十 Flink实现双流join
文章目录
- 1 基于时间的双流join
-
- 1.1 用法:
- 1.2 案例
- 2 基于窗口做双流join
-
- 2.1 案例:
- 3 使用connect 和 CoProcessFunction实现join
1 基于时间的双流join
基于间隔的 Join 会对两条流中拥有相同键值以及彼此之间时间戳不超过某一指定间隔的事件进行 Join。
基于时间间隔的 Join 目前只支持事件时间以及 INNER JOIN 语义
1.1 用法:
input1
.keyBy(...)
.between(<lower-bound>, <upper-bound>) // 相对于 input1 的上下界
.process(ProcessJoinFunction) // 处理匹配的事件对
between(Time.minute(50), Time.minute(5))
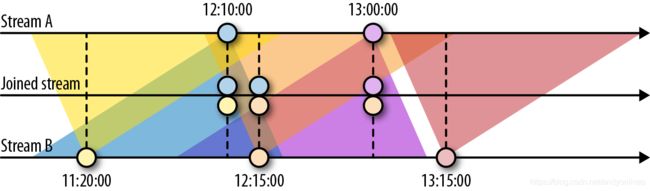
下图展示了两条流(A 和 B)上基于间隔的 Join,如果 B 中事件的时间戳相较于 A 中事件的时间戳不早于 50 分钟且不晚于 5 分钟,则会将两个事件 Join 起来。 Join 间隔具有对称性,因此上面的条件也可以表示为 A 中事件的时间戳相较 B 中事件的时间戳不早于 5 分钟且不晚于 50 分钟。
比如:stream A 为12:10:00 的时间戳会和stream B 中的时间范围 11:20:00~12:15:00 的数据进行join
计算公式:stream B的范围 = stream A timestamp - lower-bound 到 stream A timestamp - upper-bound
那相对于stream B 12:15:00 的时间戳会和stream A 中的时间范围 12:10:00~13:15:00 的数据进行join
计算公式:stream A的范围 = stream B timestamp - upper-bound 到 stream A timestamp - lower-bound
1.2 案例
package org.example.join
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
/**
* 实现两个流的join
*/
object IntervalJoinExample {
// 用户点击日志
case class UserClickLog(userID: String,
eventTime: String,
eventType: String,
pageID: String)
// 用户浏览日志
case class UserBrowseLog(userID: String,
eventTime: String,
eventType: String,
productID: String,
productPrice: String)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
/**
* 产生用户数据流
*/
val clickStream = env
.fromElements(
UserClickLog("user_2", "1500", "click", "page_1"), // (900, 1500)
UserClickLog("user_2", "2000", "click", "page_1") // (1400, 2000)
)
.assignAscendingTimestamps(_.eventTime.toLong * 1000L)
.keyBy(_.userID)
val browseStream = env
.fromElements(
UserBrowseLog("user_2", "1000", "browse", "product_1", "10"), // (1000, 1600)
UserBrowseLog("user_2", "1500", "browse", "product_1", "10"), // (1500, 2100)
UserBrowseLog("user_2", "1501", "browse", "product_1", "10"), // (1501, 2101)
UserBrowseLog("user_2", "1502", "browse", "product_1", "10") // (1502, 2102)
)
.assignAscendingTimestamps(_.eventTime.toLong * 1000L)
.keyBy(_.userID)
/**
* 实现双流join
*/
clickStream.intervalJoin(browseStream)
.between(Time.minutes(-10), Time.seconds(0)) //定义上下界为(-10,0)
.process(new MyIntervalJoin)
.print()
env.execute()
}
/**
* 处理函数
*/
class MyIntervalJoin extends ProcessJoinFunction[UserClickLog, UserBrowseLog, String] {
override def processElement(left: UserClickLog, right: UserBrowseLog, ctx: ProcessJoinFunction[UserClickLog, UserBrowseLog, String]#Context, out: Collector[String]): Unit = {
out.collect(left + " ==> " + right)
}
}
}
输出结果
UserClickLog(user_2,1500,click,page_1) ==> UserBrowseLog(user_2,1000,browse,product_1,10)
UserClickLog(user_2,1500,click,page_1) ==> UserBrowseLog(user_2,1500,browse,product_1,10)
UserClickLog(user_2,2000,click,page_1) ==> UserBrowseLog(user_2,1500,browse,product_1,10)
UserClickLog(user_2,2000,click,page_1) ==> UserBrowseLog(user_2,1501,browse,product_1,10)
UserClickLog(user_2,2000,click,page_1) ==> UserBrowseLog(user_2,1502,browse,product_1,10)
2 基于窗口做双流join
顾名思义,基于窗口的 Join 需要用到 Flink 中的窗口机制。其原理是将两条输入流中的元素分配到公共窗口中并在窗口完成时进行 Join(或 Cogroup)。
用法:
input1.join(input2)
.where(...) // 为 input1 指定键值属性
.equalTo(...) // 为 input2 指定键值属性
.window(...) // 指定 WindowAssigner
[.trigger(...)] // 选择性的指定 Trigger
[.evictor(...)] // 选择性的指定 Evictor
.apply(...) // 指定 JoinFunction
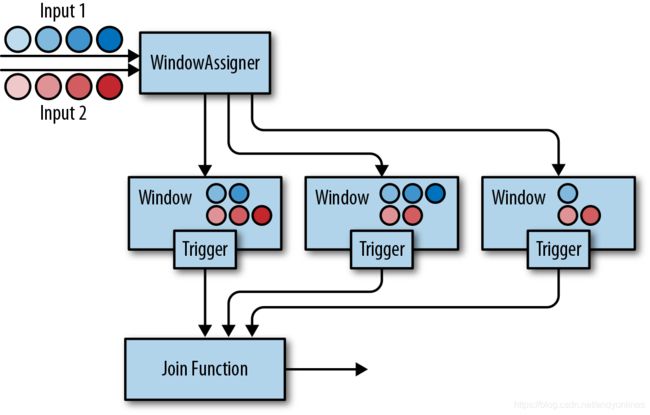
两条输入流都会根据各自的键值属性进行分区,公共窗口分配器会将二者的事件映射到公共窗口内(其中同时存储了两条流中的数据)。当窗口的计时器触发时,算子会遍历两个输入中元素的每个组合(叉乘积)去调用 JoinFunction。同时你也可以自定义触发器或移除器。
由于两条流中的事件会被映射到同一个窗口中,因此该过程中的触发器和移除器与常规窗口算子中的完全相同。
除了对窗口中的两条流进行 Join,你还可以对它们进行 Cogroup,只需将算子定义开始位置的 join 改为 coGroup() 即可。 Join 和 Cogroup 的总体逻辑相同,二者的唯一区别是: Join 会为两侧输入中的每个事件对调用 JoinFunction;而 Cogroup 中用到的 CoGroupFunction 会以两个输入的元素遍历器为参数,只在每个窗口中被调用一次。
2.1 案例:
package org.example.join
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object WindowJoin {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val orangeStream = env
.fromElements((1, 1999L), (1, 2001L))
.assignAscendingTimestamps(_._2)
val greenStream = env
.fromElements((1, 1001L), (1, 1002L), (1, 3999L))
.assignAscendingTimestamps(_._2)
orangeStream.join(greenStream)
.where(r => r._1) // 第一条流使用`_1`字段做keyBy
.equalTo(r => r._1) // 第二条流使用`_1`字段做keyBy
.window(TumblingEventTimeWindows.of(Time.seconds(2)))
.apply {
(e1, e2) => e1 + " *** " + e2 }
.print()
env.execute()
}
}
3 使用connect 和 CoProcessFunction实现join
package test5
import test2.{
SensorReading, SensorSource}
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.functions.co.CoProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object CoProcessFunctionExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 无限流
val readings = env
.addSource(new SensorSource)
.keyBy(_.id)
// 有限流
val filterSwitches = env
.fromElements(
("sensor_2", 10 * 1000L),
("sensor_7", 60 * 1000L)
)
.keyBy(_._1)
readings
.connect(filterSwitches)
.process(new ReadingFilter)
.print()
env.execute()
}
class ReadingFilter extends CoProcessFunction[SensorReading, (String, Long), SensorReading] {
// 初始化传送数据的开关,默认值是false
// 只针对当前key可见的状态变量
lazy val forwardingEnabled = getRuntimeContext.getState(
new ValueStateDescriptor[Boolean]("filter-switch", Types.of[Boolean])
)
override def processElement1(value: SensorReading, ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context, out: Collector[SensorReading]): Unit = {
// 处理第一条流,无限流
// 如果开关是true,将传感器数据向下游发送
if (forwardingEnabled.value()) {
out.collect(value)
}
}
override def processElement2(value: (String, Long), ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context, out: Collector[SensorReading]): Unit = {
// 处理第二条流,有限流,只会被调用两次
forwardingEnabled.update(true) // 打开开关
// `value._2`是开关打开的时间
val timerTs = ctx.timerService().currentProcessingTime() + value._2
ctx.timerService().registerProcessingTimeTimer(timerTs)
}
override def onTimer(timestamp: Long, ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#OnTimerContext, out: Collector[SensorReading]): Unit = {
forwardingEnabled.update(false) // 关闭开关
}
}
}