自己理解的意思:meta提供了HTML文档的元数据,他不会显示到页面中,但是机器可以识别。
meta主要有两个属性:第一是name,第二是http-equiv
下面将具体介绍meta标签
之前在学习meta标签时只有这一句话
简介
W3cschool英文版中对meta的解释
The tag provides metadata about the HTML document. Metadata will not be displayed on the page, but will be machine parsable.
翻译过来的意思就是:meta标签时用来表示HTML文档的元数据,他不会显示在页面上,但是会被机器解析。
用处
Meta elements are typically used to specify page description, keywords, author of the document, last modified, and other metadata。The metadata can be used by browsers (how to display content or reload page), search engines (keywords), or other web services
这句话会meta标签用处的介绍,简洁明了。
翻译过来就是:meta常用语定义页面的说明,关键字,最后修改时间,和其他的元数据。这些元数据将服务于浏览器(如何布局或重载页面),搜索引擎和其他服务。
组成
meta标签共有两个属性,分别是http-equiv和name属性
1 name属性
那么属性主要用于面熟网页,比如网页关键字,叙述等。与之对应的属性值是content,content中的内容是对name填入类型的具体描述,便于搜索引擎抓取。
mate标签name属性的语法格式
其中那么属性值共有以下几种参数。(A-C为常用属性)
A. keyword(关键字)
说明:用于告诉引擎,你的网页的关键字
举例:
B. description(网站内容的描述)
说明:用于告诉引擎,你的网站的主要内容
举例:
C. viewport(移动端的窗口)
说明:这个概念比较复杂,具体会在下片文章中讲述
这个属性用于设计移动端页面。在bootstrap,AmazeUI等框架都有用到viewport。
举例:
D. robots(定义搜索引擎爬虫的索引方式)
说明:robots用来告诉爬虫哪些页面需要索引,哪些页面不需要索引。
content的参数有all,none,index,noindex,follow,nofollow。默认是all。
举例:
具体参数如下:
1.none : 搜索引擎将忽略此网页,等价于noindex,nofollow。
2.noindex : 搜索引擎不索引此网页。
3.nofollow: 搜索引擎不继续通过此网页的链接索引搜索其它的网页。
4.all : 搜索引擎将索引此网页与继续通过此网页的链接索引,等价于index,follow。
5.index : 搜索引擎索引此网页。
6.follow : 搜索引擎继续通过此网页的链接索引搜索其它的网页。
E. author(作者)
说明:用于标注网页作者
举例 :
F. generator(网页制作软件)
说明:用于标明网页是什么软件做的
举例: (不知道能不能这样写):
G. copyright(版权)
说明:用于标注版权信息
举例:
//代表网站为cy的个人版权所有
H. revisit-after(搜索引擎爬虫重访时间)
说明:如果页面不是经常更新,为了减轻搜索引擎爬虫对服务器带来的压力,可以设置一个爬虫的重访时间。如果重访时间过短,爬虫将按它们定义的默认时间来访问。
举例:
I. renderer(双核浏览器渲染方式)
说明:renderer是为双核浏览器准备的,用于指定双核浏览器默认以何种方式渲染页面。比如说360浏览器。
举例:
//默认webkit内核
// 默认IE兼容模式
//默认为IE兼容模式
2 .http-equiv属性
http-equiv顾明思议就是“相当于Http文件头”的意思
equiv全拼为equivalent,意思为相等、相当于
meta标签中http-equiv属性语法格式:
其中http-equiv属性主要有以下几种参数:
A. content-Type(设定网页字符集)(推荐使用HTML5的方式)
说明:用于设定网页字符集,便于浏览器解析与渲染页面
举例:
// 旧的HTML,不推荐
// HTML5设定网页字符集的方式,推荐使用UTF-8
B. X-UA-Compatible(浏览器采取何种版本渲染当前页面)
说明:用于告知浏览器以何种版本来渲染页面。(一般都设置为最新模式,在各大框架中这个设置也很常见。)
举例:
//指定IE和Chrome使用最新版本渲染当前页面
C. cache-control(指定请求和响应遵循的缓存机制)
用法1.
说明:指导浏览器如何缓存某个响应以及缓存多长时间。这一段内容我在网上找了很久,但都没有找到满意的。
最后终于在Google Developers中发现了我想要的答案
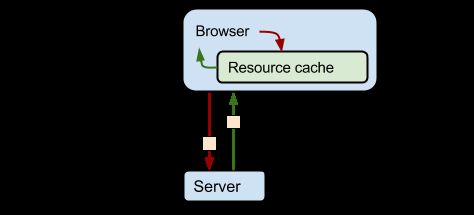
举例:
共有以下几种用法:
1、no-cache: 先发送请求,与服务器确认该资源是否被更改,如果未被更改,则使用缓存。
2、no-store: 不允许缓存,每次都要去服务器上,下载完整的响应。(安全措施)
3、public : 缓存所有响应,但并非必须。因为max-age也可以做到相同效果
4、private : 只为单个用户缓存,因此不允许任何中继进行缓存。(比如说CDN就不允许缓存private的响应)
5、maxage : 表示当前请求开始,该响应在多久内能被缓存和重用,而不去服务器重新请求。例如:max-age=60表示响应可以再缓存和重用 60 秒。
参考链接:HTTP缓存
用法2.(禁止百度自动转码)
说明:用于禁止当前页面在移动端浏览时,被百度自动转码。虽然百度的本意是好的,但是转码效果很多时候却不尽人意。所以可以在head中加入例子中的那句话,就可以避免百度自动转码了。
举例:
D. expires(网页到期时间)
说明:用于设定网页的到期时间,过期后网页必须到服务器上重新传输。
举例:
E. refresh(自动刷新并指向某页面)
说明:网页将在设定的时间内,自动刷新并调向设定的网址。
举例:
//意思是2秒后跳转向我的博客
F. Set-Cookie(cookie设定)
说明:如果网页过期。那么这个网页存在本地的cookies也会被自动删除。
举例:
//格式
//具体范例
最后
暂时总结的就这么多了,meta标签的自定义属性实在太多了。所以只去找了常用的一些,还有像Window-target这样已经基本被废弃的属性,我也没有添加。