多集群监控组件Thanos
简介
目前Prometheus已经成为Kubernetes集群事实上的标准监控解决方案。然而Prometheus的重点只放在对近期监控指标数据的操作上,这使得监控数据的本地存储在可扩展性和持久化方面受到单个节点的限制,Prometheus本身也并不试图去解决这些问题,而是专注做好其本身的核心功能,如监控指标的抓取,存储,查询与告警等;将可扩展性和持久化等问题的解决方案交给其它开源组件。目前这方面的解决方案主要有:
-
M3DB
M3DB可以收集大量的监控时间序列数据,然后以一种水平可扩展的方式来分配监控数据的存储,从而最有效地利用存储硬件。 -
Cortex
Cortex为Prometheus提供水平可扩展、高可用性(HA)、多租户、长期存储。 -
Thanos
Thanos是基于Prometheus的具有高可用(HA)、存储持久化,多集群查询功能的监控解决方案。选择Thanos的主要原因:- 所有组件都是无状态的(stateless)
- 监控数据和所有状态信息被持久化到对象存储(OSS)
- 服务之间通过稳定的StoreAPI对接
- 支持高可用的Prometheus部署(防止Prometheus单点故障)
- 最重要的一点,Thanos是CNCF项目
Thanos功能组件
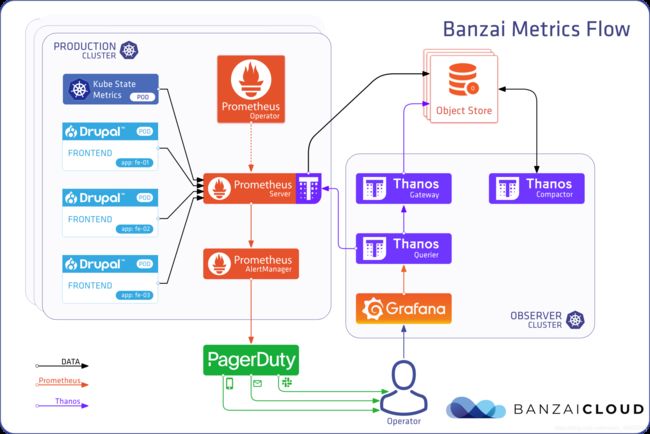
-
Sidecar
- 作为Prometheus运行Pod中的Sidecar容器
- 将Prometheus的数据块(chuncks)上传到对象存储(OSS)
- 支持多种对象存储(OSS),如Aliyun、腾讯云、S3、Google云存储、Azure存储等
- 可无缝集成在Prometheus operator中进行部署
-
Store
- 从对象存储(OSS)中检索块(chunks),以便查询长周期的监控指标
- 支持基于时间(time-based)的分区查询
- 支持基于标签(label-based)的分区查询
-
Compact
- 为OSS中的监控数据创建降采样块(Downsampled chunks),以加快长周期范围的数据查询
-
Query
- 作为PromQL查询入口(替代Prometheus查询)
- 消除来自不同数据源(多个Store)的重复数据
- 支持部分响应
-
Rule
- 一个简化版的Prometheus(主要使用rule功能,不抓数据,不做PromQL解析查询)
- 以Prometheus2.0存储格式将结果写入OSS
- 主要作为Rule存储节点(通过StoreAPI将TSDB块上传至OSS)
-
Bucket
- 监视对象存储Bucket中存储的监控数据
Thanos主要优势
降采样(DOWNSAMPLING)
在Thanos中进行降采样(DOWNSAMPLING)的目的不是为了节省磁盘空间。它的主要好处是使长周期范围的数据查询(如数月或数年)变得更快。事实上降采样并不会节省任何空间,它为每个原始块添加多了两个新块,它们略小于或接近原始块的大小。这意味着,降采样稍微增加了存储空间使用量,但在查询长周期范围时,它提供了巨大的性能和带宽占用优势。
三个粒度的块(chunks):
- raw — Prometheus的原始metrics块
- 5m — 原始metrics块的5分钟压缩块
- 1h —原始metrics块的1小时压缩块
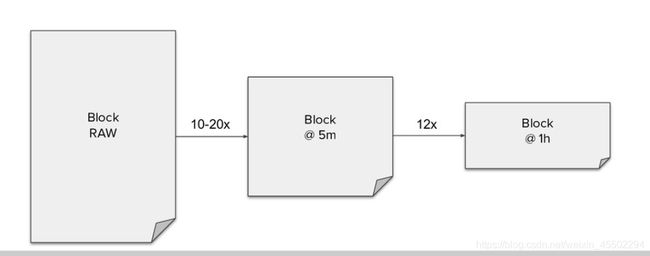
使用压缩块查询的优势对比:

在没有降采样块的情况下查询长周期范围意味着必须下载和处理与范围长度成比例的数据量。在1y示例中,我们将看到,降采样后就不需要下载20亿个样本(2GB,Prometheus默认15秒一个采样数据),而只需要获取和处理800万个样本(9MB),就足以呈现一个年度图表,这将带来很大的性能改进,并减少了很多带宽使用。
查询(QUERY)
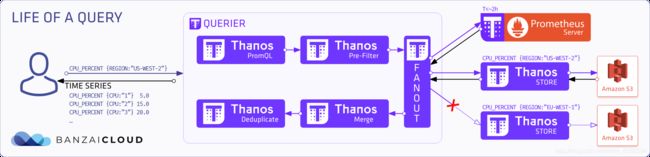
- 查询器(Querier)接收到PromQL查询
-
解释PromQL查询并转到预过滤器(pre-filter)
-
根据标签(labels)和时间范围(time-range),分发查询到不同的Store、Prometheus或其他Querier
-
Querier只发送和接收StoreAPI消息
-
如果已启用重复数据消除功能,则会对所有查询结果进行merge
-
最后返回查询到的数据序列

面对大量的存储数据,Thanos有两种横向扩展方式,一种是基于时间的分区(TIME-BASED),一种是基于标签的分区(LABEL-BASED)。
基于时间的分区(TIME-BASED)
默认情况下,Thanos的存储网关(Store Gateway)查看对象存储(OSS)中的所有数据,并根据查询的时间范围返回这些数据。所有StoreAPI源都会公布可用的最短和最长时间。我们可以使用这些参数来缩小这个分区的范围,此参数可以是相对时间,也可以是具体日期。如
- A:
max-time=-6w - B:
min-time=-8wandmax-time=-2w - C:
min-time=-3w
基于标签的分区(LABEL-BASED)
基于标签的分区类似于基于时间的分区,所有StoreAPI源都会公布可用的LABEL序列的相关标签,,这些标签来自Prometheus的external标签,并基于Thanos组件显式设置标签。
重复数据消除(DEDUPLICATION)
在Thanos架构中我们可以使用多个相同的Prometheus实例来实现高可用(HA),以防止Prometheus单点故障。Thanos提供了查询结果的重复数据消除功能,从而可以实现Prometheus查询无缝对接。为了实现这一点,我们只需要在sidecar组件上设置一个或多个副本标签,其余的由query组件完成。如:
Prometheus + sidecar “A”: cluster=1,env=2,replica=A
Prometheus + sidecar “B”: cluster=1,env=2,replica=B
Prometheus + sidecar “A” in different cluster: cluster=2,env=2,replica=A查询示例: up{job="prometheus",env="2"}. 重复数据消除功能开户后:
up{job="prometheus",env="2",cluster="1"} 1
up{job="prometheus",env="2",cluster="2"} 1没有开启重复数据消除功能:
up{job="prometheus",env="2",cluster="1",replica="A"} 1
up{job="prometheus",env="2",cluster="1",replica="B"} 1
up{job="prometheus",env="2",cluster="2",replica="A"} 1使用Thanos Operator部署
单集群
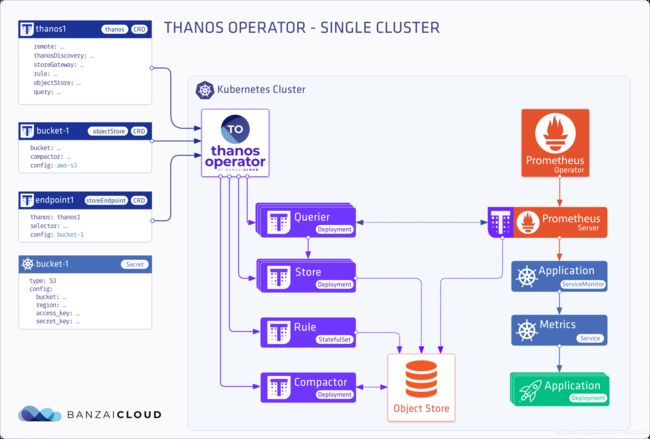
可以看到蓝色为无状态服务(stateless),橙色为有状态服务
//编辑prometheus-operator的value.ymal文件开启thanos sidecar(待补充)
//安装、删除prometheus-operator
helm template ./charts/prometheus-operator --name tpo --namespace monitor | kubectl apply --validate=false -f -
helm template ./charts/prometheus-operator --name tpo --namespace monitor | kubectl delete --ignore-not-found=true -f -
//下载Thanos Operator
helm repo add banzaicloud-stable https://kubernetes-charts.banzaicloud.com
helm fetch --untar --untardir ./charts banzaicloud-stable/thanos
//编辑value.ymal文件(待补充)
//手动安装Thanos
helm template ./charts/thanos --name t-thanos --namespace monitor | kubectl -n monitor apply --validate=false -f -
helm template ./charts/thanos --name t-thanos --namespace monitor | kubectl -n monitor delete --ignore-not-found=true -f -
多集群

可以看到蓝色为无状态服务(stateless),橙色为有状态服务