【文献阅读】VQA-E——一种对预测答案解释的模型和数据集(Q. Li等人,ECCV,2018)
一、文章背景
文章题目《VQA-E: Explaining, Elaborating, and Enhancing Your Answers for Visual Questions》
文章下载地址:http://openaccess.thecvf.com/content_ECCV_2018/papers/Qing_Li_VQA-E_Explaining_Elaborating_ECCV_2018_paper.pdf、
二、文章导读
摘要部分:
Most existing works in visual question answering (VQA) are dedicated to improving the accuracy of predicted answers, while disregarding the explanations. We argue that the explanation for an answer is of the same or even more importance compared with the answer itself, since it makes the question answering process more understandable and traceable. To this end, we propose a new task of VQA-E (VQA with Explanation), where the models are required to generate an explanation with the predicted answer. We first construct a new dataset, and then frame the VQA-E problem in a multi-task learning architecture. Our VQA-E dataset is automatically derived from the VQA v2 dataset by intelligently exploiting the available captions. We also conduct a user study to validate the quality of the synthesized explanations . We quantitatively show that the additional supervision from explanations can not only produce insightful textual sentences to justify the answers, but also improve the performance of answer prediction. Our model outperforms the state-of-the-art methods by a clear margin on the VQA v2 dataset.
现在VQA的大部分工作都能提高预测答案的精度,而却丢失了它的可解释性 。作者认为,对答案的解释可能比答案本身更重要,它能使问答的过程更好的理解和追踪。本文主作者提出了VQA-E ,能为每一个预测答案生成一个解释。作者首先提出了一个新的数据集VQA-E dataset,然后基于多任务学习模型来处理VQA。
该数据集VQA-E dataset来自于VQA v2,通过看图说话的方式来添加解释,并用用户学习的方式来验证合成的解释。结果表明,这些解释作为额外的监督信息,不仅能够处理深刻的文本句子来评判答案,还能够改善答案预测的结果。
三、文章详细介绍
VQA近些年来的主要进展在于使用了注意力机制和多模态融合以预测答案。尽管他们的性能在显著提高,然而人类在没有任何解释的情况下,并没有真正理解模型后面的决策机制。一种比较好的思路就是用attention,找到关注的attended regions,但是这样做也不能够清楚的对注意力视觉区域进行判断,比如尽管得到正确的regions但是却得到了错误的答案。因此这篇文章主要关注VQA模型的可解释性。
文本解释的另一个优点在于能够为答案提供更多的信息,如下图所示,A是生成的答案,E是解释:

尽管这些解释非常有用的,但可惜的是,在大部分VQA数据集上如COCO-QA , Visual7W等数据集上是没有任何解释的。
本文中作者需要解决的任务是VQA- E (VQA with explained),在模型VQA-E中,对最终的答案还要进一步生成一个解释,整个实验分成了两步,第一步,构建一个新的数据集,该数据集来自于VQA v2,第二步,涉及模型,能够预测答案的同时生成解释。
1.相关工作
VQA中的注意力机制(Attention in Visual Question Answering):在VQA中,问题用作查询来搜索图像中的相关区域。有些文献中提出了使用一种堆叠注意力模型,对模型进行多次查询,逐步推出答案。除了视觉注意之外,还有学者用分层问题-图像共同注意力关注图像中的相关区域和问题中的关键词。还有双重注意力网络,通过多重推理,校正视觉和文本注意力。尽管注意力是一个很好的解释思路,但对一视觉受损的人来说,仍然难以应用。
对模型的解释(Model with Explanations):最近有很多工作,试图解释深度学习模型的决策问题,由于是端到端的训练,因此是一个黑盒过程。有学者为鸟类的分类提出了一个可解释的模型,但不适用于VQA,针对这个问题,提出了适用于VQA的多模态解释模型。
2.VQA-E数据集
(1)合成解释(Explanation Synthesis)
方法(Approach):第一步:找到问题和答案最相关一段描述,图像描述用C表示,答案用A表示,问题用Q表示,用GloVe进行词嵌入,分别记为Wc,Wa,Wq,然后根据下式两两计算之间的相似性:

对每个问题答案组,都能找到最相关的描述和相似度评分,然后再用Term Frequency和 Inverse Document Frequency复杂的技术来调整不同单词的权重,最后发现方程1中的最大均值效果能好一些。
为了能够生成一个好的解释,将问答对和最相关的解释进行融合。首先,将问题和答案合并成一个陈述语句,然后通过对齐和段落分支(constituency parse trees)合并的放式,对陈述句和描述进行融合,最后再对合成的句子进行语法纠错得到最终解释。得到的最终解释,用公式1计算相似度,如下图所示:
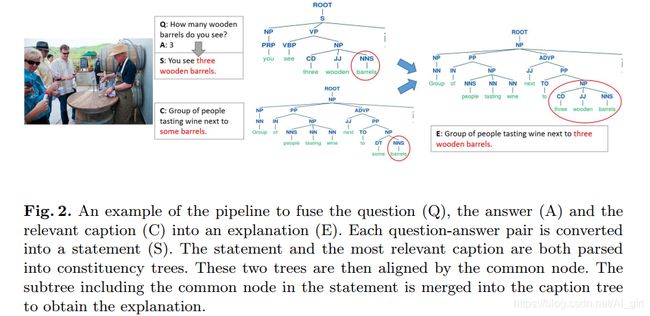
极大相似分布(Similarity distribution):由于问题规模较大多样性较强,以及每个图片的解释来源有限,不能保证每个Q&A的问答都得到很好的解释。这里将相似度较低的得分(阈值小于0.6)删除了,如下图所示:

(2)数据集分析(Dataset Analysis)
原始的VQAv2数据集中有658111个问答对,经过相似性过滤后剩下269786个QA对(41%),更多的数据统计信息表如表1所示:

合成问题类型解释数量的分布:

抽象问题和具体问题(Abstract questions v.s. Specific questions)很明显,‘is/are’ 和 ‘what问题类型占比更多。
主观问题:你能否......?(Subjective questions: Do you/Can you/Do/Could?):现存的VQA数据集中,涉及一些需要主观感受、逻辑思维或推理的一些问题,这些问题通常以‘do you’, ‘can you’, ‘do’, ‘could’,d等开头,这些都是一些隐含潜在的线索,通常很难生成一个好的解释,这些问题比例分别为4%、5%、13%和6%,远低于41%的平均水平,图5举例说明了这些问题。

(3)数据集评估(Dataset Assessment – User Study)
很难用定量的指标评估综合解释是否有效,作者从用户学习(user study)角度研究VQA-E数据集,具体从流利性、正确性、相关性、互补性四个方面来衡量解释质量。
流利性(Fluent)评估语法用词的的流畅性。正确性(correct)衡量对图像内容的解释是否正确。相关性(relevant)评估解释和答案之间是否相关。互补性(complementary)解释是否能成为答案的补充。
评估结果总汇(Evaluation results summary)评估结果如表2所示,人工标注的综合解释中,流利性和正确性的得分均接近于5,相关性和补充性得分都大于4。

3.多任务VQA-E模型(Multi-task VQA-E Model)
模型如图6所示,给定一个图像I和一个问题Q,文中提出的模型可以同时预测出答案a并生成文本解释E。
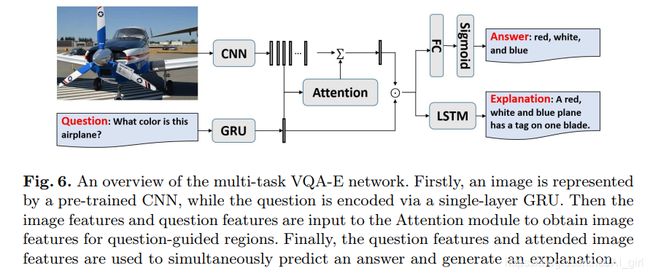
(1)图像特征(Image Features)
利用预先训练好的卷积神经网络(CNN)提取输入图像I的高级表示φ:
φ = CNN(I) = {v1, ..., vP }其中vi为第i个图像patch的特征向量,P为patch的总数。作者用CNN提取三种图像特征。
全局(Global)提取ResNet-152最终池化层,作为全局特征。
网格(Grid)将图像分成7*7的网格,提取ResNet-152的最后一层作为图像的feature map。
自下而上(Bottom-up)利用Faster R-CNN来提出显著区域,然后再联合ResNet-101的特征向量,P取36,相当于取了36个特征向量。
(2)问题嵌入(Question Embedding)
将问题Q标记后,编码为单词嵌入Wq = {w1, ..., wTq},然后将单词嵌入到门控循环单元(gated recurrent unit ):q = GRU(Wq),问题的表示为最终状态的RGU。
(3)视觉注意力(Visual Attention)
作者使用了一个question-guided soft attentionj机制,对于图像中的每一个patch,首先,将特征向量和问题嵌入投影到同一纬度下的非线性层,然后对投影后的两个特征向量进行(Hadamard)点乘,再输入到一个线性层中 ,得到一个与图像patch相关的注意力权重。用softmax归一化注意力权重τ上的所有patch。最后,将所有归一化的注意力权重值进行加权,累加到一个向量v上,作为最终的图像表示

接下来,将问题q和图像v投影到同一维度下的非线性层,然后进行(Hadamard)点乘融合。
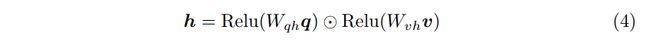
h是问题和图像的联合表示,然后输入到后续模块进行答案预测和解释生成。
(4)答案预测(Answer Prediction)
其实答案预测是一个多标签回归问题,并不是单标签分类问题。从训练集中出现8次以上的全部正确答案中选出一组候选答案,共有3129个候选答案,每个问题都有10个人工标注的答案,尤其是一些主观性问题往往有多个正确答案,充分考虑了注释者之间的分歧,采用软精度作为回归目标。每个答案的精度计算如下:

将联合表示h输入到非线性层,然后通过线性映射来预测每个答案的得分:
![]()
利用sigmoid函数,将所有候选的答案都压缩到[0,1]之间,损失函数类似于二元交叉熵损失:

最后一步可是看作是一个回归,预测每个答案的正确性。
(5)解释生成(Explanation Generation)
利用LSTM模型生成解释,将联合表示h作为输入:

将VQA和VQE损失总和作为多任务学习的最终损失:
![]()
4、实验和结果(Experiments and Result)
(1)实验设置(Experiment Setup)
模型设置(Model setting)词嵌入维度为300,GRU的hidden size为1024,LSTM的hidden size为1024,学习率0.01,batch size为512,还使用了权值正则化来加速训练。Dropout和 early stop (15 epochs)减少过拟合。
模型变种:
– Q-E: 只用问题生成解释
– I-E: 只用图像生成解释
– QI-E: 用图像和问题生成解释
– QI-A: 用图像和问题预测答案
– QI-AE: 用图像和问题来预测答案和生成解释
– QI-AE(relevant): 与QI-AE类似,只不过这里的解释用的是合成相关解释。
– QI-AE(random): 与QI-AE类似,只不过这里的解释是对描述进行随机采样。
(2)解释和生成评估(Evaluation of Explanation Generation)
直接看图

(3)答案预测评价
直接看图:


(4)定量分析(Qualitative Analysis)
直接看图:

5、结论