Tensorflow 搭建自己的神经网络 (莫烦 Python 教程) 25-
卷积神经网络:
卷积就是特征提取 最后再给全连接层 减少参数个数
卷积核可以多个 卷积核每次移动都会收集一层数据 移动很多次遍历图片 就会叠加成很多层
一层卷积提取一种特征 为获取更多的特征集合 卷积层会有多个卷积核 生成不同特征 这也是为什么卷积后图像变深
每个卷积核卷积得到一张特征图,加起来就厚了
每个过滤器提取一种特征 比如边缘
卷积过程不压缩长款的话 要用pading
高度增加因为过滤器不止一个 如果3个过滤器(RGB) 就相当于9层厚度的图像了 =>厚度就是特征=>高是过滤器的个数
池化处理:就是在卷积层后的进一步特征提取,可以减少下一层数据处理量 常见的池化包括MAX pooling 和mean pooling
pooling有降维效果 只要作用是为了得到特征 ,是选取更加有用的特征(maxpooling强调特征 average强调背景),减小数据量,而随着网络的加深,维度只会增加增加不为下降(可以看到层的厚度越来越厚)
pooling出的长宽会变 高度不会变 阿尔法go用的补0
patch/kernel=filter
这里莫凡可能讲错了,16个厚度吧 通过组合形成的
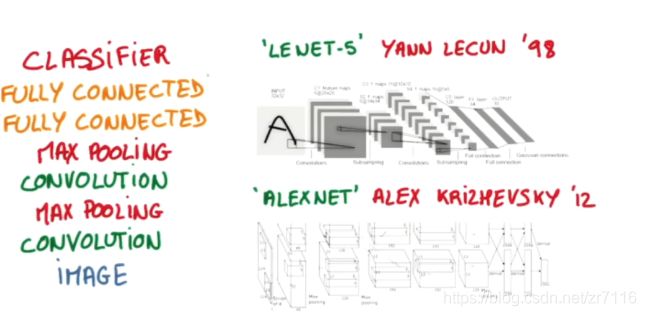
左侧input图片是灰度图32*32像素,深度是1, 经过第一个卷积层后变成28*28的feature map,深度为6
16个厚度吧 通过组合形成的
这说明第一个卷积层有6个卷积核,大小为5*5
接着经过池化层,featuremap大小变为 14*14 深度为6
接着经过第二个卷积层, 第二个卷积层的有16个卷积核,且大小为5*5,因此得到了10*10 深度为16的featuremap然后经过第二个池化层, featuremap变为大小5*5 深度为16 后面就是两个全连接层
变厚是因为有多个filter去扫
filter越多厚度就越大 变厚是因为卷积核变多了 变厚是卷积核数量的叠加,因为对图像分类不可能只有一个特征进行分类
o
跨度大会导致图片信息减少==》步长减少 加pooling 效果会好==》如下图=》图片长宽不是conv2D时候变小 ==》在polling时变小
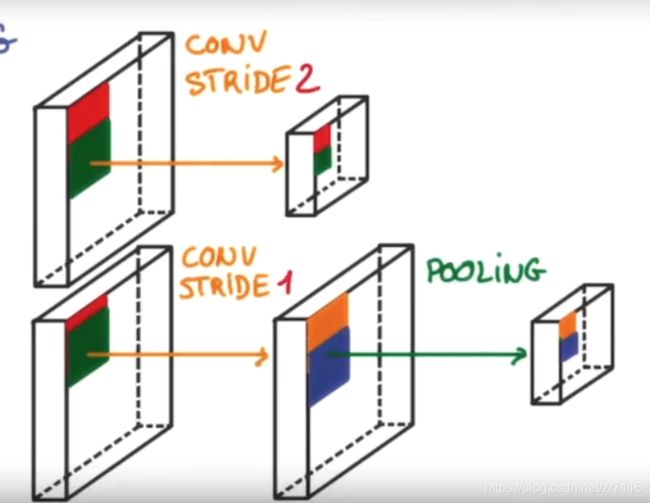
ksize 池化窗口的大小 是一个四位向量 一般为【1,height,width,1】 因为我们不想在batch和channels上做操作,所以这两个维度上设为1
解决问题了...传入的W就包含了卷积核的个数信息
卷积核在W的最后一位定义的
这里没问题,VALID就是让卷积核使用保守原则,超过卷积核框架的边缘就丢弃,因此比较小了
输入的厚度是原图片的厚度,输出的厚度就是多少个卷积核
P填充数量
W是四位向量,W[3]就是卷积核的个数
ksize 为池化窗口大小
我用他的上一个算法跑出一个92%,不过做了修改:增加了一层神经层;中间输出数改为40;迭代训练次数改成10000
常见的是[1221]或p[1331],X=【batchsize,高,宽,通道数】
2w次 两层卷积池化 两层全连接 准确率99.3%
卷积核就是一个多维的“权重”窗口,卷积核数量即卷积后的“厚度”
五层dense层能99.9
原始尺寸是4*4的,分成四个2*2矩阵,MaxPooling保存每个2*2矩阵的最大特征值,组成一个新的2*2矩阵,AveragePoolong保存的是平均值,常用Max,因为Max更好地保存了特征
con卷积层就是用过滤器对原始矩阵过滤,
而batch_size是决定了一次训练取多少张图片

神经网络是通过增加图片厚度来总结图片特征的
定义了大小,stride,padding之后会自动算出一个对应的
32就是卷积核个数 [5 5 1]是卷积核尺寸 1个卷积核生成一层feature map
same 方式不变的是长宽比不是长宽, 长宽不变是因为上面 stride 设置的两个方向步长都是1
32 是卷积核数量,有多少个结果就有多高
32=28+5-1,是这么算的吧
padding = 'SAME' 时,输出并不一定和原图size一致
但会保证覆盖原图所有像素,不会舍弃边上的莫些元素
不管前面怎么说,我都始终觉得,32是2的5次方
32是随你写的。你开心写几就是几
瞬间明白了,是padding为same,每张图片受到5x5的卷积核卷积还是得到28x28的像素位,一共32个叠加到一起,生成28x28x32的输出结果
32就是卷积核的个数,一个卷积核卷积出一张图片,32个卷积核卷积出的厚度就是32
32不是算的,随便设都可以
每个卷积核的厚度都应该等于被卷积物体的厚度呀
32真的是自己设定的 ,是卷积核的个数,32个卷积核跟输入做卷积产生32个新的输出,叠加起来厚度就是32了
感觉特征抽象到到weight里面了 卷积的目的是提取很多特征
这里输入是偶数,所以same和valid输出应该是一样的。池化层的padding应该指的是维度不够下一个步长的时候是否要填充
1024是人为设置的隐藏层维度
整个网络结构就是输入,卷积,池化,卷积,池化,全连接,输出
输出图像的h或w=[(输入图像的h或w+2*padding-卷积核的个数)/stride]+1
特征在maxpool就提了,2x2选一个特征大的保留
【5,5,1,32】这里1是指本层输入的通道数,不是输出的维度
卷积的目的是提取很多特征
CNN层数降低,或者batch降低可是跑的快一些
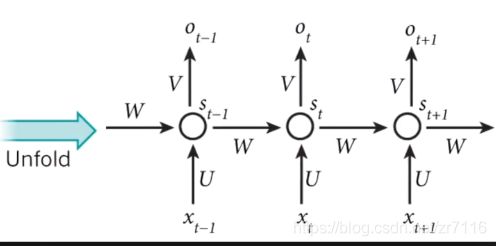
RNN=》应用场景 针对数据关系是 有序列性 顺序性 (前面数据对后面数据有影响 有助于问题处理)
有些像数学之美中提到的马尔科夫模型
1-n 输入一张图像生成文字
n-1一句话判断感情
n-n翻译
RNN描述照片 RNN生成学术论文
LSTM ==》流行的RNN之一
RNN会有梯度消失/梯度弥散 的问题 一个误差往回传的时候 不断*每一步的权重 传到最后可能为0
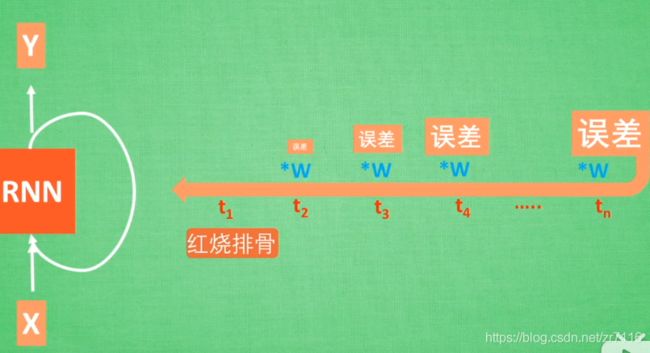
反之:会有梯度爆炸情况 ==》 如果w>1 往回传的过程中 RNN就被撑死了
如果用relu是不是就不会梯度消失了?
是的 relu能解决梯度消失与梯度爆炸

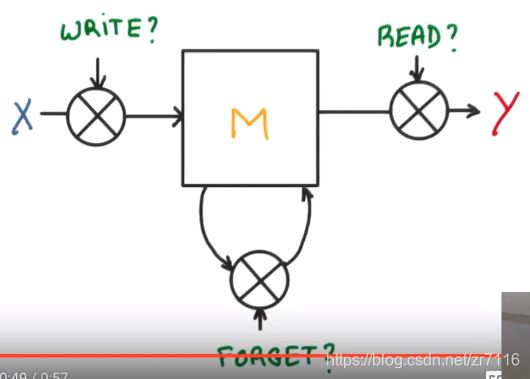
输入门对应up的write门,用于对当前的输入x以及上一个单元的输入ht-1进行控制,提取重要的信息
遗忘门用于对细胞状态进行更细,舍去不想要的内容部分
输出门用于更新结果,包括细胞状态以及输出向下一层的隐藏状态
up这里的意思可以理解为支线剧情的结果是否会对主线的结果产生影响,是happy end还是bad end
本身就是马尔可夫链吧
BGM回归
股票预测所用到的时间序列模型有的已经很成熟了,但也存在较大的风险,毕竟概率低的事情不是零概率
如果分线达到一定的重要程度==》写入主线在进行分析
如果分线改变了对之前的想法==》忘记控制就会将之前的主线剧情忘记==》按比例替换成现在的新剧情
所以主线的更新取决于 输入和忘记控制
输出基于分线和目前的主线到底是什么
即 : t时刻的输出 由当前输入和t-1的状态决定 新的输入加上以前的记忆 官方翻译是输入门,输出门,遗忘门

循环次数有自己设定,设定一个合适的值,如果太大,则可能会过拟合,学习到了这批数据的细节,而不是数据的共性,太小则可能学习不够,也就是欠拟合。
batch_size这个是之前说过的SGD方法
也可以使模型自身设定,如果当代价函数下降不多的时候(小于给定值),就停止迭代。
数据不能直接全放进去,要分成多个batch,每个batch里含有的样本数就是batch size
这里用的是SGD的方法,每次训练只使用mnist中128个数据
tf.nn.dynamic_rnn()优点在于对尺度不相同的数据的处理上,会减少计算量
tensorflow1.0之后tf.pack和tf.unpack没有了,被tf.stack和tf.unstack代替,效果不变,可直接替换使用
我觉得这样理解,共28个时间点(step),state[1]为最后一个时间点的输出。output含所以28个时间点的输出。所以unpack后主维度为28个step,只选择最后一个
transpose是进行三维张量转置,102代表第一第二维度交换
BasicLstmCell内置方法中call函数的形式是(output1,h1)= cell.call(output0,h0),h指cell的状态,output指cell的输出
在BasicRNNCell中二者完全相同,在LSTMCell中,若state_is_tuple =True,outputs是state的一部分,也就是主线h的那部分
dymatic_rnn可以理解为cell在时间维度上的展开,返回的state是最后一个cell的state,size是([batchsize,cell.h],[batchsize,cell.c])
outputs是timestep步里所有的输出,size是(batchsize,timestep,cell.h)
outputs 被 unpack 之后,变成一列数值或者向量,列数等于steps的值即cell的数量,对应到这幅图当中,就时A的数量,而每一列的值就对应每个A的输出
lstm激活函数默认tanh
我前面写反了state的size应该是([batchsize,cell.c],[batchsize,cell.h])这里的state[1]就是[batchsize,cell.h]
最后并不是停在最高的准确率
过拟合,了解一下
我跑的结果,RNN在每一次打印的准确度会有波动,但总体是在上升的,基本上可以达到0.97以上
![]()
例如矩阵a(m,n,w), m是行,n是列,w是页。
