识别数字在机器学习任务中的地位和 Hello World 在编程中是一样的。
主要步骤:
- 获得数据:from Yann LeCun's website
- 建立模型:softmax
- 定义 tensor,variable:X,W,b
- 定义损失函数,优化器:cross-entropy,gradient descent
- 训练模型:loop,batch
- 评价:准确率
1. 获得数据
- 来自 Yann LeCun's website:http://yann.lecun.com/exdb/mnist/
- 分为 train,test,validate,每个 X 代表一个图片,y 是它的 label
- 其中图片由
28*28像素组成,转化成 array 的形式,变成1*784维 - y 变为 one-hot 的形式,即属于哪个数字,就在哪个位置上为 1, 其余为 0
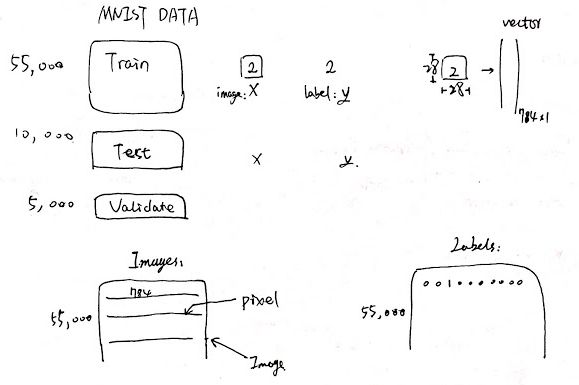
目标:给了 X 后,预测它的 label 是属于 0~9 类中的哪一类

如果想要看数据属于多类中的哪一类,首先可以想到用 softmax 来做。
2. 建立模型
softmax regression 有两步:
- 把 input 转化为某类的 evidence
- 把 evidence 转化为 probabilities
1. 把 input 转化为某类的 evidence
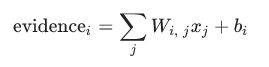
- 某一类的 evidence 就是像素强度的加权求和,再加上此类的 bias。
- 如果某个 pixel 可以作为一个 evidence 证明图片不属于此类,则 weight 为负,否则的话 weight 为正。
下图中,红色代表负值,蓝色代表正值:

2. 把 evidence 转化为 probabilities
简单看,softmax 就是把 input 先做指数,再做一下归一:

- 归一的作用:好理解,就是转化成概率的性质
- 为什么要取指数:在 《常用激活函数比较》写过
http://www.jianshu.com/p/22d9720dbf1a- 第一个原因是要模拟 max 的行为,所以要让大的更大。
- 第二个原因是需要一个可导的函数。
用图形表示为:


上面两步,写成矩阵形式:
模型的代码只有一行:
y = tf.nn.softmax(tf.matmul(x, W) + b)
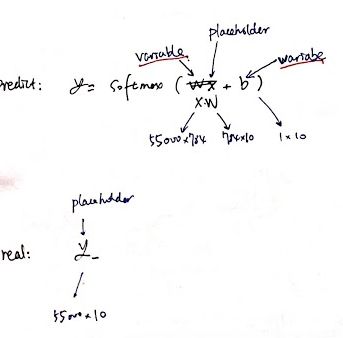
3. 定义 tensor 和 variable:
4. 定义损失函数,优化器:
用 cross-entropy 作为损失来衡量模型的误差:

其中,y 是预测, y′ 是实际 .
按照表面的定义,代码只有一行:
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
不过因为上面不稳定,所以实际用:
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
然后用 backpropagation, 且 gradient descent 作为优化器,来训练模型,使得 loss 达到最小:
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
5. 训练模型
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
6. 评价
看 y 和 y′ 有多少相等的,转化为准确率。
再测试一下 test 数据集上的准确率,结果可以达到 92%。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
这只是最简单的模型,下次看如何提高精度。
完整代码和注释:
温馨提示,用web打开,代码格式比较好看
"""A very simple MNIST classifier.
See extensive documentation at
https://www.tensorflow.org/get_started/mnist/beginners
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import sys
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
FLAGS = None
def main(_):
# Import data
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
# Create the model
x = tf.placeholder(tf.float32, [None, 784])
# a 2-D tensor of floating-point numbers
# None means that a dimension can be of any length
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.matmul(x, W) + b
# It only takes one line to define it
# Define loss and optimizer
y_ = tf.placeholder(tf.float32, [None, 10])
# The raw formulation of cross-entropy,
#
# tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.nn.softmax(y)),
# reduction_indices=[1]))
# tf.reduce_sum adds the elements in the second dimension of y,
# due to the reduction_indices=[1] parameter.
# tf.reduce_mean computes the mean over all the examples in the batch.
#
# can be numerically unstable.
#
# So here we use tf.nn.softmax_cross_entropy_with_logits on the raw
# outputs of 'y', and then average across the batch.
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# apply your choice of optimization algorithm to modify the variables and reduce the loss.
sess = tf.InteractiveSession()
# launch the model in an InteractiveSession
tf.global_variables_initializer().run()
# create an operation to initialize the variables
# Train~~stochastic training
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
# Each step of the loop,
# we get a "batch" of one hundred random data points from our training set.
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# Test trained model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
# use tf.equal to check if our prediction matches the truth
# tf.argmax(y,1) is the label our model thinks is most likely for each input,
# while tf.argmax(y_,1) is the correct label.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# [True, False, True, True] would become [1,0,1,1] which would become 0.75.
print(sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))
# ask for our accuracy on our test data,about 92%
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', type=str, default='/tmp/tensorflow/mnist/input_data',
help='Directory for storing input data')
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
学习资料:
https://www.tensorflow.org/get_started/mnist/beginners
今天开始系统学习 TensorFlow,大家有什么问题可以留言,一起讨论学习。
推荐阅读 历史技术博文链接汇总
http://www.jianshu.com/p/28f02bb59fe5
也许可以找到你想要的