介绍
同Yolo一样,SSD也是一种端到端的单阶段目标检测网络。它将图片之上的检测目标视为是许多个default boxes的离散化合成。与Yolo不同,它在网络的头部只使用了CNN来进一步提取box位置、类别信息,而没有使用FC层,这使得它的模型参数有所较少。另外它的头部还使用了特征提取CNN网络的后面数层(有些层是自己在主干网络后面添加的)feature maps作为输入,而非像Yolo等端到端网络那样只使用最后面一层,这样它能有效地在各个尺度上检测潜在目标,有效地扩大了目标检测的尺度范围。
此外它使用了更加激进的数据增强,这使得它最终训练出的模型的mAP值进一步提高,从而真的成为了一种state-of-art的端到端模型。
SSD概述
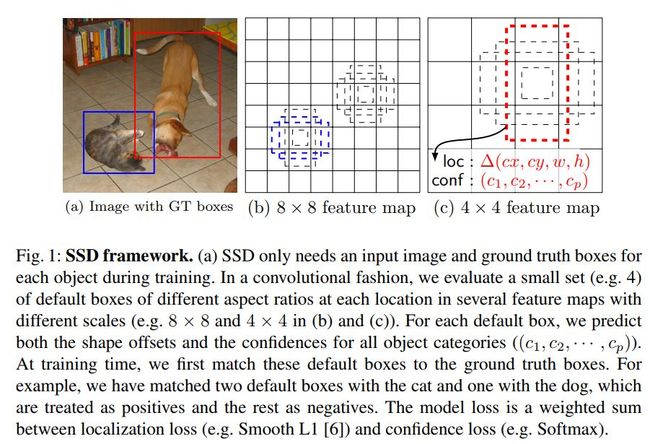
- 多尺度feature maps使用
上图为SSD的基本检测框架。一般我们欲检测的图片当中会包含有着不同尺度大小及分辨率的目标。为了有效地涵盖这种种不同尺度、分辨率的目标检测,SSD扩大了其特征选取的范围即不只是像Yolo或R-CNN那样只以最后一个conv层的feature maps作为输入,而是使用了主干网络后面数个conv层的feature maps。另外它还通过在主干网络后面叠加了几个conv层,进一步也使用它们的输出feature maps作为网络头的输入。下图为SSD与Yolo的网络结构比较。
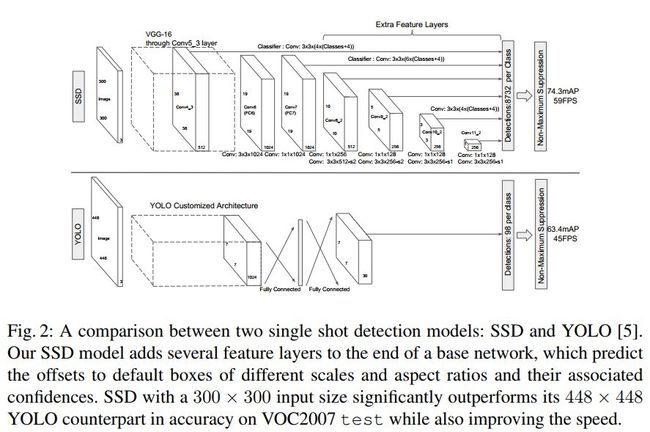
- 使用Conv层来进行位置、类别等信息检测
在选取的feature maps之上,SSD使用不同的Conv层来进一步分离、提取其上可能的box的位置、类别信息。比如对一个输出为pxmxn的feature maps(其中p为channels数目,m与n表示此feature map的size)而言,SSD会使用数个3x3xp的Conv kernels对其进行处理,每个Conv kernel会输出反映此位置的目标类别或位置信息(其中位置信息指的是目标box与所处的default box之间的位置偏离)。
- 不同尺度及分辨率的default boxes
SSD在输入feature map的每个位置检测不同尺度、分辨率的anchor boxes的类别及位置信息以来涵盖尽可能多的不同形状的目标。每个位置共有(C+4)种信息需要处理得到(其中C为目标类别数目,4则分别表示目标框的中心位置及大小等信息)。而在每个特征输入位置,SSD采用了k个不同尺度及分辨率的default box,然后使用3x3xkx(C+4)的conv kernels对输入feature map之上的每个位置进行处理以得到k个目标框的(C+4)个信息。这样如果输入feature map的大小为mxn,那么则需要kx(C+4)xmxn个数目的Conv kernels对其进行处理。
SSD训练
匹配策略
如上节所述,SSD会在每个输入的feature maps上的每个位置预测k个default boxes的类别及位置偏移信息。然后会将这k个default boxes分别与group truth box进行比较,计算其jaccard overlap,进而选取与每个ground truth box重合最多的default box为positive box,另外还会选取与任一个ground truth box重合度在0.5以上的default boxes为positive boxes。
Training loss
以下为SSD的training loss计算公式,容易看出它也主要由两部分来构成,分别为反映目标类别的classification loss及反映目标位置的localization loss。其中classification loss主要使用softmax loss,而localization loss则多采用L1 loss。

Default boxes尺度及分辨率的选择
不同深浅的Conv层显然反映着图片上不同尺度的信息。因此我们需要对其上的default box的检测目标尺度加以确定。以下为不同Conv层feature map上的default boxes的基准尺度计算公式。

每个conv层上基于以上的default box的基准尺度,又进一步调整,最终在每一conv层上使用不同尺度及分辨率的k个default boxes。对其计算过程,特附原文部分在这里(抱歉,实在是所用的编辑器不大能进行公式编辑)。如下为SSD中k个default boxes的具体生成。

Hard negative mining
这个步骤基本是所有目标检测框架都必需的。在经过了上述default boxes与ground truth boxes的匹配过程后,会有非常多的default boxes不包含任何目标,因此其中含有着大量的false boxes。这造成了严重的数据不平衡。文中作者对所有的negative boxes按其confidence loss值大小进行排序,然后取其中分值最高的一些negative boxes来作为后续的loss计算(一般会控制negative boxes数目与positive boxes数目之间的比例不超过3:1)。
数据集增强
每一个输入的image都会随机地接受如下三种方式进行处理。
- 使用原图
- 从原图之上随机地切取一个patch,其中此patch与图上目标之间的最小jaccard overlap可随机为0.1,0.3,0.5,0.7,0.9
- 随机切取一个patch
实验结果
Paper当中作者在不同数据集上与其它的主流目标检测框架进行了大量的比较。我们只选用如下其中VOC2007上与其它模型之间的结果比较作一说明。其它实验结果可去作者原paper中查询。

代码分析
如下为其data layer,可从中看出它作了大量的data augmentation工作。
layer {
name: "data"
type: "AnnotatedData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
mean_value: 104.0
mean_value: 117.0
mean_value: 123.0
resize_param {
prob: 1.0
resize_mode: WARP
height: 300
width: 300
interp_mode: LINEAR
interp_mode: AREA
interp_mode: NEAREST
interp_mode: CUBIC
interp_mode: LANCZOS4
}
emit_constraint {
emit_type: CENTER
}
distort_param {
brightness_prob: 0.5
brightness_delta: 32.0
contrast_prob: 0.5
contrast_lower: 0.5
contrast_upper: 1.5
hue_prob: 0.5
hue_delta: 18.0
saturation_prob: 0.5
saturation_lower: 0.5
saturation_upper: 1.5
random_order_prob: 0.0
}
expand_param {
prob: 0.5
max_expand_ratio: 4.0
}
}
data_param {
source: "examples/VOC0712/VOC0712_trainval_lmdb"
batch_size: 8
backend: LMDB
}
annotated_data_param {
batch_sampler {
max_sample: 1
max_trials: 1
}
batch_sampler {
sampler {
min_scale: 0.300000011921
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.10000000149
}
max_sample: 1
max_trials: 50
}
batch_sampler {
sampler {
min_scale: 0.300000011921
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.300000011921
}
max_sample: 1
max_trials: 50
}
.........
.........
batch_sampler {
sampler {
min_scale: 0.300000011921
max_scale: 1.0
min_aspect_ratio: 0.5
max_aspect_ratio: 2.0
}
sample_constraint {
max_jaccard_overlap: 1.0
}
max_sample: 1
max_trials: 50
}
label_map_file: "data/VOC0712/labelmap_voc.prototxt"
}
}
如下我们选取Conv4_3的输出feature maps为代表来看下SSD是如何从其上提取目标boxes的类别及位置信息的。
layer {
name: "conv4_3_norm"
type: "Normalize"
bottom: "conv4_3"
top: "conv4_3_norm"
norm_param {
across_spatial: false
scale_filler {
type: "constant"
value: 20.0
}
channel_shared: false
}
}
layer {
name: "conv4_3_norm_mbox_loc"
type: "Convolution"
bottom: "conv4_3_norm"
top: "conv4_3_norm_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv4_3_norm_mbox_loc_perm"
type: "Permute"
bottom: "conv4_3_norm_mbox_loc"
top: "conv4_3_norm_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv4_3_norm_mbox_loc_flat"
type: "Flatten"
bottom: "conv4_3_norm_mbox_loc_perm"
top: "conv4_3_norm_mbox_loc_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv4_3_norm_mbox_conf"
type: "Convolution"
bottom: "conv4_3_norm"
top: "conv4_3_norm_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 84
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv4_3_norm_mbox_conf_perm"
type: "Permute"
bottom: "conv4_3_norm_mbox_conf"
top: "conv4_3_norm_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv4_3_norm_mbox_conf_flat"
type: "Flatten"
bottom: "conv4_3_norm_mbox_conf_perm"
top: "conv4_3_norm_mbox_conf_flat"
flatten_param {
axis: 1
}
}
同样以Conv4_3这一个feature map为例,如下可见其如何得到上面的default boxes的具体信息(它是在training前就确定下来的,并且一直保持不变作为参考基准)。
layer {
name: "conv4_3_norm_mbox_priorbox"
type: "PriorBox"
bottom: "conv4_3_norm"
bottom: "data"
top: "conv4_3_norm_mbox_priorbox"
prior_box_param {
min_size: 30.0
max_size: 60.0
aspect_ratio: 2.0
flip: true
clip: false
variance: 0.10000000149
variance: 0.10000000149
variance: 0.20000000298
variance: 0.20000000298
step: 8.0
offset: 0.5
}
}
最后如下几层为loss层的具体计算。
layer {
name: "mbox_loss"
type: "MultiBoxLoss"
bottom: "mbox_loc"
bottom: "mbox_conf"
bottom: "mbox_priorbox"
bottom: "label"
top: "mbox_loss"
include {
phase: TRAIN
}
propagate_down: true
propagate_down: true
propagate_down: false
propagate_down: false
loss_param {
normalization: VALID
}
multibox_loss_param {
loc_loss_type: SMOOTH_L1
conf_loss_type: SOFTMAX
loc_weight: 1.0
num_classes: 21
share_location: true
match_type: PER_PREDICTION
overlap_threshold: 0.5
use_prior_for_matching: true
background_label_id: 0
use_difficult_gt: true
neg_pos_ratio: 3.0
neg_overlap: 0.5
code_type: CENTER_SIZE
ignore_cross_boundary_bbox: false
mining_type: MAX_NEGATIVE
}
}
参考文献
- SSD: Single Shot MultiBox Detector, Wei-Liu, 2015
- https://github.com/weiliu89/caffe/tree/ssd