【SPARK】知识点全讲解
SPARK知识点全讲解
- Spark环境部署
- Spark简介
-
- 诞生与发展
- 为什么使用Spark
- Spark优势
- Spark技术栈
- Spark架构设计
-
- Spark架构核心组件
- Spark交互工具
- Spark API
-
- SparkContext
- SparkSession
- RDD
- DataSet
- DateFrame
- Spark的RDD
-
- 概念
- RDD与DAG
- RDD的特性
- RDD编程流程
- 创建RDD
- RDD分区
- RDD的操作
- RDD转换算子
-
- RDD常用算子转换
- Spark分布式计算原理
-
- RDD的依赖关系
- DAG工作原理
- Spark Shuffle过程
- RDD优化
-
- RDD持久化
-
- 检查点
- 共享变量
- 分区设计
- 数据倾斜
- 装载数据源
- Spark SQL
-
- SparkSQL架构
- SparkSQL运行原理
- 优化器
- SparkSQL API
-
- Dataset
- DataFrame
- SparkSQL操作外部数据源
- Parquet文件
- Hive表
- RDBMS表
- SparkSQL函数
-
- 内置函数
- 自定义函数
- Spark性能优化
-
- 序列化
- SparkGraphX 图形数据分析
-
- 图的基本概念
- GraphX核心抽象
- GraphX API
- pregel函数
Spark环境部署
前置条件:完成Scala环境部署
可以参考我的博客:Scala环境部署和简单介绍
然后我们在vmware虚拟机上配置Scala和Spark并初步使用
Spark简介
诞生与发展
-
诞生于加州大学伯克利分校AMP实验室,是一个基于内存的分布式计算框架
-
发展历程:
2009年诞生于加州大学伯克利分校AMP实验室
2010年正式开源
2013年6月正式成为Apache孵化项目
2014年2月成为Apache顶级项目
2014年5月正式发布Spark 1.0版本
2014年10月Spark打破MapReduce保持的排序记录
2015年发布了1.3 1.4 1.5版本
2016年发布了1.6 2.x版本
为什么使用Spark
-
MapReduce编程模型的局限性
繁杂
只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码 -
MapReduce处理效率低
Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据
任务调度与启动开销大
不适合迭代处理、交互式处理和流式处理 -
Spark是类Hadoop MapReduce的通用并行框架
Job中间输出结果可以保存在内存,不再需要读写HDFS
比MapReduce平均快10倍以上
Spark优势
- 速度快
基于内存数据处理,比MR快100个数量级以上(逻辑回归算法测试)
基于硬盘数据处理,比MR快10个数量级以上 - 易用性
支持Java、Scala、Python、R语言
交互式shell方便开发测试 - 通用性
一栈式解决方案:批处理、交互式查询、实时流处理、图计算及机器学习 - 随处运行
YARN、Mesos、EC2、Kubernetes、Standalone、Local
Spark技术栈

- Spark Core
核心组件,分布式计算引擎 - Spark SQL
高性能的基于Hadoop的SQL解决方案 - Spark Streaming
可以实现高吞吐量、具备容错机制的准实时流处理系统 - Spark GraphX
分布式图处理框架 - Spark MLlib
构建在Spark上的分布式机器学习库
Spark架构设计
Spark的运行架构:
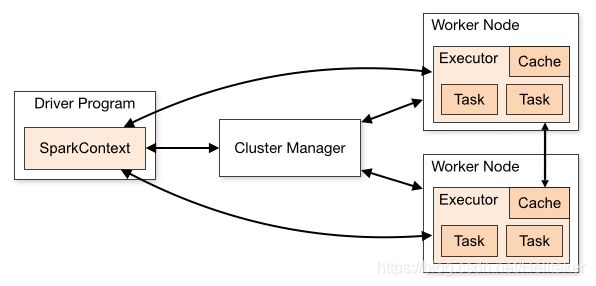
- 在驱动程序中,通过SparkContext主导应用的执行
- SparkContext可以连接不同类型的Cluster Manager(Standalone、YARN、Mesos),连接后,获得集群节点上的Executor
- 一个Worker节点默认一个Executor,可通过SPARK_WORKER_INSTANCES调整
- 每个应用获取自己的Executor
- 每个Task处理一个RDD分区
Spark架构核心组件

Spark交互工具
- 本机
spark-shell --master local[*] - Standalone
spark-shell --master spark://MASTERHOST:7077 - YARN
spark-shell --master yarn-client
Spark API
SparkContext
- 连接Driver与Spark Cluster(Workers)
- Spark的主入口
- 每个JVM仅能有一个活跃的SparkContext
- SparkContext.getOrCreate
import org.apache.spark.{
SparkConf, SparkContext}
val conf=new SparkConf().setMaster("local[*]").setAppName("appName")
val sc=SparkContext.getOrCreate(conf)
SparkSession
- Spark 2.0+应用程序的主入口:包含了SparkContext、SQLContext、HiveContext以及StreamingContext
- SparkSession.getOrCreate
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder
.master("local[*]")
.appName("appName")
.getOrCreate()
RDD
Spark核心,主要数据抽象
DataSet
从Spark1.6开始引入的新的抽象,特定领域对象中的强类型集合,它可以使用函数或者相关操作并行地进行转换等操作
DateFrame
DataFrame是特殊的Dataset
Spark的RDD
概念
简单的解释:RDD是将数据项拆分为多个分区的集合,存储在集群的工作节点上的内存中,并执行正确的操作
复杂的解释:RDD是用于数据转换的接口;RDD指向了存储在HDFS、Cassandra、HBase等、或缓存(内存、内存+磁盘、仅磁盘等),或在故障或缓存收回时重新计算其他RDD分区中的数据
RDD是 弹性分布式数据集 (Resilient Distributed Datasets):
- 分布式数据集
RDD是只读的、分区记录的集合,每个分区分布在集群的不同节点上
RDD并不存储真正的数据,只是对数据和操作的描述 - 弹性
RDD默认存放在内存中,当内存不足,Spark自动将RDD写入磁盘 - 容错性
根据数据血统,可以自动从节点失败中恢复分区
RDD与DAG
两者是Spark提供的核心抽象
DAG(有向无环图)反映了RDD之间的依赖关系
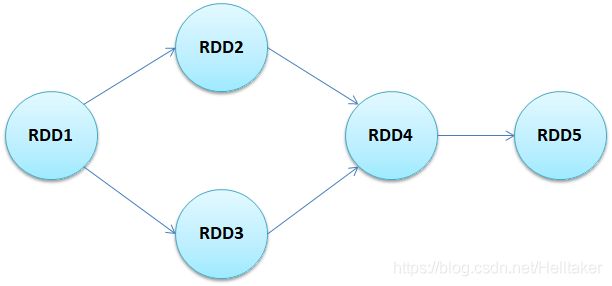
RDD的特性
- 一系列的分区(分片)信息,每个任务处理一个分区
- 每个分区上都有compute函数,计算该分区中的数据
- RDD之间有一系列的依赖
- 分区函数决定数据(key-value)分配至哪个分区
- 最佳位置列表,将计算任务分派到其所在处理数据块的存储位置
RDD编程流程

创建RDD
第一种:使用集合创建RDD
val rdd=sc.parallelize(List(1,2,3,4,5,6))
rdd.count
rdd.partitions.size
val rdd=sc.parallelize(List(1,2,3,4,5,6),5)
rdd.partitions.size
val rdd=sc.makeRDD(List(1,2,3,4,5,6))
第二种:通过加载文件产生RDD
val distFile=sc.textFile("file:///home/hadoop/data/hello.txt")
distFile.count
val distHDFSFile=sc.textFile("hdfs://hadoop000:8020/hello.txt")
支持目录、压缩文件以及通配符
sc.textFile("/my/directory")
sc.textFile("/my/directory/*.txt")
sc.textFile("/my/directory/*.gz")
第三种:其他创建RDD的方法
- SparkContext.wholeTextFiles():可以针对一个目录中的大量小文件返回
- 普通RDD:org.apache.spark.rdd.RDD[data_type]
- PairRDD:org.apache.spark.rdd.RDD[(key_type,value_type)]
- SparkContext.sequenceFileK,V
Hadoop SequenceFile的读写支持 - SparkContext.hadoopRDD()、newAPIHadoopRDD()
从Hadoop接口API创建 - SparkContext.objectFile()
RDD.saveAsObjectFile()的逆操作
RDD分区
分区是RDD被拆分并发送到节点的不同块之一
- 拥有的分区越多,得到的并行性就越强
- 每个分区都是被分发到不同Worker Node的候选者
- 每个分区对应一个Task
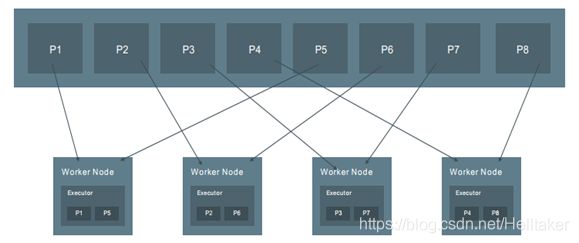
RDD的操作
分为lazy与non-lazy两种:
- Transformation(lazy):也称转换操作、转换算子
- Actions(non-lazy):立即执行,也称动作操作、动作算子
RDD转换算子
对于转换操作,RDD的所有转换都不会直接计算结果:
- 仅记录作用于RDD上的操作
- 当遇到动作算子(Action)时才会进行真正计算

RDD常用算子转换
spark常用RDD算子汇总(java和scala版本)
Spark分布式计算原理
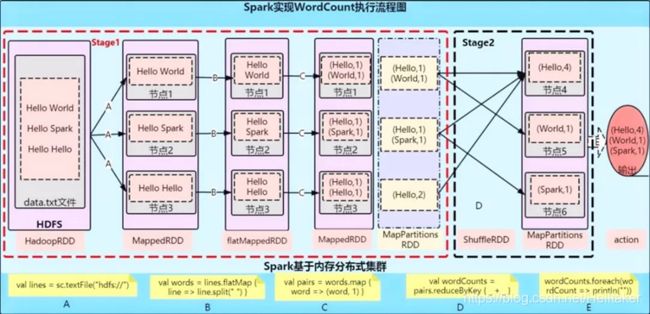
RDD的依赖关系
- Lineage:血统、遗传
RDD最重要的特性之一,保存了RDD的依赖关系
RDD实现了基于Lineage的容错机制 - 依赖关系
宽依赖
窄依赖

- 宽依赖对比窄依赖
宽依赖对应shuffle操作,需要在运行时将同一个父RDD的分区传入到不同的子RDD分区中,不同的分区可能位于不同的节点,就可能涉及多个节点间数据传输
当RDD分区丢失时,Spark会对数据进行重新计算,对于窄依赖只需重新计算一次子RDD的父RDD分区

结论:相比于宽依赖,窄依赖对优化更有利
DAG工作原理
- 根据RDD之间的依赖关系,形成一个DAG(有向无环图)
- DAGScheduler将DAG划分为多个Stage
划分依据:是否发生宽依赖(Shuffle)
划分规则:从后往前,遇到宽依赖切割为新的Stage
每个Stage由一组并行的Task组成
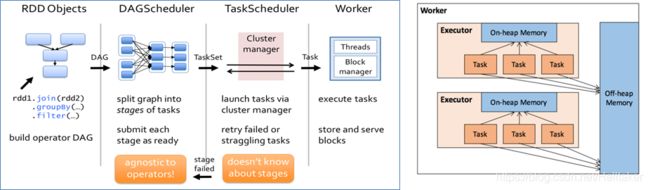
为什么需要划分Stage?
数据本地化
移动计算,而不是移动数据
保证一个Stage内不会发生数据移动
最佳实践:
尽量避免Shuffle
提前部分聚合减少数据移动

Spark Shuffle过程
- 在分区之间重新分配数据
父RDD中同一分区中的数据按照算子要求重新进入子RDD的不同分区中
中间结果写入磁盘
由子RDD拉取数据,而不是由父RDD推送
默认情况下,Shuffle不会改变分区数量

RDD优化
RDD持久化
RDD共享变量
RDD分区设计
数据倾斜
RDD持久化
- RDD缓存机制:缓存数据至内存/磁盘,可大幅度提升Spark应用性能
cache=persist(MEMORY)
persist - 缓存策略StorageLevel
MEMORY_ONLY(默认)
MEMORY_AND_DISK
DISK_ONLY
val u1 = sc.textFile("file:///root/data/users.txt").cache
u1.collect//删除users.txt,再试试
u1.unpersist()
缓存应用场景:
从文件加载数据之后,因为重新获取文件成本较高
经过较多的算子变换之后,重新计算成本较高
单个非常消耗资源的算子之后
使用注意事项:
cache()或persist()后不能再有其他算子
cache()或persist()遇到Action算子完成后才生效
检查点
类似于快照
sc.setCheckpointDir("hdfs:/checkpoint0918")
val rdd=sc.parallelize(List(('a',1), ('a',2), ('b',3), ('c',4)))
rdd.checkpoint
rdd.collect //生成快照
rdd.isCheckpointed
rdd.getCheckpointFile
检查点与缓存的区别
检查点会删除RDD lineage,而缓存不会
SparkContext被销毁后,检查点数据不会被删除
共享变量
广播变量:允许开发者将一个只读变量(Driver端)缓存到每个节点(Executor)上,而不是每个任务传递一个副本
val broadcastVar=sc.broadcast(Array(1,2,3)) //定义广播变量
broadcastVar.value //访问方式
注意事项:
1、Driver端变量在每个Executor每个Task保存一个变量副本
2、Driver端广播变量在每个Executor只保存一个变量副本
分区设计
- 分区大小限制为2GB
- 分区太少
不利于并发
更容易受数据倾斜影响
groupBy,reduceByKey,sortByKey等内存压力增大 - 分区过多
Shuffle开销越大
创建任务开销越大 - 经验
每个分区大约128MB
如果分区小于但接近2000,则设置为大于2000
数据倾斜
指分区中的数据分配不均匀,数据集中在少数分区中,严重影响性能
通常发生在groupBy,join等之后

解决方案
使用新的Hash值(如对key加盐)重新分区
装载数据源
CSV格式:
//使用SparkContext
val lines = sc.textFile("file:///home/kgc/data/users.csv")
val fields = lines.mapPartitionsWithIndex((idx, iter) => if (idx == 0) iter.drop(1) else iter).map(l => l.split(","))
val fields = lines.filter(l=>l.startsWith("user_id")==false).map(l=>l.split(",")) //移除首行,效果与上一行相同
//使用SparkSession
val df = spark.read.format("csv").option("header", "true").load("file:///home/kgc/data/users.csv")
JSON格式:
//SparkContext
val lines = sc.textFile("file:///home/kgc/data/users.json")
//scala内置的JSON库
import scala.util.parsing.json.JSON
val result=lines.map(l=>JSON.parseFull(l))
//SparkSession
val df = spark.read.format("json").option("header", "true").load("file:///home/kgc/data/users.json")
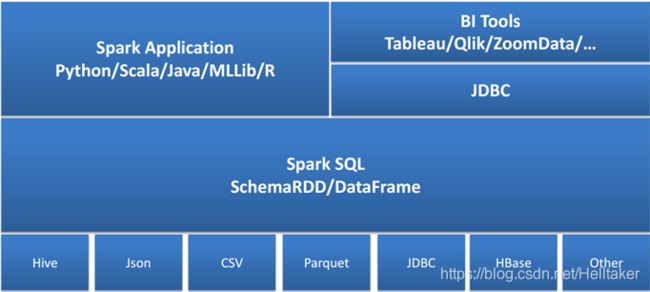
Spark SQL
SparkSQL架构
- Spark SQL是Spark的核心组件之一(2014.4 Spark1.0)
- 能够直接访问现存的Hive数据
- 提供JDBC/ODBC接口供第三方工具借助Spark进行数据处理
- 提供了更高层级的接口方便地处理数据
- 支持多种操作方式:SQL、API编程
- 支持多种外部数据源:Parquet、JSON、RDBMS等
SparkSQL运行原理
Catalyst优化器是Spark SQL的核心
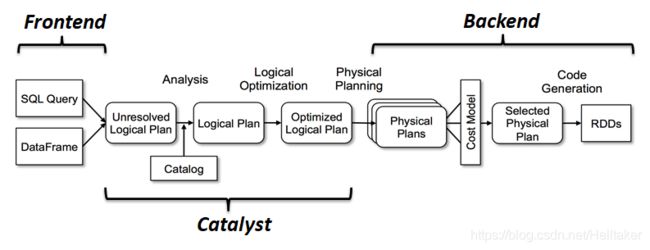
Catalyst Optimizer:Catalyst优化器,将逻辑计划转为物理计划
优化器
- 逻辑计划
SELECT name FROM
(
SELECT id, name FROM people
) p
WHERE p.id = 1
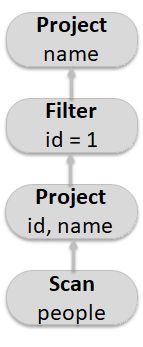
- 优化
1、在投影上面查询过滤器
2、检查过滤是否可下压

- 物理计划

SparkSQL API
- SparkContext
- SQLContext
Spark SQL的编程入口 - HiveContext
SQLContext的子集,包含更多功能 - SparkSession(Spark 2.x推荐)
SparkSession:合并了SQLContext与HiveContext
提供与Spark功能交互单一入口点,并允许使用DataFrame和Dataset API对Spark进行编程
1、无特殊说明时,下文中“spark”均指SparkSession实例
2、如果是spark-shell下,会自动创建“sc”和“spark”
val spark = SparkSession.builder
.master("master")
.appName("appName")
.getOrCreate()
Dataset
特定域对象中的强类型集合
scala> spark.createDataset(1 to 3).show
scala> spark.createDataset(List(("a",1),("b",2),("c",3))).show
scala> spark.createDataset(sc.parallelize(List(("a",1,1),("b",2,2)))).show
1、createDataset()的参数可以是:Seq、Array、RDD
2、上面三行代码生成的Dataset分别是:Dataset[Int]、Dataset[(String,Int)]、Dataset[(String,Int,Int)]
3、Dataset=RDD+Schema,所以Dataset与RDD有大部共同的函数,如map、filter等
使用case class创建Dataset
case class Point(label:String,x:Double,y:Double)
case class Category(id:Long,name:String)
val pointsRDD=sc.parallelize(List(("bar",3.0,5.6),("foo",-1.0,3.0)))
val categoriesRDD=sc.parallelize(List((1,"foo"),(2,"bar")))
val points=pointsRDD.map(line=>Point(line._1,line._2,line._3)).toDS
val categories=categories.map(line=>Category(line._1,line._2)).toDS
points.join(categories,points("label")===categories("name")).show
DataFrame
DataFrame=Dataset[Row]
类似传统数据的二维表格
在RDD基础上加入了Schema(数据结构信息)
DataFrame Schema支持嵌套数据类型:struct、map、array
提供更多类似SQL操作的API
/** 将JSON文件转成DataFrame
* people.json内容如下
* {"name":"Michael"}
* {"name":"Andy", "age":30}
* {"name":"Justin", "age":19}
*/
val df = spark.read.json("file:///home/hadoop/data/people.json")
// 使用show方法将DataFrame的内容输出
df.show
//DataFrame API常用操作
val df = spark.read.json("file:///home/hadoop/data/people.json")
// 使用printSchema方法输出DataFrame的Schema信息
df.printSchema()
// 使用select方法来选择我们所需要的字段
df.select("name").show()
// 使用select方法选择我们所需要的字段,并未age字段加1
df.select(df("name"), df("age") + 1).show()
// 使用filter方法完成条件过滤
df.filter(df("age") > 21).show()
// 使用groupBy方法进行分组,求分组后的总数
df.groupBy("age").count().show()
//sql()方法执行SQL查询操作
df.registerTempTable("people")
spark.sql("SELECT * FROM people").show
//RDD->DataFrame
//方式二:通过编程接口指定Schema
case class Person(name String,age Int)
val people=sc.textFile("file:///home/hadoop/data/people.txt")
// 以字符串的方式定义DataFrame的Schema信息
val schemaString = "name age"
//导入所需要的类
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{
StructType, StructField, StringType}
// 根据自定义的字符串schema信息产生DataFrame的Schema
val schema = StructType(schemaString.split(" ").map(fieldName =>StructField(fieldName,StringType, true)))
//将RDD转换成Row
val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// 将Schema作用到RDD上
val peopleDataFrame = spark.createDataFrame(rowRDD, schema)
// 将DataFrame注册成临时表
peopleDataFrame.registerTempTable("people")
val results = spark.sql("SELECT name FROM people")
results.show
//DataFrame->RDD
/** people.json内容如下
* {"name":"Michael"}
* {"name":"Andy", "age":30}
* {"name":"Justin", "age":19}
*/
val df = spark.read.json("file:///home/hadoop/data/people.json")
//将DF转为RDD
df.rdd.collect
SparkSQL操作外部数据源
Spark SQL支持的外部数据源
Parquet文件
Parquet文件:是一种流行的列式存储格式,以二进制存储,文件中包含数据与元数据
//Spark SQL写parquet文件
import org.apache.spark.sql.types.{
StructType, StructField, StringType,ArrayType,IntegerType}
val schema=StructType(Array(StructField("name",StringType),
StructField("favorite_color",StringType),
StructField("favorite_numbers",ArrayType(IntegerType))))
val rdd=sc.parallelize(List(("Alyssa",null,Array(3,9,15,20)),("Ben","red",null)))
val rowRDD=rdd.map(p=>Row(p._1,p._2,p._3))
val df=spark.createDataFrame(rowRDD,schema)
df.write.parquet("/data/users") //在该目录下生成parquet文件
//Spark SQL读parquet文件
val df=spark.read.parquet("/data/users") //该目录下存在parquet文件
df.show
df.printSchema
Hive表
Spark SQL与Hive集成:
1、hive-site.xml拷贝至${SPARK_HOME}/conf下
2、检查hive.metastore.uris是否正确
3、启动元数据服务:$hive service metastore
4、自行创建SparkSession,应用配置仓库地址与启用Hive支持
//创建一个Hive表
//hive>create table toronto(full_name string, ssn string, office_address string);
//hive>insert into toronto(full_name, ssn, office_address) values('John S. ', '111-222-333 ', '123 Yonge Street ');
//集成Hive后spark-shell下可直接访问Hive表
val df=spark.table("toronto")
df.printSchema
df.show
val spark = SparkSession.builder()
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
val df = spark.sql("select * from toronto")
df.filter($"ssn".startsWith("111")).write.saveAsTable("t1")
RDBMS表
$spark-shell --jars /opt/spark/ext_jars/mysql-connector-java-5.1.38.jar
val url = "jdbc:mysql://localhost:3306/metastore"
val tableName = "TBLS"
// 设置连接用户、密码、数据库驱动类
val prop = new java.util.Properties
prop.setProperty("user","hive")
prop.setProperty("password","mypassword")
prop.setProperty("driver","com.mysql.jdbc.Driver")
// 取得该表数据
val jdbcDF = spark.read.jdbc(url,tableName,prop)
jdbcDF.show
//DF存为新的表
jdbcDF.write.mode("append").jdbc(url,"t1",prop)
SparkSQL函数
内置函数

内置函数的使用:
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{
IntegerType, StringType, StructField, StructType}
val accessLogRDD = sc.parallelize(accessLog).map(row => {
val splited = row.split(",")
Row(splited(0), splited(1).toInt)
})
val structTypes = StructType(Array(
StructField("day", StringType, true),
StructField("userId", IntegerType, true)
))
//根据数据以及Schema信息生成DataFrame
val accessLogDF = spark.createDataFrame(accessLogRDD, structTypes)
//导入Spark SQL内置的函数
import org.apache.spark.sql.functions._
//求每天所有的访问量(pv)
accessLogDF.groupBy("day").agg(count("userId").as("pv")).select("day", "pv").collect.foreach(println)
//求每天的去重访问量(uv)
accessLogDF.groupBy("day").agg(countDistinct('userId).as("uv")).select("day", "uv").collect.foreach(println)
自定义函数
case class Hobbies(name: String, hobbies: String)
val info = sc.textFile("/data/hobbies.txt")
//需要手动导入一个隐式转换,否则RDD无法转换成DF
import spark.implicits._
val hobbyDF = info.map(_.split("\t")).map(p => Hobbies(p(0), p(1))).toDF
hobbyDF.show
hobbyDF.registerTempTable("hobbies")
//注册自定义函数,注意是匿名函数
spark.udf.register("hobby_num", (s: String) => s.split(',').size)
spark.sql("select name, hobbies, hobby_num(hobbies) as hobby_num from hobbies").show
Spark性能优化
序列化
Java序列化,Spark默认方式
Kryo序列化,比Java序列化快约10倍,但不支持所有可序列化类型
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
//向Kryo注册自定义类型
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]));
使用对象数组、原始类型代替Java、Scala集合类(如HashMap)
避免嵌套结构
尽量使用数字作为Key,而非字符串
以较大的RDD使用MEMORY_ONLY_SER
加载CSV、JSON时,仅加载所需字段
仅在需要时持久化中间结果(RDD/DS/DF)
避免不必要的中间结果(RDD/DS/DF)的生成
DF的执行速度比DS快约3倍
自定义RDD分区与spark.default.parallelism
该参数用于设置每个stage的默认task数量
将大变量广播出去,而不是直接使用
尝试处理本地数据并最小化跨工作节点的数据传输
表连接(join操作)
包含所有表的谓词(predicate)
select * from t1 join t2 on t1.name = t2.full_name
where t1.name = 'mike' and t2.full_name = 'mike'
最大的表放在第一位
广播最小的表
最小化表join的数量
Spark性能优化指南高级篇
SparkGraphX 图形数据分析
为什么需要图计算:
- 许多大数据以大规模图或网络的形式呈现
- 许多非图结构的大数据,常会被转换为图模型进行分析
- 图数据结构很好地表达了数据之间的关联性
图的基本概念
- 图是由顶点集合(vertex)及顶点间的关系集合,边(edge)组成的一种网状数据结构
通常表示为二元组:Gragh=(V,E)
可以对事物之间的关系建模 - 应用场景
在地图应用中寻找最短路径
社交网络关系
网页间超链接关系
图的术语:
- 顶点(Vertex)
- 边(Edge)

-
有向图:

-
无向图:

-
有环图:
包含一系列顶点连接的回路(环路) -
无环图
DAG即为有向无环图
- 度
一个顶点所有边的数量
出度:指从当前顶点指向其他顶点的边的数量
入度:其他顶点指向当前顶点的边的数量

- 图的经典表示方法
邻接矩阵

1、对于每条边,矩阵中相应单元格值为1
2、对于每个循环,矩阵中相应单元格值为2,方便在行或列上求得顶点度数
GraphX核心抽象
弹性分布式属性图(Resilient Distributed Property Graph):
-
顶点和边都带属性的有向多重图

-
一份物理存储,两种视图

GraphX API
Graph[VD,ED]
VertexRDD[VD]
EdgeRDD[ED]
EdgeTriplet[VD,ED]
Edge:样例类
VertexId:Long的别名
演示实例1:创建graph
scala> val users = sc.parallelize(Array((3L,("rxin","student")),(7L,("jgonzal","postdoc")),(5L,("franklin","professor")),(2L,("istoica","professor"))))
users: org.apache.spark.rdd.RDD[(Long, (String, String))] = ParallelCollectionRDD[49] at parallelize at <console>:27
scala> val relationship = sc.parallelize(Array(Edge(3L,7L,"Colla"),Edge(5L,3L,"Advisor"),Edge(2L,5L,"Colleague"),Edge(5L,7L,"Pi")))
relationship: org.apache.spark.rdd.RDD[org.apache.spark.graphx.Edge[String]] = ParallelCollectionRDD[50] at parallelize at <console>:27
scala> val graphUser = Graph(users, relationship)
graphUser: org.apache.spark.graphx.Graph[(String, String),String] = org.apache.spark.graphx.impl.GraphImpl@40bfabed
演示实例2:创建graph
scala> val userRdd = sc.makeRDD(
Array(
(1L,("Alice",28)),
(2L,("Bob",27)),
(3L,("Charlie",65)),
(4L,("David",42)),
(5L,("Ed",55)),
(6L,("Fran",50))
)
)
userRdd: org.apache.spark.rdd.RDD[(Long, (String, Int))] = ParallelCollectionRDD[69] at makeRDD at <console>:27
scala> val usercallRdd = sc.makeRDD(
Array(
Edge(2L,1L,7),
Edge(3L,2L,4),
Edge(4L,1L,1),
Edge(2L,4L,2),
Edge(5L,2L,2),
Edge(5L,3L,8),
Edge(3L,6L,3),
Edge(5L,6L,3)
)
)
usercallRdd: org.apache.spark.rdd.RDD[org.apache.spark.graphx.Edge[Int]] = ParallelCollectionRDD[70] at makeRDD at <console>:27
scala> val userCallGraph = Graph(userRdd,usercallRdd)
userCallGraph: org.apache.spark.graphx.Graph[(String, Int),Int] = org.apache.spark.graphx.impl.GraphImpl@db8615d
pregel函数
转载自:SparkGraphX中的pregel函数