体特征作为节点的时候,它会偏向于选择取值较多的特征。一个极端情况是:以是否出去玩为例,假设新来的一列特征为partner,有n个取值,且每个取值只有一条记录,则特征的信息熵为0,
这样的信息增益是最大的,必然选择此特征为节点,但是结果是树很庞大而深度很浅,泛化预测能力较差。
IV(A): 属性A的可能取值数目越多,则IV(A)的值通常越大。
这里的IV(A)也叫做split information
*注:
增益率准则对可取值数目较小的特征有所偏好,所以C4.5并不是直接选增益率最大的候选划分特征,而是使用了一个启发式:先从候选划分特征中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
对连续属性的处理如下:
1. 对特征的取值进行升序排序
2. 两个特征取值之间的中点作为可能的分裂点,将数据集分成两部分,计算每个可能的分裂点的信息增益(InforGain)。优化算法就是只计算分类属性发生改变的那些特征取值。
3. 选择修正后信息增益(InforGain)最大的分裂点作为该特征的最佳分裂点
4. 计算最佳分裂点的信息增益率(Gain Ratio)作为特征的Gain Ratio。注意,此处需对最佳分裂点的信息增益进行修正:减去log2(N-1)/|D|(N是连续特征的取值个数,D是训练数据数目,此修正的原因在于:当离散属性和连续属性并存时,C4.5算法倾向于选择连续特征做最佳树分裂点)
CART(Classification And Regression Tree): 使用基尼指数(Gini index)来选择划分特征。该算法是一种二分递归分割法,把挡墙的样本集合划分为两个子集合,它生成的每个非叶子节点都只有两个分支(binary tree)。
基尼指数:表示数据的不纯度性,基尼指数越大,越不平等。总体内包含的类别越杂乱,GINI指数就越大(跟熵的概念很相似)
给定一个数据集D,其中包含的分类类别总数为K,类别k在数据集中的个数为|C|,其Gini指数表示为:
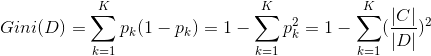

在候选特征集合A中,选择那个使得划分后基尼指数最小的特征为最优化分数性,即:
a* = arg min GiniIndex(D,a)
小节:
算法 支持模型 树结构 特征选择 连续值处理 缺失值处理 剪枝 样本量
ID3 分类 多叉树 信息增益 不支持 不支持 不支持 /
C4.5 分类 多叉树 信息增益比 支持 支持 支持 小样本(大样本耗时)
CART分类|回归 二叉树 基尼系数|均方差 支持 支持 支持 大样本(小样本泛化误差大)
决策树算法优缺点:
优点:
1.简单直观
2.基本不需要数据预处理,归一化,处理缺失值
3.预测代价O(logm),m为样本数
4.适用于离散和连续数据
4.逻辑上可以较好的解释,相较于神经网络的黑盒
5.可以用交叉验证的剪枝来提高泛化能力
6.对异常点容错能力好
缺点:
1.非常容易过拟合。可以通过设置节点样本数量和先知决策树深度以及后剪枝来改进
2.树的结构会因为样本的一点点改动而剧烈改变。可以通过集成学习方法改进
3.因为是贪心算法,只能确定局部最优。通过集成学习改进
4.如果某特征样本比例过大,生成的决策树容易偏向这些特征,造成欠拟合。可以通过调节样本权重来改进。
信息熵越大,不纯度越高,信息越杂乱
剪枝pruning
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化能力(在训练时加入验证集随时进行泛化验证)的提升,则停止划分并将当前结点标记为叶节点。
根据不同决策树算法,防止过拟合的参数有一些不同,但max_depth是通用的;其他的一些参数:
min_samples_split:节点在分裂之前必须具有的最小样本数。也就是,如果该节点上的样本数量小于参数设置的数目时,不管怎样,这个节点也不再分裂。
min_samples_leaf:叶节点必须拥有的最少样本数。如果分裂一个节点生成一些叶子,而某个叶子上的样本数量少于参数设置的值时,将不将这些样本单独作为一个叶子。
min_weight_fraction_leaf:和上面一个参数差不多,但表示为加权实例总数的一小部分。
max_leaf_nodes:叶子节点的最大数量。
后剪枝则是先从训练集中生成一颗完整的树,然后自底向上对非叶节点进行考察,若该节点对应的子树替换为叶节点能够提升泛化能力,则进行剪枝将该子树替换为叶节点,否则不剪枝。
评价函数:类似损失函数,越小越好。
随机森林random forest
bootstraping:有放回的抽样
bagging:有放回的采样n个样本建立一个分类器