写在前面
提到React时我们脑中可能第一想法就是虚拟DOM和diff算法,也正是因为这两个东西的存在,才会让我们不必担心由于频繁操作DOM带来的性能上的瓶颈,React本身在这方面已经做得足够隔离了,我们其实不用过于关注也能写出不错性能的代码,要想深入扒开diff算法的具体实现不是易事,这里我们尽量形象的浅尝辄止分析一下.
diff策略
传统diff算法:当我们在对比两个对象树的差异时,传统的diff算法是利用循环递归的方式对所有节点依次对比,算法的复杂度为O(n * n * n),其中n为节点总数,怎么样看起来很恐怖吧,试想一个大项目中DOM树的节点树的立方...所以显然如果react不对传统的diff算法进行优化的话那么在大项目中的性能将会存在极大瓶颈,这里额外说一下,diff算法最早不是脸书团队提出来的.
react-diff:
这里react团队对传统diff算法优化主要基于三个策略,而这些策略最后都是对比vdom(网上很多帖子,包括书里介绍这部分的时候可能会比较隐晦难理解,我这里通俗总结了下):
1.DOM结构发生改变-----直接卸载并重新creat
2.DOM结构一样-----不会卸载,但是会update
3.所有同一层级的子节点.他们都可以通过key来区分-----同时遵循1.2两点
先看第一种情况,假设目前前后两次DOM树如下图,那么diff算法具体怎么实现的呢?我们通过console.log更为直观的看一下结果(console.log的状态分别放在对应组件的生命周期里,其中以B组件为例,其他组件也雷同,代码如下,如果有疑惑的同学可以翻看我以前生命周期的文章或者观看别人的文章)
class B extends React.Component{
constructor(props){
super(props)
console.log('B is creat')
}
componentDidMount(){
console.log('B is did')
}
componentDidUpdate() {
console.log('B is updated.');
}
componentWillUnmount(){
console.log('B is unmount')
}
render(){
return(
B
{this.props.children}
)
}
}
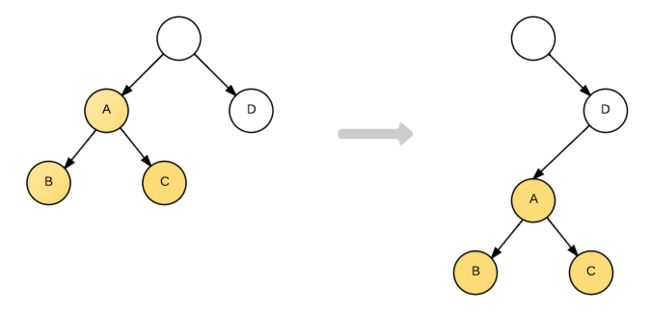
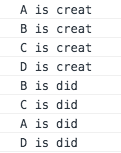
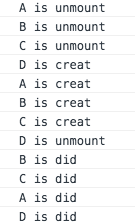
我们看到react-diff算法是趋近于'暴力'的方式,并不是把A,B,C转移到D节点下面,这也就印证了我们所说的第一个策略,也是通用的策略,react-diff如果检测DOM树不一样的情况就会直接销毁当前节点(包括当前节点的所有子节点).另外值得一提的根据打印的顺序我们也可以知道react渲染原则也是和JS执行的顺序原则是一样的:
从左至右,从上到下
接下来看第二种策略,这次我们不改变DOM结构,只改变A节点的颜色,打印结果如下图:
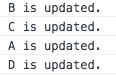
结果很明显,只是单纯的update,没有销毁及重新创建任何DOM节点...
所以根据以上的结果我们可以知道,要想最大化的实现diff算法的性能,我们在项目中尽量不改变DOM结构.比如插入DOM,删除DOM,最好用visibility:hidden这样的属性.但是理想总归是美好的,实际项目中有很多情况需要做删除节点等操作,那么应该怎么办呢?其实react团队早就想好了相关的解决方案,比如key.
不可小觑的key
我们最开始写react的时候应该都见过这样一个warn:
这是由于我们在循环渲染列表时候(map)时候忘记标记key值报的警告,既然是警告,就说明即使没有key的情况下也不会影响程序执行的正确性.其实这个key的存在与否只会影响diff算法的复杂度,换言之,你不加key的情况下,diff算法就会以暴力的方式去根据一二的策略更新,但是你加了key,diff算法会引入一些另外的操作,这里不做赘述,有兴趣的可以自己查阅一下.
加了key的好处:
其实key值不一定要在map的时候才去加,即使不map得时候也可以加,而且正确的加上key值还会带来一定程度上的性能优化,我们回归一下,对初始DOM树种的B,C调换位置,以下是不加key值得情况:
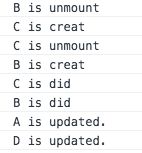
以下是加key的情况,代码和打印结果如下:
return(
)
return(
)
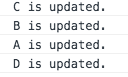
结果显而易见...
我们该不该把map的index作为key
我们在给循环渲染时总是会把index值或者随机一个值作为key,比如以下代码:
arr.map((val,index)=>{
return(
val
)
})
那么这样做好不好呢?我们可以思考下,key做为DOM节点标识,如果是前后两次arr分别为[1,2,3,4]和[5,6,7,8]和前后两次arr分别为[1,2,3,4]和[4,3,2,1]的情况,很明显前者可以认为是DOM改变了,后者可以认为是DOM节点的位移操作,那么对于第一种情况来说index作为key和没有key值无区别,但是第二种情况用index作为key值效果没有比用数据本身作为key值好,这里大家可以按照以上方式打印去看一下.所以结论是如果你的数据能确保唯一性,就用数据本身作为key值吧....
key值必须唯一且不重复么
答案是未必,前提条件是是否同一父节点,也就是是否同一data-reactId的节点,也就是说如下代码是没问题的:
写到这里我们应该粗略的大致了解diff算法的策略和key值一些作用了.如果想了解更多的话建议多查阅资料或者潜心直接扒源码去看一下.
写在最后
diff算法并不是万能的,diff算法其实也有不够完全尽如人意的重渲染方式.所以我们在写react代码想要最大化性能的时候还是要注意DOM树的结构以及灵活运用一些不起眼的属性
如果有不对的地方可以直接留言或者mail:[email protected]