MPEG-CDVS标准概述论文粗译 Overview of the MPEG-CDVS Standard
Overview of the MPEG-CDVS Standard论文粗译,仅为自己学习所用,参考需谨慎。
摘要
CDVS标准,Compact Descriptors for visual search,视觉搜索紧凑描述子,是ISO/IEC运动图像专家组即MPEG最近发布的一个完整的标准。此标准的主要目标是提供一套标准化的比特流语法实现图像搜索应用的上下文中的互操作性。标准化的过程在减小图像特征数据,以及减少特征提取过程中的计算量和降低内存占用(memory footprint)方面取得了显著的进步与提高。本篇论文对MPEG-CDVS标准的技术特征(technical features)做了概述,并总结了它的制定过程。
关键词
紧凑描述子(compact descriptors),特征压缩(feature compression),MPEG-CDVS,视觉搜索(visual search)
INTRODUCTION
略,主要是讲最近十年移动智能设备普及,移动视觉搜索需要做得更快更准确。
首先,移动设备上的处理过程必须快,轻量级,耗电少;其次,通过网络传输的数据量必须要小到足够降低网络延迟;最后,搜索和匹配所使用的算法,对于潜在可能出现的极大规模数据库必须是可伸缩的(scalable),并且在部分遮挡,视角变化,相机参数的光照变化的情况下,对目标的识别保有鲁棒性。
……略
理想中的MPEG-CDVS标准应该具备以下特性
- 确保视觉搜索应用和数据库的互操作性
- 减少无线网络传输视觉搜索相关信息的负载
- 提供一套在移动设备上进行硬件支持的描述子提取和匹配的基本方法。
- 能够使与标准相一致的实现(implementations)有高水平表现。
- 简化视觉搜索应用中的描述子提取和匹配设计。
并且,理想中的表中应该能同其他已经存在的MPEG和JPEG标准结合使用,比如说,MPEG Query Format,HTTP,XML,JPEG,以及JPSearch。
略……
HIGHLIGNTS
MPEG-CDVS标准定义了描述子的比特流(比如说,二进制表示语法),以及描述子的提取过程。图2中描述了这一标准的主要构成模块。

为了保证兼容性,描述子的语法需要与CDVS标准相一致。
CDVS通过两种方式支持互操作性。第一种是,它标准化了描述子的比特流语法。第二种是它提供了在不同位率下编码描述子并匹配的框架。后一种特征考虑到了一个存有压缩特征的紧凑数据库(什么?),以及搜索的位率可伸缩性。
检索和匹配的算法并不在标准中。视频压缩专家会注意到这个方法是应用于(Video compression experts will note that the approach is the dual of what is performed for video coding standards in which the bitstream syntax and the decoder are standardized)。对于CDVS来说,比特流语法和编码器是被标准化了的。图2中的模块是保证互操作性所需要的最少模块。
A. Data Sets and Evaluation
CDVS的评价数据集是一份比其他像INRIA Holidays和Oxford Buildings这样的流行数据集规模更大的数据集。这个数据集与INRIA Holidays和Oxford Buildings相比,拥有更多的包含不同类型的物体,尺度,旋转,遮挡和光照情况的数据。成对匹配和搜索实验都纳入了评价框架之中,性能也作为位率的一种功能(a function of bitrate?)纳入其中。数据集中有10155个匹配图像对和112175个不匹配图像对的标准数据(ground-truth data)用作成对匹配的评价;还有8314幅待搜索图像和18840幅参考图像,以及从Filckr中得来的规模为一百万幅图像的干扰数据集用作图像检索实验。
B.Interest Point Detection and Local Feature Description兴趣点检测和局部特征描述
CDVS标准在使用了流行的SIFT描述子后,应用了一种低阶多项式(low-degree polynomial,ALP)的检测子。为了找到兴趣点,ALP方法使用多项式估计了LoG(高斯拉普拉斯)滤波的结果,这种方法在尺度空间中寻找极值,改善检测到的点的空间位置。虽然没有被标准采用,但是一个基于分块的频率域高斯拉普拉斯方法可以与ALP检测子整合实现一个基于分块的尺度空间兴趣点检测子ALP_BFLoG。ALP_BFLoG方法将原始的尺度空间分割成重叠的块,并对每块做独立的兴趣点检测,从而使滤波器所需的内存开销和尺度空间缓存降低了一个数量级。基于分块的兴趣点检测使整个流水线在低内存开销的硬件实现中经得起检验。
C. Local Feature Selection 局部特征选择
一个特征描述子的自己被选取出来,以满足不同描述子长度的速率约束。每个局部特征都要计算表明一个待搜索特征与数据库特征相匹配的可能性的相关性。计算相关性的方法是统计学习的(statistically learned),以尺度,LoG的峰值响应(peak response)每个局部特征与图像中心的距离,以及其他文章后续将会讨论的特性为基础。各个特征会基于相关性排序,然后根据总共的特征数据预算和每个特征所占位数,选出数量固定的一部分特征。
D. Local Feature Descriptor Compression 局部特征描述子压缩
CDVS标准中采用了一种低复杂度的变换编码的方法。三元标量量化(ternary scalar quantization)和瞬时变长编码(instantaneous variable-length coding)完成后,描述子再做变换。此方法对SIFT描述子的8个方位上的值做小型的线性变换,而不是对整个描述子做变换。比特流中只包含变换后的描述子元素的一个子集。这个子集根据标准化的优先级表被选择出来,并且这个表格已经为了得到最佳搜索性能而优化过了。(This subset is selected according to a standardized priority table that has been optimized for the best retrieval performance.)对于图像描述子长度从最短的512到1024B到最长的16384B来说,转换后的描述子包含的元素的个数(?)从20/128到128/128不等。
E. Local Feature Location Compression 局部特征位置压缩
CDVS标准中的位置信息编码模式是基于这样一个基本观点:特征的原始排序可以被舍弃,从而在熵编码的比特流之外为n个特征节省log(n!)位(?)。直方图编码模式被采用,这种模式基于x,y坐标重新对特征数据进行了排序,节省了log(n!)的排序开销(?)。位置数据以直方图的形式出现,直方图由二进制映射和一组直方图计数组成。直方图映射和计数使用一种二进制的基于上下文的算术编码模式进行编码。
F. Local Feature Descriptor Aggregation 局部特征描述子聚合
CDVS标准中采用了一种可伸缩的压缩费舍尔向量方法(scalable compressed Fisher Vector SCFV)进行局部特征描述子的聚合。为了压缩高维的费舍尔向量,此方法从高斯混合模型(Gaussian Mixture Model GMM)中选了高斯成分的一个子集,并且只保留了被选择出来的这些成分的信息。不同的高斯成分的集合是根据每一幅图像费舍尔向量能量最集中的部分选择出的。一个小规模的首部数据位的集合表明哪些成分被选出做每一个聚合的全局特征。SCFV算法有较高的匹配准确度,以及与传统的基于PCA主成分分析或者向量量化的费舍尔向量压缩方法相比,有着几乎可以忽略的内存开销。
NORMATIVE BLOCKS 正式模块
A. Interest Point Detection and Local Feature Description 兴趣点检测和局部特征描述
局部特征提取包括检测兴趣点和使用特征描述子刻画这些兴趣点—-描述尺度和旋转不变块(rotation invariant patches)的的高维呈现。CDVS标准在使用了流行的SIFT描述子之后使用了LoG高斯拉普拉斯尺度空间兴趣点检测子。图像的尺度空间以图像金字塔的形式展现,图像金字塔中,an image is successively filtered by a family of smoothing kernels at increasing scale factors. 图像金字塔中每一个尺度的归一化导数都将被计算出来,兴趣点也通过在尺度空间中寻找局部极值被计算出来。
这一标准最重要的创新点就是基于多项式近似的LoG兴趣点检测子。被采纳的低维多项式ALP方法估测了LoG滤波的结果。随后,寻找并改善尺度空间的极值以计算被检测到的点的精确的空间位置。特别地,为了估计LoG尺度空间,ALP使用了一个与尺度参数 σ 和图像中的每一个像素点的(x,y)坐标相关的多项式函数:
系数a k,b k,c k和d k存储在一张标准表中, K=4(待写)
为了检测出尺度空间的极值,ALP方法首先通过使 σ 方向上的导数为0得出局部极值,然后将这个极值点与它在X-Y平面上的8个邻居点相比较。
与其他模式相比较:ALP的兴趣点检测比传统的尺度空间极值检测子方法—-将每一个点与在尺度空间中相邻的3 × 3 × 3-1=26个邻居点比较,更为高效,因为ALP方法是建立在用4幅LoG滤波图像估计LoG尺度空间的基础上,而不是用在LoG检测子中使用5幅或以上的LoG滤波图像或者是在典型的DoG高斯差分尺度空间中使用6幅以上的高斯滤波图像。
B. Local Feature Selection局部特征选择
在图像内容的基础上,兴趣点检测部分会产生成百上千的特征,即使是对于VGA分辨率的图像来说。512B到4KB的特征数据不足以包含所有的特征,即使每个描述子的位数都足够短。因此,选取特征描述子的子集就很重要。做特征选择也有其他的优势。局部特征描述子会聚合成为全局特征描述子。合并噪声多的局部描述子会降低全局描述子的取分离。并且,特征选择还可以在特征提取模块有效降低计算开销:CDVS标准之中,对每一个局部特征都会计算一个相关性。相关性表明了一个待搜索特征与一个数据库特征相匹配的先验概率。比如说,距离图像中心更近的待搜索特征更加容易匹配。相似的,从特征更显著区域提取的特征更加特殊和更具有区分力。相关性是基于兴趣点的五个特征用统计学习的方法得到的:兴趣点的尺度 σ ,LoG的峰值响应值p,兴趣点到图像中心的距离d,Hessian矩阵行列式的??the ratio ρ of the squared trace to the determinant of the Hessian.以及关于尺度的尺度空间函数的二阶导数 pσσ 。
通过假设在给定特征匹配的情况下不同的兴趣点特征是条件独立的,在标准化期间,使用独立的数据集针对每个特征学习特征匹配的条件分布。这些学习条件分布的参数,被间隔两化,并在标准表中列出,每一个量化间隔都在标准表中有一个相关的标量。为了学习这个条件分布,在大量匹配图像对的数据集上应用SIFT特征成对特征匹配和比率测试,以及几何一致性检验,得到一个匹配和不匹配的特征对的集合。这个匹配过程使用ALP方法做检测子,使用SIFT(未压缩)做描述子。在几何验证中,匹配图像对的inliers(有效数据,内点)被设置成一个比较紧的阈值—-30,以保证匹配特征对的outliers(无效数据,外点)较少,以及匹配的高质量。匹配特征对的统计资料被用来估计条件分布。
相关性r通过各个参数的条件概率函数相乘而得:
f 1~f 5都可以从根据兴趣点特征学习条件条件分布的标准表中得到。最后特征基于相关性r进行排序,根于总体的特征数据量的预算和每个特征所占位数,选出一部分固定数目的特征。图三……略
与其他方法相比:特征选择的一个简单方法(naive approach?)是使用基于兴趣点检测子的峰值响应排序特征。标准中采用的方法,考虑了若干个兴趣点特征,具有相当优异的性能,尤其是在低位率状态下。另一个性能方面的显著提高体现在特征基于全局描述子中的相关性,而被有选择地聚合时。标准的初稿中还包含第六个参数,是的特征选择可以独立于特征方向。然而,由于带来的改善不多,方向独立性在CDVS标准最终确立是被去掉了。
C.Local Feature Descriptor Compression
未经压缩的SIFT描述子,存储时每个描述子占1024位(128个维度,每个维度1B)。即使未压缩的SIFT描述子很小,也会带来数十KB的数据,因此,局部特征描述子压缩对于减少特征数据大小具有重要意义。使用具有创新性的压缩模式,每个描述子所占位数可以压缩一个量级,而仅仅损失很少的匹配精度。基于PQ(Product Quantization)乘积量化,PTSVQ(Product Tree Structured Vector Quantization)乘积树结构向量量化,MSVQ(Multi-stage Vector Quantizer)多级向量量化,格子编码和变换编码的几种压缩方法,都曾在标准化过程中被提出。不过最终,在经过全面评估之后,使用了一种低复杂度的变换编码方式。
具体的标准所采用的变换编码的方法可参见(待引用)。对于一个局部的特征描述子来说,如图5所示的每一个单元直方图H0,……H15,每一个都有8个angular bins(不知道怎么翻译这八个方位)h0,……,h7,它们是独立变换的。

变换编码分为两步:描述子变换,先做简单的SIFT成分的加减,再做三元标量量化和变换后的元素的熵编码。此方法对于SIFT描述子的独立的spatial bins做small order-8 小型的八维线性变换,而不是对整个描述子(会降低性能)应用一个order-128 128维的线性变换。以下等式定义了两组分别对A和B做的线性变换。

h0~h7表示每个局部特征描述子的每个单元直方图的bin……
变换还可以用其他的方法实现。……
SIFT描述子中邻近的spatial bins有相似的值,因此,对不同的临近bins应用不同的变换可以提升性能,特别是在超低位率比如说每个描述子32位的情况下。变换元素的子集,每个描述子的位数和描述子的数量根据经验做优化,在描述子长度分别为512bytes,1KB,2KB,4KB,8KB,和16KB的情况下,描述子的位数分别为32,32,65,103,129和205位。可选的栅格模式,……略。The alternating grid pattern shown in Figure 5 also emerges from the greedy rate allocation scheme proposed in.
给定两个量化的局部特征描述子{ Vq=vqi|i=0,1,…127andVr=vri|i=0,1,…127 },他们的相似性距离Dis(·)在变换域中使用L1计算:
sqi 和 sri 表示 Vq 和 Vr 中的第i个元素被选中。注意到以上公式可以实现,仅通过比较描述子共有的变换的描述子元素,实现在不同位率情况下的编码后的描述子的比较。标准的固定优先次序模式保证了低位率情况下描述子的每一个元素仍可以表现出高位率情况下的性能。
与其他方法相比:选择变换编码模式而不是其他VQ和格子编码方法是因为变化编码模式简单易行,内存消耗低,计算复杂度低以及在低位率状态下有卓越的表现。变换编码模式的内存消耗与乘积向量量化product vector quantization方法的数以KB和MB计的内存消耗相比,可以忽略不计。对主存的要求约为256bytes(变换的元素个数128*2三元SQ门限)。另外,此方法比需要通过密码本进行最近邻搜索的VQ方法有更低的计算复杂度。在低位率情况下,变换编码模式的性能也优于或等同于集中基于VQ的方法,格子编码,和二进制哈希方法。这种变换编码的方法的性能与熵约束向量量化entropy constrained vector quantization和贪心速率分配方法greedy rate allocation的性能接近。
除了变换编码之外,MSVQ方法曾被……略。
D.Local Feature Location Compression
每一个特征的位置数据x,y的压缩是与描述子压缩相关的一个问题。每一个描述子都有一个x,y位置,在GCC几何一致性校验步骤中会使用。如果x,y位置数据是浮点数类型,则位置数据的大小会与压缩后的描述子本身的大小相当。
CDVS标准中采用了位置直方图编码方式。位置直方图方法是基于如果舍弃n个特征的原始顺序,则可以在原来的熵编码比特流之外,节省额外的log(n!)位空间。提取出的特征的原始顺序会在两个步骤:视觉搜索流水线—用词袋或者全局描述子,以及GCC几何一致性校验步骤中被舍弃。位置直方图编码模式是一种实现节省log(n!)速率的可行方法。排序开销随特征数量的变化表示在图*中:排序的开销随着特征数量的增长而增长,对于成百上千个特征来说,每个特征需要6-8位表示顺序,在每个特征编码为32-100位时还是很重要的。

图7表示位置直方图编码方法。每一幅图像都被分成3*3的互不交叠的小块,每个特征的位置数据(x,y)都量化到了栅格中去。位置数据被表示成由(a)直方图映射和(b)直方图计数组成的直方图。直方图计数表示直方图中的哪一个bin是非空的,直方图计数表示在每一个非空块中的特征数量。这些描述子会根据直方图映射中的位置顺序重新排序。
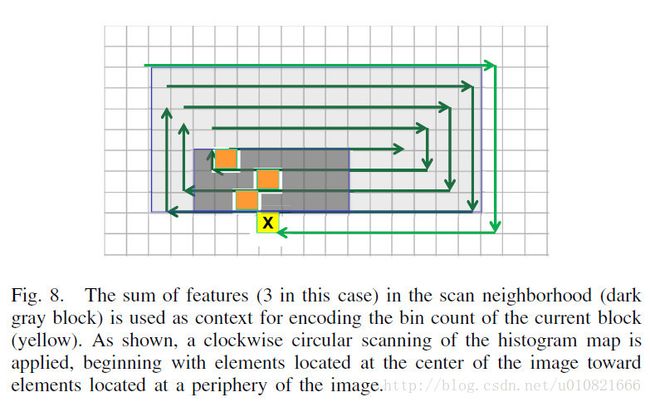
直方图计数使用64symbol?,单一模型,静态算术编码的方式进行编码。直方图映射使用二进制的基于上下文的静态算术编码的方式进行编码。如图8中所示,邻居块中的特征作为给定块直方图计数编码时的上下文使用。sum-based的上下文利用了特征位置的集群–可明显在图像中找到。由于特征会高密度集中在图像中心,所以使用顺时针扫描而不是光栅扫描对直方图映射进行扫描。此外,每一个特征有约6位用于位置编码,而对原始位置坐标(存储原始位置坐标,每个特征需要使用log2(640*640) = 18.6位)使用算术编码,在默认块大小为1*1的情况下,做无损位置编码时,每一个特征需用约12位。有损的位置直方图编码方式在成对匹配和检索实验中带来的匹配性能的损失可忽略不计。
与其他方式相比:
暂略
E.Local Feature Descriptor Aggregation
最先进的图像检索系统是基于VLAD(Vector of Locally Aggregated Descriptors)局部聚合描述子向量和FV(Fisher Vector)费舍尔向量这样的全局描述子的。BoW(Bag-of-Words)词袋模型也是一个普遍的选择。在BoW的框架里,图像用直方图来表示,直方图是由一棵大型词汇树(比如说一百万个视觉词汇) 中得到的量化描述子得到的,词汇树中有倒排索引用来快速匹配。在全局描述子的框架中,图像用稠密的高维向量(维度约为10K-100K)表示。找到一个有高性能和低内存消耗的紧凑的全局描述子是CDVS标准化过程中面临的主要挑战之一。CDVS标准要求低的内存开销(整个编码过程最多使用1MB),使得BoW词袋模型的方法并不适用。
经过大量实验之后,CDVS标准采用了SCFV(Scalable Compressed Fisher Vector)可伸缩的压缩费舍尔向量方法。它使用了一个有512个成分的GMM(Gaussian Mixture Model)高斯混合模型来得到多达250个局部特征描述子的分布。the gradient of the log-likelihood for an observed set of local feature descriptors with respect to the mean and for higher bitrates,the variances of the GMM are concatenated to form the FV representation.(啊啊啊翻译不通顺啊)。Each descriptor is assigned to multiple Gaussians(visual words) in a soft assignment step。费舍尔向量方法与BoW模型的方法相比,需要的词汇数目小很多,能够满足CDVS对于内存的要求。
没有压缩过的费舍尔向量,以浮点数的方式存储,需要上千字节的空间,有时比压缩后的局部特征描述子更大。为了压缩费舍尔向量,SCFV方法使用了一位标量量化,使用汉明距离做快速匹配。对于?每个描述子长度,需要在压缩的全局描述子和一组压缩的局部特征描述子之间共享位预算。出于这个目的,SCFV使用了速率可伸缩的表示方法(对于六种特定位率,平均大小为304,384,404,1117,1117和1117字节),这种方法使用基于对完全填充的费舍尔向量的特定成分(表示与成分平均值相关的梯度?)的标准差的GMM高斯混合模型中的高斯成分的一个子集(好长的句子),并且只保留与被选中的成分相关的信息。大量的实验表明,所使用的基于标准差的方法,擅长移除non- or less(?)有区分力的成分去实现一个更加鲁棒的FV呈现,and selecting informative components to undergo less negative performance impact from sign quantization,has outperformed the quantization error-based selection method.特别地,对于每一个高斯成分i,32维的与高斯成分平均值相关的累积梯度向量 g=[g0,g1,……,g31] 标准差 δ(i) 用一下公式计算:
之后,高斯成分根据 δ(i) 进行递减排序。对于较短的三种长度分别为512B,1KB,2KB的描述子,前k个高斯成分会提前被挑选出来;对于更长的三种长度分别为4KB,8KB,和16KB的描述子,会选出 δ(i)>τδ , τδ 表示一个选择阈值。除此之外的内存预算会被不同描述子长度下的压缩过的局部特征描述子用掉。注意到每幅图像的GMM成分的不同集合是基于哪些成分提供了最多的信息这一标准选择出来的。头几位标志着选中了哪些成分。SCFV包含了4KB,8KB,16KB长度的描述子的与GMM方差参数有关的对数似然梯度。对于更短的图像描述子,只是用与平均值有关的梯度。
给定两幅图像X和Y,我们可以计算出SCFV的基于汉明距离的相似性S(·):
uYi 表示GMM中第i个二进制化的高斯成分(梯度与平均值有关或与方差有关)。如果第i个成分被选中, bXi = 1,否则为0。 Ha(uXi,uYi) 代表第i个高斯成分,X和Y之间的汉明距离,范围是0-32。 ωHa(uXi,uYi) 表示第i个高斯成分的相关权重。
与其它方法相比:略。